Kubernetes: clusters llenos con recursos ociosos
La gestión de recursos Kubernetes tiene un problema que casi nadie resuelve bien: los clusters aparecen llenos en el dashboard, el gasto en infraestructura no para de subir, y al mismo tiempo hay núcleos de CPU y gigabytes de RAM que no hacen nada. Según el análisis publicado en mayo de 2026, esta paradoja es la norma en entornos de producción grandes, y tiene una causa clara: requests inflados que distorsionan el scheduling desde el principio.
En 30 segundos
- Los clusters Kubernetes aparecen “llenos” mientras tienen enormes cantidades de CPU y RAM ociosa — el problema está en requests inflados, no en falta de capacidad real.
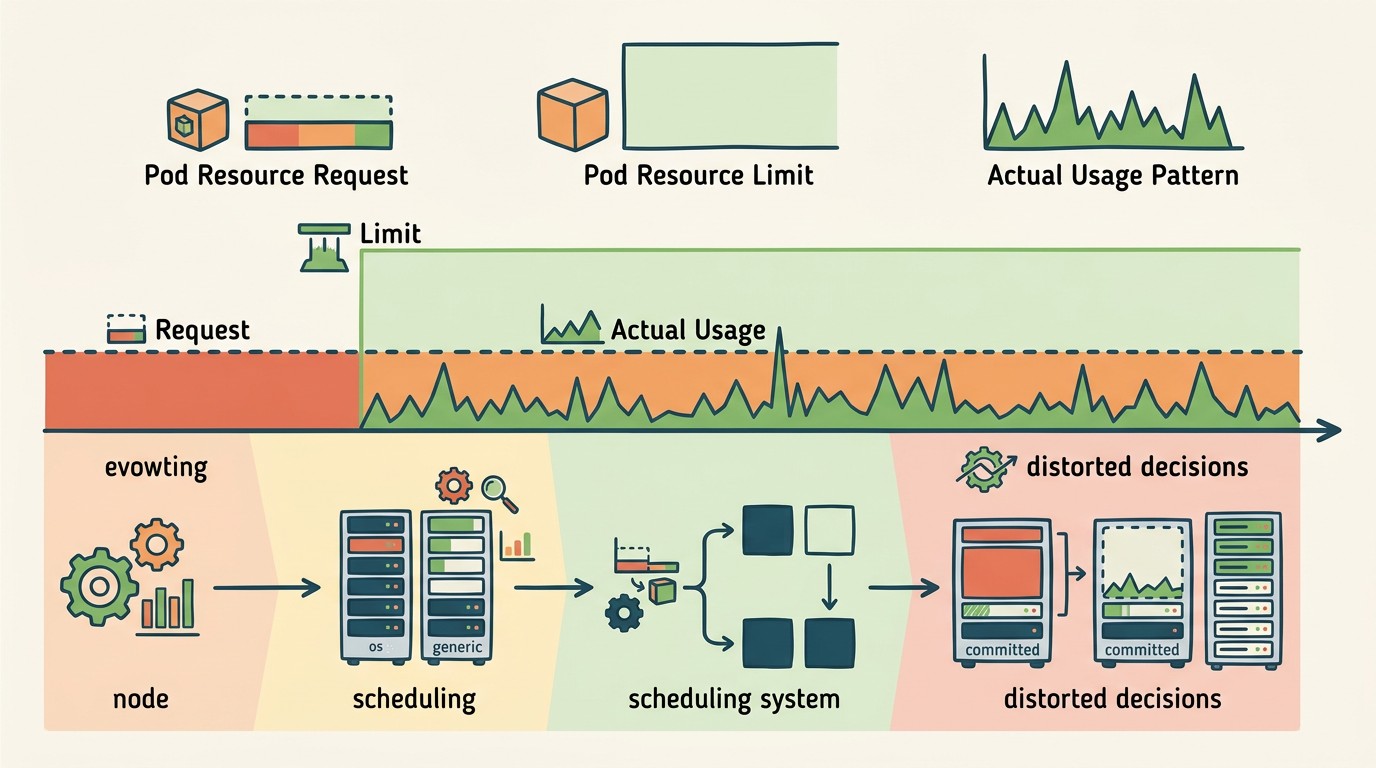
- Requests y limits son distintos: requests definen cuánto reserva el scheduler, limits ponen el techo de uso real. Confundirlos es el error más caro en producción.
- El autoscaling (HPA) amplifica el desperdicio si los pods están mal dimensionados — right-size primero, luego escalá.
- Las GPUs son exponencialmente más caras que CPU/RAM; el desperdicio en workloads de IA puede costar 10 veces más que el mismo error en cómputo estándar.
- Una plataforma Kubernetes madura combina monitoreo continuo, visibilidad de costos por equipo, y ownership compartido — no es solo configuración técnica.
La Paradoja de los Clusters Kubernetes: Llenos pero Ineficientes
Ponele que tenés un cluster con 20 nodos, el dashboard te dice que está al 85% de capacidad, y el equipo de infraestructura ya está pidiendo presupuesto para agregar más servidores. Al mismo tiempo, Prometheus te muestra que el uso real de CPU promedio es del 30%. ¿Cuál de los dos tiene razón? Los dos, y ese es el problema.
Kubernetes no schedula pods basándose en lo que realmente usan — los schedula basándose en lo que pidieron (requests). Si un pod declara que necesita 2 CPUs y en la práctica usa 0.3, el scheduler igual reservó esas 2 CPUs en el nodo. Multiplicá eso por cientos de pods y entendés por qué el cluster “está lleno” mientras la mitad de los recursos se queda mirando el techo.
Este patrón aparece en prácticamente todo entorno Kubernetes grande que no tuvo un proceso activo de right-sizing. El gasto sube, la capacidad percibida cae, y la respuesta instintiva es agregar nodos. Lo cual resuelve el síntoma por un mes y después el ciclo se repite.
Requests y Limits: El Concepto Más Malentendido en Producción
La gestión de recursos en Kubernetes gira alrededor de dos conceptos que mucha gente trata como sinónimos. No lo son.
Un request es una promesa al scheduler: “este pod necesita al menos X CPU y Y memoria para funcionar”. El scheduler usa ese número para decidir en qué nodo colocar el pod. Si el nodo no tiene esa capacidad disponible, el pod queda en Pending. Lo que realmente consuma el pod después es irrelevante para el scheduling — ya ganó su lugar. Ya lo cubrimos antes en distribuir recursos en múltiples regiones.
Un limit es un techo de uso: si el pod intenta usar más CPU de lo declarado, el kernel lo throttlea. Si intenta usar más memoria, el OOM killer lo mata y lo reinicia. Son mecanismos completamente distintos que actúan en momentos distintos.
¿Y qué pasó cuando los equipos descubrieron el OOM killer? Exacto: pusieron limits de memoria altísimos “por las dudas”. Y los requests siguieron creciendo porque nadie quiere que su servicio quede en Pending durante un deploy. El resultado son clusters donde los requests declarados multiplican por 3 o 4 el uso real. La documentación oficial de Kubernetes es clara sobre esta distinción, pero la documentación y la práctica de producción son dos mundos diferentes.
Right-Sizing: Medí Antes de Configurar
El proceso correcto no empieza escribiendo números en el YAML. Empieza midiendo.
La metodología que recomienda la CNCF para configurar requests correctamente es observar el percentil 90 o 95 del uso bajo carga real, no el pico máximo histórico. El pico máximo genera requests sobredimensionados. El promedio simple te deja sin margen para spikes. El P90 o P95 encuentra un punto razonable: cubrís la carga normal con algo de margen sin regalar capacidad al scheduler.
Herramientas para hacerlo:
- Prometheus + Grafana: métricas históricas de uso real, base para cualquier análisis serio.
- Kubernetes Metrics Server: datos en tiempo real vía
kubectl top pods, útil para una foto rápida. - Vertical Pod Autoscaler (VPA) en modo recomendación: observa el uso real y sugiere valores sin aplicarlos — perfecto para la etapa de análisis.
Lo que no sirve: asignar un valor genérico a todo. “100m de CPU para todos los pods” suena ordenado y es un desastre en producción. Un pod de Nginx estático y un pod procesando imágenes con PIL tienen perfiles de uso completamente distintos.
Autoscaling en Kubernetes: Por Qué HPA Solo No Alcanza
El Horizontal Pod Autoscaler escala el número de réplicas basándose en métricas (típicamente CPU o memoria). El problema: si cada réplica tiene requests inflados, escalar agrega más desperdicio, no más capacidad útil.
Matemática simple: si un pod debería pedir 200m de CPU y está pidiendo 800m, cuando HPA escala de 3 a 6 réplicas pasás de reservar 2.4 CPUs a reservar 4.8 — aunque el trabajo real solo necesite 1.2 CPUs. El autoscaling amplificó el desperdicio 4 veces.
La secuencia correcta, según ScaleOps: right-size primero, después configurá el autoscaling. No al revés.
Las tres capas del autoscaling que necesitan trabajar juntas:
| Mecanismo | Qué hace | Cuándo usarlo |
|---|---|---|
| HPA (Horizontal Pod Autoscaler) | Escala réplicas según métricas | Workloads stateless con carga variable |
| VPA (Vertical Pod Autoscaler) | Ajusta requests/limits de pods individuales | Pods con uso variable difícil de predecir |
| Cluster Autoscaler | Agrega o elimina nodos según pods pendientes | Siempre, como capa base del cluster |
Ojo: HPA y VPA en modo automático pueden conflictuar — VPA cambiando resources mientras HPA está escalando réplicas genera comportamiento impredecible. La combinación más segura es VPA en modo recomendación + HPA para scaling horizontal. Te puede servir nuestra cobertura de analizar incidentes críticos de disponibilidad.
GPUs y Recursos Especializados: Donde la Ineficiencia Cuesta Más
Todo lo que dijimos sobre CPU y memoria aplica a GPUs, pero multiplicado por el costo por hora de una A100 o H100.
Una GPU A100 en cualquier proveedor cloud costea entre USD 3 y USD 5 por hora. Si tu workload de inferencia usa el 20% de la GPU pero solicitó el 100% (porque así quedó configurado el deployment), estás pagando USD 4/hora por USD 0.80 de trabajo real. A escala de un cluster con 50 GPUs, eso es USD 120 por hora en desperdicio.
Los desafíos específicos de GPUs en Kubernetes:
- Por defecto, Kubernetes trata la GPU como recurso binario: un pod pide 1 GPU completa o no pide ninguna. No hay fracciones nativas.
- La compartición de GPU (MIG en A100, MPS para inferencia) requiere configuración explícita y no funciona en todos los workloads.
- Los frameworks de ML (PyTorch, TensorFlow) suelen reservar toda la VRAM disponible al iniciar, aunque no la necesiten.
El scheduling inteligente de GPUs requiere estrategias específicas: bin-packing para consolidar workloads pequeños en menos GPUs, time-slicing para compartir GPUs entre jobs de batch, y monitoring de VRAM real vs. VRAM solicitada. No son las mismas técnicas que CPU/memory.
Características de una Plataforma Kubernetes Madura
Una plataforma Kubernetes que realmente funciona a escala tiene atributos que van más allá de la configuración técnica. Sedai lo describe como la combinación de características operacionales, culturales y arquitectónicas que logran balance entre reliability, eficiencia y costo.
Técnicamente, una plataforma madura tiene:
- Monitoring continuo de la brecha entre requests y uso real, con alertas cuando la brecha supera un umbral definido.
- Admission controllers que rechazan deployments sin resources configurados o con valores fuera de rangos definidos por políticas (LimitRange, ResourceQuota).
- Procesos de capacity planning basados en tendencias históricas, no en intuición.
- Separación clara entre namespaces por equipo/servicio, con quotas que reflejan necesidades reales.
Culturalmente, el atributo más importante es que los equipos que generan el gasto tengan visibilidad de lo que cuestan. Cuando el equipo de backend ve que sus pods tienen una brecha del 300% entre requests y uso real, la conversación sobre right-sizing cambia completamente.
Visibilidad de Costos y Shared Ownership: El Objetivo Real
Acá viene lo bueno: la serie completa de la que surge este análisis arranca diciendo que pasaron todo el tiempo hablando de desperdicio, pero el objetivo nunca fue solo ahorrar dinero. Más contexto en configurar límites correctos en Docker.
El objetivo real es reliability y eficiencia genuina. Un cluster donde los requests son honestos es un cluster donde el scheduler toma decisiones correctas, el autoscaling funciona como se diseñó, y los incidentes por OOM o CPU starvation bajan. El ahorro en costos es una consecuencia, no el fin.
La visibilidad de costos por namespace, por equipo, o por servicio cumple dos funciones. La primera es obvia: identificar dónde está el desperdicio. La segunda es más importante: crear accountability. Cuando el equipo de data science ve que su namespace gastó USD 8.000 la semana pasada porque un job de entrenamiento quedó corriendo 3 días después de terminar, eso genera un cambio de comportamiento que ninguna política top-down logra.
Si manejás infraestructura propia y necesitás un proveedor de cloud o servidores para Kubernetes en Argentina, donweb.com tiene opciones de VPS y cloud que vale la pena revisar.
Qué Está Confirmado / Qué Queda por Definir
| Aspecto | Estado |
|---|---|
| La paradoja clusters llenos con recursos ociosos es sistémica en entornos grandes | Confirmado — documentado en múltiples análisis de producción |
| Requests inflados como causa principal del problema de scheduling | Confirmado — respaldado por la documentación oficial de Kubernetes |
| VPA en modo automático como solución completa | Pendiente — sigue teniendo problemas de compatibilidad con HPA; usar con precaución |
| GPU time-slicing nativo estable en todos los workloads | Pendiente — maduro en A100 con MIG, experimental en otras configuraciones |
| Herramientas de right-sizing automático a nivel enterprise | En evolución — varias soluciones comerciales, ninguna universalmente adoptada |
Errores Comunes que Siguen Apareciendo en Producción
1. Copiar requests del ambiente de staging a producción. Staging tiene carga de prueba, producción tiene carga real. Los perfiles son distintos y los requests tienen que medirse en cada ambiente por separado. Muchos equipos hacen el deploy a producción con los mismos values del manifiesto de staging y se preguntan por qué hay OOM kills.
2. Poner limits de CPU muy ajustados. A diferencia de memoria (donde superar el limit mata el pod), superar el limit de CPU solo genera throttling. Un pod que necesita un burst de 2 CPUs por 100ms pero tiene un limit de 500m va a ser throttleado constantemente, degradando latencia sin ningún mensaje de error visible. El síntoma parece un problema de código, no de configuración.
3. Configurar ResourceQuotas sin revisar qué pasa cuando se alcanzan. Cuando un namespace llega a su quota, los nuevos pods quedan en Pending sin un mensaje de error particularmente claro. El equipo ve que el deploy “no hizo nada” y empieza a buscar el problema en el código o en el pipeline de CI/CD, no en la quota. Cubrimos ese tema en detalle en automatizar workflows de infraestructura.
Podés leer más al respecto en nuestro artículo What Mature Kubernetes Resource Management Actually Looks Li.
Esto se conecta con What Mature Kubernetes Resource Management Actually Looks Li, donde cubrimos el tema en detalle.
Si querés profundizar en esto, tenemos un artículo sobre What Mature Kubernetes Resource Management Actually Looks Li.
Mirá más sobre esto en What Mature Kubernetes Resource Management Actually Looks Li.
Esto conecta directamente con What Mature Kubernetes Resource Management Actually Looks Li, donde profundizamos en la optimización de recursos en entornos de producción.
Si necesitás profundizar en cómo gestionar esto bien, mirá What Mature Kubernetes Resource Management Actually Looks Li.
Para profundizar en esto, tenemos un artículo detallado sobre What Mature Kubernetes Resource Management Actually Looks Li.
Si querés profundizar en esto, tenemos un artículo sobre What Mature Kubernetes Resource Management Actually Looks Li.
Preguntas Frecuentes
¿Cómo optimizar la gestión de recursos en un cluster Kubernetes de producción?
El punto de partida es medir el uso real durante carga representativa con Prometheus y configurar requests en el percentil 90 de ese uso. Después implementar LimitRange por namespace para evitar pods sin resources configurados y revisar la brecha request/uso al menos mensualmente. El ciclo de optimización es continuo, no es una configuración de una sola vez.
¿Cuál es la diferencia entre requests y limits en Kubernetes?
Los requests impactan el scheduling: el scheduler usa ese número para decidir en qué nodo colocar el pod. Si el nodo no tiene esa capacidad libre, el pod queda en Pending. Los limits son topes de uso en runtime: CPU throttling si se supera el limit de CPU, reinicio del pod por OOM si se supera el de memoria. Son mecanismos que actúan en momentos distintos del ciclo de vida del pod.
¿Cómo reducir costos de infraestructura en Kubernetes?
La mayor ganancia viene de right-sizing los pods (ajustar requests al uso real medido), no de negociar precios con el proveedor. Un cluster donde los requests reflejan el uso real puede necesitar un 40-60% menos de nodos que uno con requests inflados. Después de right-sizing, el Cluster Autoscaler puede escalar hacia abajo de forma agresiva sin riesgo de quedarse sin capacidad.
¿Por qué mi cluster está lleno pero sigue teniendo CPU y memoria ociosa?
Porque el scheduler toma decisiones basadas en requests declarados, no en uso real. Si tus pods piden más de lo que usan, el scheduler reserva esa capacidad aunque nunca se consuma. El cluster aparece “lleno” desde la perspectiva del scheduling mientras los nodos tienen la mitad de la CPU sin hacer nada. La solución es reducir los requests al uso real medido, no agregar nodos.
¿Cómo evitar que el autoscaling amplíe el desperdicio de recursos?
Right-size los pods antes de configurar HPA. Si cada réplica tiene requests inflados, HPA va a escalar más réplicas con el mismo desperdicio por unidad. El orden correcto: medí el uso real, ajustá requests, después configurá el autoscaling. VPA en modo recomendación puede ayudar a identificar los valores correctos antes de aplicarlos.
Conclusión
La gestión de recursos en Kubernetes no es un problema de configuración que se resuelve una vez. Es un proceso continuo de medición, ajuste y visibilidad. La paradoja de los clusters llenos e ineficientes tiene una causa técnica concreta (requests inflados que distorsionan el scheduling) y una causa cultural (equipos que no ven el costo de sus decisiones de configuración).
Lo que diferencia a una plataforma madura es que aborda las dos. Técnicamente: requests basados en uso real medido, autoscaling configurado después del right-sizing, y GPU scheduling con estrategias específicas para carga de IA. Culturalmente: visibilidad de costos por equipo y ownership de las decisiones de recursos. El ahorro en infraestructura viene solo — no es el objetivo, es la consecuencia de hacer las cosas bien.
Fuentes
- Dev.to — What Mature Kubernetes Resource Management Actually Looks Like (2026)
- Kubernetes — Documentación oficial sobre gestión de recursos en contenedores
- CNCF — Kubernetes best practice: cómo configurar requests y limits correctamente
- ScaleOps — 5 estrategias de optimización de recursos Kubernetes que funcionan en producción
- Sedai — Guía de capacity planning y optimización en Kubernetes