Canary deployments para sitios estáticos en 2026
Un canary deployment de precisión para contenido estático es una técnica de despliegue progresivo donde un pequeño porcentaje del tráfico real recibe la nueva versión del sitio, separando el tráfico en edge antes del cache lookup, con rollback instantáneo disponible en cada momento. Según el artículo técnico publicado en dev.to el 6 de mayo de 2026, esta estrategia resuelve el problema central de las migraciones frontend en producción: no el bug obvio, sino la combinación de estado del navegador, caché del CDN y sesiones activas que nadie pudo reproducir en staging.
En 30 segundos
- Las migraciones de frontend fallan en producción por la combinación de caché viejo, estado del navegador acumulado y sesiones en vuelo, no por bugs aislados.
- Un canary deployment de precisión arranca con un porcentaje mínimo de tráfico real y expande solo cuando los datos dicen que hay que hacerlo.
- El routing ocurre en edge, antes del cache lookup, para que el tráfico canary y el tráfico estable nunca se mezclen.
- No usa cookies: trabaja con claves de routing determinísticas y anónimas, con fallback automático cuando no hay clave disponible.
- El rollback es cambiar una decisión de edge, sin esperar que el DNS se estabilice.
Stability AI es una empresa de investigación en inteligencia artificial fundada por Emad Mostaque que desarrolla modelos generativos de código abierto, incluyendo Stable Diffusion para síntesis de imágenes.
¿Por qué fallan las migraciones de frontend en producción?
Ponele que tu equipo migró de una React SPA a un build estático de Next.js. Probaron todo en staging. Los tests pasaron. El diseño se ve bien. Lo mandan a producción y en los primeros treinta minutos empiezan los reportes: algunos usuarios ven la versión vieja, otros la nueva, algunos tienen el carrito roto, y el equipo de soporte no puede reproducir nada porque en sus máquinas todo anda.
Eso no es un bug. Es producción.
Los entornos de staging no tienen meses de estado real del navegador, assets cacheados en múltiples capas del CDN, sesiones a medio completar, ni cada combinación extraña de cliente que aparece en internet público. Un release “big bang” manda todo ese tráfico a la nueva versión al mismo tiempo, con cero oportunidad de observar qué pasa antes de que el daño sea masivo.
La “innovación” de hacer deploys más rápido no sirve de nada si el mecanismo de rollback tarda más que el incidente. Ahí es donde los canary deployments de contenido estático ganan su lugar.
Canary deployments de precisión: qué son y por qué importan
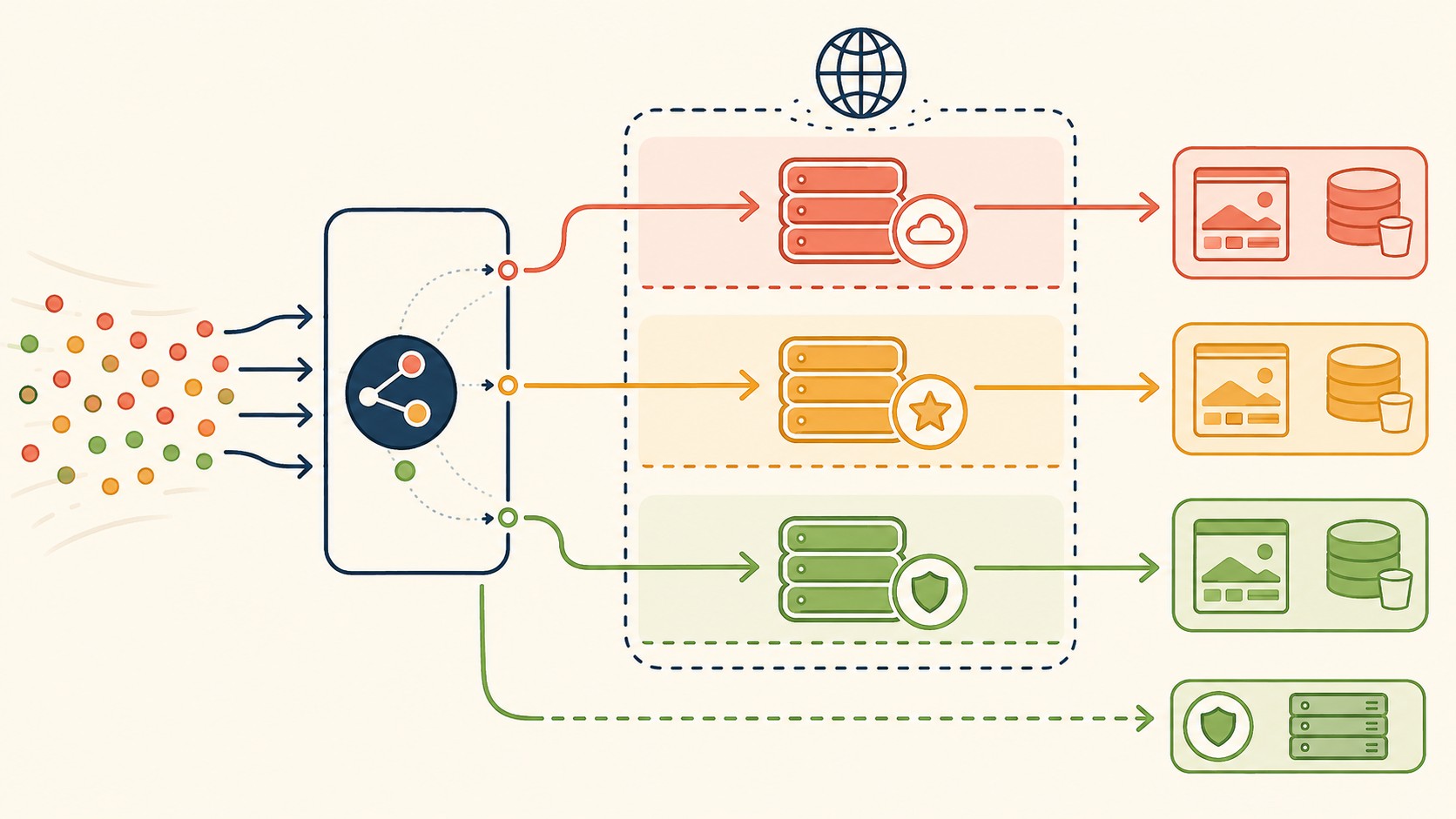
Un canary deployment es una estrategia donde una fracción pequeña del tráfico real recibe la nueva versión mientras el resto sigue con la versión estable. No es enviar el 50% y cruzar los dedos: es arrancar con el 1% o menos, observar bajo condiciones reales, y expandir solo cuando la evidencia lo justifica.
Para los ingenieros, reduce el blast radius: si algo se rompe, lo ven 1 de cada 100 usuarios, no todos. Para quienes aprueban los deploys, convierte un release de alto riesgo en un rollout controlado con una salida de emergencia disponible en todo momento. En mantener el SEO en migraciones multiidioma profundizamos sobre esto.
Lo que lo hace “de precisión” es que el routing ocurre antes del cache lookup, no después. Si el CDN ya sirvió la versión vieja desde caché y el routing decide en ese punto, el resultado es impredecible. La precisión viene de tomar la decisión en edge, antes de que el caché entre en juego.
Las 4 características de un canary deployment de precisión para contenido estático
Según el análisis técnico publicado el 6 de mayo de 2026, un canary de precisión para sitios estáticos tiene cuatro atributos que lo distinguen de un A/B test básico:
Riesgo inicial mínimo
No se empieza desde el 10% o el 20%. Se empieza desde el mínimo viable: 1% o menos. La idea es observar bajo condiciones reales antes de que el error afecte a una parte significativa de usuarios. Esto requiere tener métricas lo suficientemente sensibles para detectar señales con tráfico reducido.
Routing antes del cache lookup
El sistema toma la decisión de a qué versión enviar al usuario antes de consultar el caché. Así, el tráfico canary y el tráfico estable nunca se mezclan en la capa de caché. Si el routing ocurre después del caché, podés terminar sirviendo assets de versiones distintas al mismo usuario dependiendo de qué había cacheado en qué nodo del CDN.
Claves de routing determinísticas y anónimas
No usa cookies para tomar la decisión de routing. En cambio, genera una clave anónima y determinística: dado el mismo input, siempre produce el mismo resultado. Esto evita la situación donde un usuario recibe la versión canary en una request y la estable en la siguiente porque la cookie cambió o no estaba disponible. Hay un fallback para cuando ninguna clave está disponible, pero el comportamiento base es predecible.
Rollback en edge, sin esperar DNS
¿Y qué pasa cuando algo se rompe? Exacto: revertís una decisión de edge. No esperás que el DNS se propague. No hacés un re-deploy. Un cambio en la configuración del edge revierte el tráfico a la versión estable en segundos. Eso es lo que convierte el canary de precisión en una herramienta de gestión de riesgo real, no solo de despliegue. Complementá con aprender de incidentes críticos en producción.
Migraciones de React SPA a Next.js: por qué el escenario importa
Cualquiera que haya migrado de una SPA a un framework con SSG o SSR sabe que el cambio no es solo en el código. Cambia el modelo de routing (React Router vs file-based routing), cambia cómo se sirven los assets, cambia dónde viven los errores, y cambia la relación entre el servidor y el navegador.
Probás todo eso en staging, donde tenés cinco usuarios controlados con navegadores limpios y sesiones frescas. El problema es que en producción hay usuarios que tienen la SPA en caché desde hace tres semanas, con service workers registrados, con estado local que la nueva versión no sabe que existe.
Un canary de precisión te deja observar qué pasa cuando esos usuarios reales tocan la nueva versión. No el 30% de ellos de golpe: el 1%, controlado, con métricas. Eso cambia la conversación de “esperemos que funcione” a “los datos dicen que podemos expandir”.
Si tu infraestructura corre en AWS, este patrón se implementa típicamente con CloudFront Functions o Lambda@Edge tomando la decisión de routing. Para quienes alojan en infraestructura propia o en un proveedor como donweb.com con soporte de CDN, el principio es el mismo: la decisión tiene que ocurrir en el nodo más cercano al usuario, antes del caché.
Monitoreo y expansión: cuándo el canary es seguro para crecer
Mandás el 1% al canary. ¿Ahora qué mirás?
Las métricas que importan no son las de UX (esas son lentas): son errores de JavaScript en consola, tasa de requests fallidas al backend, tiempo de carga del primer asset crítico, y tasa de sesiones que terminan abruptamente en los primeros segundos. Si esas métricas se mantienen equivalentes entre el grupo canary y el grupo de control, el canary está listo para crecer.
La velocidad de expansión depende del volumen de tráfico. Con un sitio de alto tráfico podés ir de 1% a 5% a 20% a 100% en horas. Con tráfico bajo tenés que esperar más para tener significancia estadística. El error más común acá es apurarse porque “parece que anda bien” sin tener suficiente tráfico para saberlo. Tema relacionado: orquestar despliegues con herramientas automatizadas.
En cada paso de expansión, el rollback sigue disponible. No es que llegás al 50% y ya no podés volver: la decisión de edge se puede revertir en cualquier punto del rollout. Eso sí: cuanto más lejos llegaste, más inconsistencia podés introducir si revertís abruptamente (usuarios que ya recibieron assets de la versión nueva y ahora reciben la estable). Por eso el monitoreo temprano es lo que más importa.
Redesigns completos: cuando cambian varias cosas a la vez
El caso más difícil no es migrar el framework. Es cuando combinás el cambio de framework con un redesign visual, más un cambio en la estructura de URLs, más una migración del sistema de caché. Todo junto. (Sí, en serio. Los equipos hacen esto.)
Ahí el canary de precisión es lo único que mantiene el despliegue manejable, porque reduce la superficie de error que podés observar de a una fracción por vez. Si el 1% del tráfico recibe todos los cambios combinados y algo se rompe, al menos sabés que el impacto está acotado y tenés datos reales sobre qué se rompió antes de comprometer al resto.
Lo interesante es que este patrón también aplica cuando cambiás solo las URLs: un cambio de modelo de routing implica que URLs viejas pueden quedar huérfanas para usuarios con bookmarks, links en correos, o resultados de Google que todavía apuntan a la estructura anterior. Un canary te da tiempo de verificar que los redirects funcionan bajo tráfico real antes de que afecten a todos.
Esto se relaciona con nuestro artículo sobre Precision Canary Deployments for Static Content: Navigating, donde profundizamos en el tema.
Para meterse más en el tema, tenemos Precision Canary Deployments for Static Content: Navigating .
Para profundizar, leé nuestro análisis sobre Precision Canary Deployments for Static Content: Navigating.
Para más detalles sobre esto, mirá Precision Canary Deployments for Static Content: Navigating.
Esto se relaciona con Precision Canary Deployments for Static Content: Navigating , donde lo explicamos al detalle.
Errores comunes al implementar canary deployments de contenido estático
- Hacer el routing después del caché: si el CDN sirve el asset antes de que el edge tome la decisión, terminás mezclando versiones. El routing tiene que estar en la capa anterior al caché, sin excepción.
- Usar cookies como clave de routing: las cookies pueden no estar disponibles, pueden cambiarse por el usuario, o pueden estar bloqueadas por políticas de privacidad. Una clave determinística basada en atributos estables de la request es más confiable y no requiere que el usuario esté autenticado.
- Expandir demasiado rápido sin suficiente tráfico: pasar de 1% a 50% en diez minutos no te da datos, te da falsa seguridad. Con tráfico bajo, un porcentaje pequeño puede no detectar un error que afecta solo a cierta combinación de navegador y sistema operativo.
- Asumir que staging equivale a producción: no equivale. Nunca. El propósito del canary es precisamente obtener datos de producción real con riesgo controlado. Si usás staging para “confirmar” y producción solo para “desplegar”, estás saltando el paso más importante.
Preguntas Frecuentes
¿Qué es un canary deployment y cómo se diferencia de un A/B test?
Un canary deployment es una técnica de despliegue progresivo donde un porcentaje pequeño del tráfico real recibe la nueva versión del software antes que el resto. Se diferencia de un A/B test en que el objetivo no es medir cuál versión performa mejor para el negocio, sino verificar que la nueva versión funciona correctamente antes de comprometer a todos los usuarios. Cuando el canary pasa la verificación, el 100% del tráfico pasa a la nueva versión; no conviven indefinidamente. Cubrimos ese tema en detalle en validaciones automáticas en cada despliegue.
¿Cómo migrar de React a Next.js sin afectar producción?
La estrategia más segura es implementar un canary deployment de precisión: mandar el 1% del tráfico real a la versión Next.js mientras el 99% sigue en React, observar métricas de errores y rendimiento, y expandir solo cuando los datos lo justifican. El routing debe ocurrir en edge antes del cache lookup para que los assets de ambas versiones no se mezclen en el CDN. El rollback está disponible en cualquier punto del rollout.
¿Por qué el routing en canary deployments debe ocurrir antes del cache lookup?
Si el caché sirve el asset antes de que el sistema decida qué versión corresponde al usuario, podés terminar con un usuario que recibe el HTML de la versión nueva pero los assets JavaScript de la versión vieja, o viceversa, dependiendo de qué había cacheado en qué nodo del CDN. El routing en edge, antes del caché, garantiza que cada versión del tráfico recibe assets coherentes de una sola versión.
¿Cuándo es seguro expandir un canary deployment al 100%?
Cuando las métricas de error del grupo canary son equivalentes a las del grupo de control durante un período con suficiente tráfico para tener significancia estadística. Las métricas clave son errores de JavaScript en consola, tasa de requests fallidas, tiempo de carga del primer asset crítico, y tasa de sesiones que terminan abruptamente. “Parece que anda” sin datos suficientes no es criterio para expandir.
¿Qué ventaja tiene sobre cambios de DNS para separar versiones?
Los cambios de DNS tienen TTLs que pueden tardar minutos u horas en propagarse dependiendo del proveedor y del resolver del usuario. Un cambio de decisión de edge es instantáneo: revertís la configuración y el tráfico vuelve a la versión estable en segundos, sin esperar propagación. Para incidentes en producción, esa diferencia entre segundos y minutos es lo que separa un rollback manejable de un incidente extendido.
Conclusión
Los canary deployments de precisión para contenido estático resuelven un problema que el testing en staging nunca va a resolver: el estado acumulado de usuarios reales en producción. La combinación de routing en edge antes del cache lookup, claves determinísticas sin dependencia de cookies, y rollback instantáneo convierte una migración de alto riesgo en un experimento controlado con salida de emergencia en cada paso.
Si tu equipo tiene planeada una migración de React a Next.js, un redesign completo, o cualquier cambio que toque el modelo de routing del sitio, el costo de implementar este patrón es bajo comparado con el costo de un incident en producción que afecte a todos los usuarios al mismo tiempo. La pregunta no es si podés permitirte hacerlo: es si podés permitirte no hacerlo.