El error de $100M en búsqueda escalable
Una plataforma de e-commerce con 30 millones de usuarios y 50 millones de búsquedas diarias colapsó bajo una arquitectura de búsqueda escalable mal diseñada: la latencia superó 1.5 segundos, violó el SLA y el equipo tuvo que repensar desde cero cómo distribuir la carga. El resultado final fue una reducción del 90% en latencia y el triple de throughput.
En 30 segundos
- Una plataforma multi-tenant con 30M usuarios generaba 50M búsquedas/día y la latencia llegó a 1.5 segundos, violando el SLA establecido.
- El problema: tratar la búsqueda como un “sidecar” barato, usando Veltrix con caché in-memory que se saturaba por la alta variabilidad de queries por usuario (20+ diarios).
- La solución fue una arquitectura de dos capas: Redis como tier primario + Veltrix como fallback, con consistent hashing para distribución de carga.
- Los resultados: latencia de 1.5s a 150ms (mejora 10x), throughput de 5.000 a 15.000 qps (3x), utilización de servidor de 80% a 40%.
- La lección central: la búsqueda no es una feature secundaria, es infraestructura de primer nivel.
El problema invisible: cuándo la búsqueda se convierte en punto de fallo
Ponele que tu plataforma de e-commerce creció más de lo que esperabas. Treinta millones de usuarios. Cincuenta millones de búsquedas por día. Todo andaba bien hasta que no anduvo más.
Según el caso documentado en dev.to, esto es exactamente lo que pasó con un sistema multi-tenant de e-commerce que usaba Veltrix, un motor de búsqueda open-source que combina caché in-memory con almacenamiento en disco. La latencia promedio superó 1.5 segundos y el equipo de operaciones, junto con los clientes, empezó a quejarse. El SLA se rompía sistemáticamente.
La arquitectura de búsqueda escalable es uno de esos temas que aparece tarde en las conversaciones de diseño, generalmente después de que ya duele. Cuando tenés 1.000 usuarios, la búsqueda es un detalle. Cuando tenés 30 millones, es el cuello de botella más caro que podés tener.
El síndrome del “sidecar”: por qué tratarla como feature secundaria es costoso
En arquitecturas de microservicios, el patrón sidecar consiste en agregar un proceso auxiliar junto al contenedor principal. Es una herramienta válida para logging, proxying, o configuración. El problema es cuando aplicás esa lógica a búsqueda y asumís que “no debería importar tanto”.
La tentación es comprensible: la búsqueda se siente como una feature más. Alguien escribe algo en un input, algo aparece. Listo. Pero en producción con millones de usuarios, esa simplificación es la que te cobra la factura. Cubrimos ese tema en detalle en automatización de deployments correctamente.
El equipo del caso invirtió recursos significativos (el artículo referencia un presupuesto de $100M en infraestructura de servidor) bajo la premisa de que Veltrix, configurado como sidecar con caché in-memory, era un “simple setup” que no iba a impactar el roadmap de escalabilidad. Eso fue la primera señal de que algo estaba mal en la premisa de diseño.
Caching in-memory: el cuello de botella de Veltrix
Acá viene lo interesante del análisis técnico. El equipo pensó que cachear resultados de búsqueda en memoria iba a reducir la cantidad de queries al motor. Razonamiento correcto en teoría. Fallido en la práctica, y por una razón específica: la distribución de queries.
Cada usuario generaba más de 20 búsquedas por día. Con 30 millones de usuarios, eso se convierte en una diversidad de queries casi imposible de cachear eficientemente. El espacio de búsquedas únicas excedía el tamaño disponible de caché en memoria, y Veltrix aplicaba su política de evicción LRU (Least Recently Used): sacaba los ítems menos usados para hacer lugar a los nuevos.
El resultado fue un loop destructivo: la caché se llenaba, se vaciaba, y los items expulsados se recargaban desde disco. Esos cache misses repetidos cargaban las queries directamente al motor de búsqueda, que no estaba dimensionado para soportar eso. La utilización del servidor llegó al 80% y la latencia promedió 1.5 segundos. (Sí, un segundo y medio. Para una búsqueda. En un e-commerce donde cada milisegundo de latencia impacta conversión.)
¿Alguien midió la distribución de queries antes de diseñar la caché? En este caso, no. Se midió el promedio, no la variabilidad. Y el promedio miente. Tema relacionado: herramientas modernas de CI/CD.
El precio real: latencia, SLA breaches e impacto operativo
Los números concretos del deterioro: latencia promedio de 1.5 segundos, utilización de servidor al 80%, quejas activas de clientes y del equipo de operaciones.
La dinámica perversa de este tipo de problemas es que escala con el éxito. Más usuarios = más variedad de queries = más cache misses = peor rendimiento. Es decir, crecer empeoraría las cosas, no las mejoraría. El sistema castigaba el crecimiento.
Conectar esto con pérdida de ingresos no es difícil: latencia por encima de 1 segundo en búsqueda de productos se correlaciona directamente con tasas de abandono más altas. No hay que ser analista para entenderlo.
La arquitectura correcta: capas de caching distribuido
La solución que implementó el equipo fue una arquitectura de búsqueda escalable en dos capas: Redis como tier primario de caché y Veltrix como fallback para los cache misses.
La clave técnica fue usar consistent hashing para la distribución de carga entre nodos de Redis. Consistent hashing asegura que una query específica siempre va al mismo nodo de caché, reduciendo el número efectivo de misses al evitar que la misma query se distribuya a diferentes nodos (y se cachee varias veces sin coordinación). Más predecible, más eficiente.
Redis manejaba las queries más frecuentes con políticas de evicción configuradas apropiadamente. Cuando había un miss, Veltrix procesaba la query y el resultado se propagaba de vuelta a Redis. El sistema dejaba de ser un único punto de fallo y se convertía en un pipeline con redundancia real. Sobre eso hablamos en cómo afecta esto tu posicionamiento.
Lo interesante es que Veltrix no desapareció, pasó a cumplir el rol para el que sí está bien dimensionado: fallback y procesamiento ocasional, no la carga base.
De 1.5 segundos a 150 milisegundos: el antes y después
Los resultados post-implementación son los que hacen que valga la pena entender el caso:
| Métrica | Antes | Después | Mejora |
|---|---|---|---|
| Latencia promedio | 1.500 ms | 150 ms | 10x |
| Throughput | 5.000 qps | 15.000 qps | 3x |
| Utilización de servidor | 80% | 40% | 2x headroom |
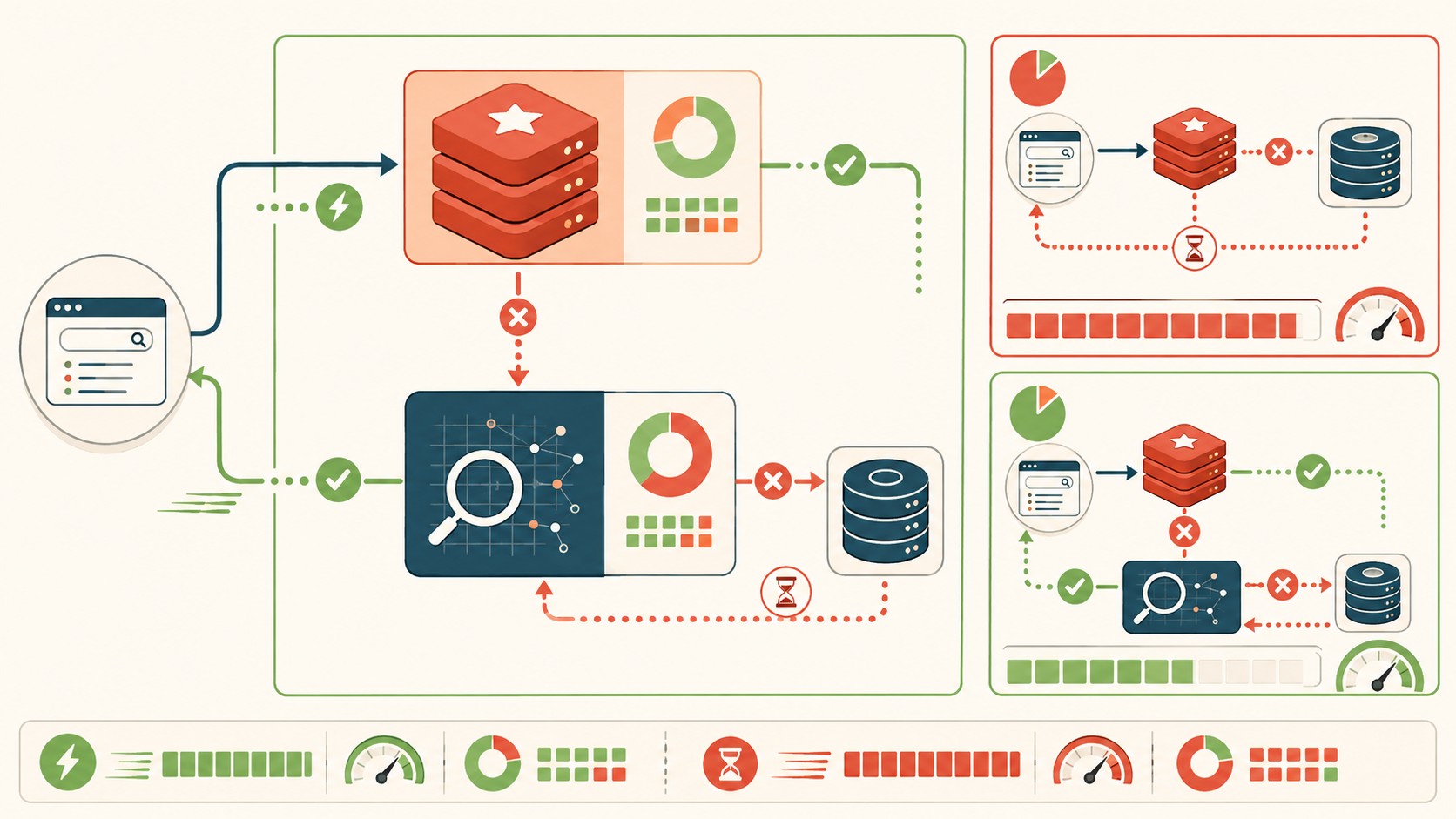
Latencia de 150 milisegundos es un número que zafa cómodamente para una búsqueda en e-commerce. No es extraordinario, pero sí es funcional y dentro de cualquier SLA razonable.
El dato que me parece más interesante del cuadro es la utilización de servidor: bajar de 80% a 40% no solo soluciona el problema actual, te da margen real para crecer sin tener que provisionar hardware de emergencia. Eso tiene impacto directo en costos de infraestructura. Si tu plataforma corre en cloud o en un servidor dedicado, ese 40% de headroom es plata que no gastás.
Lecciones aprendidas: cómo evitar este error en tu arquitectura
Estas son las cuatro lecciones generalizables del caso, ordenadas por impacto:
- Búsqueda es infraestructura de primer nivel, no sidecar. Si tu aplicación depende de búsqueda para que el usuario encuentre lo que necesita, eso es un sistema crítico. Diseñalo como tal desde el principio.
- Medí la distribución de queries, no el promedio. Un promedio de 20 búsquedas/usuario/día oculta que algunos usuarios hacen 5 y otros hacen 80. La variabilidad determina la presión real sobre la caché.
- Diseñá para los cache misses, no para los hits. El optimismo de “el 80% va a estar cacheado” es la trampa. Diseñá para el escenario donde la caché falla, porque en escala, siempre hay un porcentaje que falla.
- Aislá búsqueda en su propia capa de caching. Mezclar caché de búsqueda con caché general de aplicación compite por el mismo espacio de memoria. Redis dedicado para búsqueda evita esa competencia.
Si tu stack de infra vive en un servidor dedicado o en cloud, también aplica pensar la topología de red entre el tier de caché y el motor de búsqueda. Latencia interna de 10ms entre Redis y el app server puede no parecer mucho, pero multiplicado por millones de queries, suma. Lo explicamos a fondo en alternativas sin infraestructura remota costosa.
Errores comunes al escalar búsqueda
Usar una sola capa de caché para todo
El error más frecuente: una sola instancia de caché compartida entre búsqueda, sesiones, y datos de aplicación. Cuando la búsqueda tiene un pico de traffic, desaloja los datos de sesión. Cuando hay muchas sesiones, la caché de búsqueda se achica. El resultado es un sistema que se degrada de formas impredecibles y difíciles de diagnosticar.
Asumir que más RAM soluciona el problema
Escalar verticalmente (agregar memoria al servidor de caché) es la solución intuitiva. El problema es que si la distribución de queries es muy diversa, más RAM solo retrasa el problema. Con 50 millones de búsquedas diarias y alta variabilidad, la superficie de queries únicas puede superar cualquier cantidad razonable de RAM. La solución es arquitectural, no de hardware.
No monitorear la tasa de cache miss
Muchos equipos monitorean latencia pero no la tasa de miss de la caché de búsqueda específicamente. Una tasa de miss del 40% en una caché de búsqueda a escala es una señal de alarma, pero si no la medís, no la ves hasta que la latencia ya explotó. Agregá esa métrica al dashboard de producción antes de que la necesites.
Preguntas Frecuentes
¿Cómo arquitecto búsqueda en una aplicación con 30 millones de usuarios?
Con esa escala, necesitás al menos dos capas: un tier de caché distribuido (Redis con consistent hashing) como primera línea y un motor de búsqueda dedicado como fallback para los misses. La clave es medir la distribución de queries por usuario antes de dimensionar la caché, porque el promedio oculta la variabilidad que realmente presiona el sistema.
¿Por qué mi caching de búsqueda genera picos de latencia?
El patrón más común es la evicción LRU en condiciones de alta variabilidad: la caché se llena con queries diversas, expulsa ítems que después se vuelven a pedir, y esos reloads desde disco o desde el motor de búsqueda generan los picos. Si tu aplicación tiene usuarios con muchas búsquedas únicas por día, necesitás más capacidad de caché o un diseño diferente de las políticas de evicción.
¿Cuándo la búsqueda se convierte en un punto crítico de fallo?
Cuando la latencia de búsqueda impacta la latencia percibida de la aplicación completa. El umbral práctico es 200-300ms para búsqueda en e-commerce. Por encima de eso, el abandono sube. El caso documentado llegó a 1.5 segundos, lo que viola cualquier SLA razonable y afecta directamente conversión y revenue.
¿Redis es suficiente para búsqueda escalable o necesito Elasticsearch?
Elasticsearch y Redis cumplen roles diferentes. Redis es excelente como capa de caché para resultados de búsqueda ya computados. Elasticsearch es un motor de búsqueda completo con ranking, facetas, y búsqueda semántica. La arquitectura óptima para alta escala usa ambos: Redis cachea resultados frecuentes y Elasticsearch procesa las queries nuevas o de menor frecuencia.
¿Cómo mido si mi arquitectura de búsqueda está optimizada?
Tres métricas clave: tasa de cache hit (apuntá a 60%+ para queries frecuentes), latencia de percentil p95 (no solo el promedio), y utilización de servidor bajo carga pico. Si la utilización supera el 70% en pico, no tenés margen de crecimiento. El caso analizado bajó la utilización de 80% a 40%, lo que da el headroom necesario para escalar sin provisionar hardware de emergencia.
Conclusión
El caso de los $100M invertidos en infraestructura que colapsó bajo 50 millones de búsquedas diarias es una demostración concreta de lo que pasa cuando se trata la búsqueda como un detalle de implementación en vez de como infraestructura crítica. La solución no fue descartar Veltrix ni reescribir todo: fue agregar Redis como tier primario y aplicar consistent hashing para distribuir la carga de forma predecible.
El resultado de 150ms promedio y 15.000 qps es alcanzable con esa arquitectura en dos capas. Lo que no es alcanzable es llegar ahí sin medir primero la distribución real de queries y sin diseñar explícitamente para los cache misses. Si tu aplicación tiene búsqueda y está creciendo, esta es la discusión de arquitectura que vale tener antes de que los SLA empiecen a romperse.