Monitoreo Kubernetes con OpenTelemetry: Agent + Gateway
El patrón Agent + Gateway de OpenTelemetry resuelve el problema silencioso más caro del monitoreo Kubernetes con OpenTelemetry Collector: en vez de que cada pod abra una conexión gRPC directa contra tu backend de trazas, un Collector por nodo (DaemonSet) junta la telemetría local y la manda a un Gateway central que la agrupa, muestrea y exporta. Según el análisis técnico publicado el 1 de julio de 2026, así dejás de perder spans por límite de conexiones concurrentes.
OpenTelemetry Collector es un binario intermediario que recibe, procesa y exporta trazas, métricas y logs sin atarte a un backend específico. En Kubernetes se despliega en dos capas: el Agent corre como DaemonSet (una instancia por nodo) y recibe OTLP local de los pods; el Gateway corre como Deployment centralizado y hace el trabajo pesado de batching y muestreo antes de escribir en Tempo, Loki o Prometheus.
En 30 segundos
- El problema real: el backend no se cae por CPU, se cae porque agota su límite de conexiones concurrentes gRPC y empieza a devolver RESOURCE_EXHAUSTED.
- La cuenta que asusta: un cluster de 20 nodos con tres tipos de señal (métricas, trazas y logs) llega al menos a 60 conexiones persistentes contra un endpoint dimensionado para una fracción de eso.
- La solución: Agent (DaemonSet) para colectar local, Gateway (Deployment) para agrupar, muestrear y exportar.
- El threshold: cuanto más crece el cluster, más duele el fan-out; con pocos nodos el envío directo todavía zafa, y a partir de cierta escala conviene el Gateway.
- El detalle que quema: el processor memory_limiter va SIEMPRE primero, o te comés un OOMKill en el peor momento.
¿Por qué las conexiones gRPC directas fallan sin avisar?
Ponele que tenés cada pod exportando OTLP directo al endpoint de ingest de Tempo. Con cinco nodos y un puñado de pods, esto es invisible. Anda todo bien y nadie se hace preguntas.
El tema es que las conexiones gRPC no son gratis. Cada una mantiene estado, negocia keepalives y ocupa un file descriptor. Cuando escalás a veinte nodos con workloads que autoescalan, de golpe estás abriendo cientos de conexiones persistentes contra un servicio que fue dimensionado para una fracción de eso.
¿Y qué pasa cuando el backend llega a su tope? No degrada de a poco. Empieza a rechazar conexiones con RESOURCE_EXHAUSTED y tus trazas desaparecen en silencio. Lo peor es el diagnóstico: mirás el dashboard del backend, ves la CPU al 30% y pensás que el problema está en otro lado, cuando en realidad chocaste contra el límite de conexiones concurrentes. Complementá con despliegues automatizados en producción.
¿Cómo funciona la arquitectura Agent + Gateway?
La idea es meter una capa intermedia para que el fan-out de conexiones muera cerca del pod. El flujo queda así: el pod exporta a localhost, el Agent del nodo recibe ese OTLP, y el Agent mantiene una sola conexión (o unas pocas) contra el Gateway. El Gateway, a su vez, es el único que habla con el backend.
Cada capa tiene una responsabilidad clara. El Agent colecta y bufferea local. El Gateway reconstruye las trazas completas, aplica el muestreo y arma los lotes. Acá va la comparación:
| Aspecto | Agent (DaemonSet) | Gateway (Deployment) |
|---|---|---|
| Dónde corre | Uno por nodo | Réplicas centralizadas |
| Recibe de | Pods vía OTLP localhost (4317) | Todos los Agents |
| Memoria típica | Acotada (comparte nodo con los workloads) | Alta (buffering y colas) |
| Procesamiento | memory_limiter, k8sattributes, batch | tail sampling, batch pesado |
| Exporta a | Gateway (otel-gateway:4317) | Tempo, Loki, Prometheus |
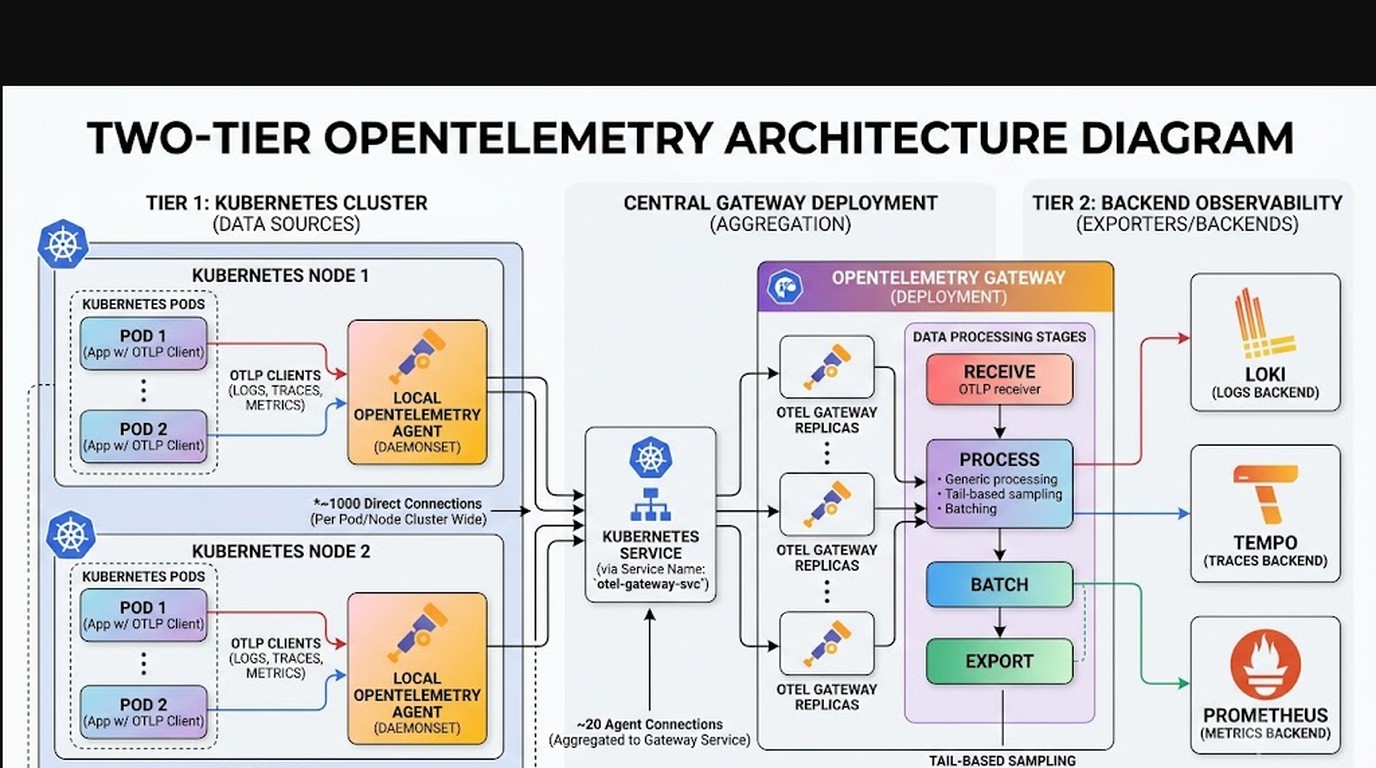
¿Qué configuración necesita el Agent como DaemonSet?
El Agent es liviano a propósito. Necesita RBAC para leer metadata de Kubernetes (así enriquece los spans con nombre de pod, namespace y demás) y un límite de memoria acotado, porque hay uno corriendo en cada nodo.
- Receivers: OTLP en el puerto 4317 para las apps locales, kubeletstats para métricas del nodo y filelog para los logs de pods.
- Processors, en este orden: memory_limiter primero (no negociable), después el de atributos de Kubernetes, y batch al final.
- Exporter: apuntá al Gateway por service name, del estilo
otel-gateway:4317, no al backend.
La clave del dimensionamiento: el Agent tiene que quedarse liviano, así que ponele un límite de memoria acotado y no más. La RAM que le sobra es RAM que tus workloads podrían usar. Ya lo cubrimos antes en herramientas de despliegue continuo.
¿Cómo configurar el Gateway para batching y tail sampling?
Acá vive la lógica cara. El Gateway recibe OTLP de todos los Agents y ahí aplicás el muestreo tail-based, que decide qué trazas guardar mirando la traza completa (por ejemplo, quedarte con todas las que tienen error o latencia alta).
- memory_limiter: con headroom de memoria proporcional al volumen que bufferea, otra vez como primer processor del pipeline.
- tail sampling: políticas basadas en atributos del span. Si corrés varias réplicas, necesitás routing por trace ID, porque si los spans de una misma traza caen en réplicas distintas, el muestreo se rompe.
- batch: agrupá por tamaño o por tiempo, lo que llegue primero.
El detalle del trace-ID routing es el que más gente pasa por alto. Subís la segunda réplica del Gateway pensando que ganás resiliencia, y de repente el muestreo empieza a devolver trazas cortadas porque la mitad de los spans se fue a la otra réplica. (Sí, pasa, y cuesta un rato entender por qué.)
Los 3 comportamientos que te van a quemar en producción
1. El memory_limiter mal ubicado
Si el memory_limiter no es el primer processor, el Collector acumula datos ANTES de rechazarlos. Resultado: se llena la memoria y llega el OOMKill justo en el pico de tráfico, que es cuando más lo necesitás. Ponelo primero y listo.
2. El idle timeout de kube-proxy
kube-proxy cierra las conexiones TCP que quedan inactivas. Si tu tráfico tiene baches, la conexión gRPC del Agent al Gateway se muere entre lote y lote y el próximo envío falla. La cura es configurar keepalive explícito en el exporter gRPC. Para más detalles técnicos, mirá documentación técnica multinacional.
3. El file storage del tail sampling
El almacenamiento en disco que usa el tail sampling para retener trazas mientras decide crece sin freno en los picos de tráfico. Si no le ponés un tamaño máximo explícito, llenás el volumen y el Gateway deja de funcionar. Configurá el límite antes de que te pase.
¿Cómo validar que el pipeline anda de verdad?
El Collector expone sus propias métricas, y con tres alcanza para saber si estás perdiendo datos:
- otelcol_receiver_accepted_spans: cuántos spans entraron. Si cae a cero, algo aguas arriba dejó de mandar.
- otelcol_exporter_send_failed_metric_points: los envíos que fallaron. Si sube, el backend te está rechazando.
- otelcol_exporter_queue_size vs queue_capacity: la diferencia entre las dos te dice si el problema es latencia del backend o un pico de tráfico puntual.
La prueba práctica: generá trazas de test, confirmá que el Gateway las recibe completas y verificá que las políticas de tail sampling se aplicaron. Si una traza con error no aparece cuando tu política dice “guardar todos los errores”, el routing por trace ID es lo primero que tenés que revisar.
¿Desde cuántos nodos conviene el patrón?
No todos los clusters lo necesitan. La regla práctica coincide con lo que se ve en producción: cuanto más crece el cluster, antes conviene el Gateway. Tema relacionado: ejecutar agentes sin depender de APIs.
- Clusters grandes o con autoescalado: implementá el Gateway. El fan-out de conexiones ya duele.
- Clusters chicos: el envío directo al backend todavía es aceptable.
- Un cluster mínimo: no armes esta estructura, es sobreingeniería.
Hay un enfoque híbrido que vale la pena: mandá las métricas direct-to-backend (son livianas) y las trazas vía Gateway (son las que necesitan tail sampling centralizado). Así pagás la complejidad solo donde rinde. Si estás corriendo estos clusters sobre infraestructura administrada, un hosting cloud como donweb.com te saca de encima el mantenimiento del nodo para que te enfoques en el pipeline.
Qué está confirmado y qué no
- Confirmado: el modo de falla por límite de conexiones concurrentes gRPC (no por CPU) está documentado en el docs oficial de OpenTelemetry sobre agent-to-gateway.
- Confirmado: el requisito de routing por trace ID para tail sampling con múltiples réplicas es parte del diseño del componente, no un workaround.
- Depende de tu setup: el dimensionamiento exacto (memoria del Agent, memoria del Gateway, a partir de cuántos nodos montar el patrón) son puntos de partida razonables, no leyes. Medí tu volumen de spans por minuto y ajustá.
Errores comunes
- Culpar a la CPU del backend: ves el ingest rechazando datos y escalás CPU. No sirve. El cuello de botella son las conexiones concurrentes, no el cómputo.
- Meter tail sampling en el Agent: el Agent no ve la traza completa, solo los spans de su nodo. El muestreo tail-based va en el Gateway, sí o sí.
- Subir réplicas del Gateway sin trace-ID routing: ganás disponibilidad y perdés coherencia en el muestreo. Configurá el routing antes de escalar.
- Olvidarte del keepalive: todo anda en la demo y en producción se corta cuando la conexión queda inactiva. El idle timeout de kube-proxy no perdona.
Preguntas Frecuentes
¿Cuál es la diferencia entre DaemonSet y Gateway en OpenTelemetry Collector?
El DaemonSet (Agent) corre una instancia por nodo y colecta telemetría local de los pods vía OTLP en localhost. El Gateway corre como Deployment centralizado con réplicas y hace el procesamiento pesado: reconstrucción de trazas, tail sampling y batching antes de exportar al backend.
¿Por qué mis conexiones gRPC agotan los límites del backend?
Porque cada pod abre una conexión gRPC persistente directa contra el ingest, y cada conexión ocupa un file descriptor y mantiene estado. Con 20 nodos y tres tipos de señal (métricas, trazas y logs) ya llegás al menos a 60 conexiones persistentes contra un endpoint dimensionado para una fracción de eso, y el backend responde RESOURCE_EXHAUSTED.
¿Qué processor debe ir primero en el pipeline?
El memory_limiter siempre va primero, tanto en el Agent como en el Gateway. Si va después de otro processor, el Collector acumula datos antes de rechazarlos y termina en OOMKill durante los picos de tráfico.
¿Necesito el patrón agent-gateway en un cluster chico?
En un cluster chico no hace falta: con pocos nodos el envío directo al backend todavía es aceptable. Recién cuando el cluster escala y el fan-out de conexiones empieza a doler, montar el Gateway centralizado se justifica.
¿Cómo evito que se corten las conexiones inactivas?
Configurá keepalive explícito en el exporter gRPC del Agent. kube-proxy cierra las conexiones TCP que quedan inactivas, así que sin keepalive el primer envío tras un bache de tráfico va a fallar.
Conclusión
El patrón Agent + Gateway no es un lujo de clusters gigantes: es la respuesta directa a un modo de falla que no se ve venir hasta que tus trazas desaparecen y el dashboard del backend te miente con la CPU tranquila. Si tu cluster ya escaló, armá el Gateway, poné el memory_limiter primero, configurá keepalive y, si escalás réplicas, no te olvides del routing por trace ID. Empezá midiendo otelcol_exporter_send_failed_metric_points: si ese número no es cero, ya sabés dónde mirar.