Git workflow con feature flags y rollbacks seguros
Un Git workflow con feature flags bien implementado te permite mergear código antes de estar listo para producción, deshacer cambios sin romper el historial compartido, y publicar releases con un interruptor en vez de un deploy de emergencia. La clave está en tres principios: commits pequeños, merges frecuentes, y nunca reescribir historial público.
En 30 segundos
- El workflow combina trunk-based development con feature flags para separar el momento del merge del momento del lanzamiento a usuarios
- Existen tres tipos de ramas:
main(siempre releaseable), feature branches (horas o días, no semanas), y release branches (solo para ventanas de estabilización) git revertes el único rollback seguro en ramas públicas porque preserva historial;git resetsolo en local- Los feature flags permiten deployar con el código desactivado y activarlo gradualmente sin nuevo deploy
- Las ramas largas son el enemigo principal: acumulan merge drift y hacen que integrar sea más trabajo que desarrollar
¿Por qué un Git workflow sólido importa en desarrollo moderno?
Ponele que tu equipo trabaja en una feature durante tres semanas en una rama separada. Llega el día del merge y hay 47 conflictos. Pasás dos días resolviendo conflictos en vez de desarrollando. Desplegás apurado, algo se rompe en producción, y ahora tenés que revertir un cambio que mezcla lógica de tres desarrolladores distintos en cien commits.
Ese es el costo real de no tener un workflow definido.
Según Atlassian, el desarrollo trunk-based (todos integrando a una rama principal frecuentemente) reduce el merge conflict pain y mantiene el código en estado releaseable casi siempre. No es una novedad de 2026, pero sigue siendo la práctica más ignorada en equipos que usan Git sin pensarlo demasiado.
Un workflow sólido no es solo branching. Es hacer que cada cambio sea fácil de shipar, fácil de deshacer, y fácil de entender tres meses después cuando alguien bisecte el historial preguntando “¿quién rompió esto?”.
Los tres pilares: commits pequeños, merges frecuentes, historial intacto
Todo el workflow descansa en tres principios que se refuerzan entre sí.
Commits pequeños y atómicos. Cada commit debe representar un cambio con sentido propio, no “arreglé todo lo de ayer”. Esto no es purismo; es pragmatismo. Cuando algo se rompe y necesitás bisectar, querés commits que puedas leer en 30 segundos y saber exactamente qué hacen. Un commit que toca 40 archivos y dice “varios fixes” es ruido.
Merge a main con frecuencia. La regla práctica es integrar al menos una vez al día, o por lo menos cada vez que terminás una unidad de trabajo coherente. Cuanto más tiempo pasa desde el último merge, más diverge tu rama del estado real de producción. Y esa divergencia se paga con intereses al momento de integrar. Cubrimos ese tema en detalle en nuestro artículo sobre pipelines de CI/CD.
Nunca reescribir historial compartido. Una vez que pusheaste algo a una rama que otros usan, ese historial es sagrado. Reescribirlo con rebase -f o reset --hard en código pushado genera un caos que a veces requiere que todos clonen el repo desde cero. El punto es que el historial compartido es un contrato con tu equipo.
Las tres estrategias de branching: cuándo usar cada una
El workflow publicado en dev.to el 31 de mayo de 2026 define tres tipos de ramas con propósitos distintos:
Main — siempre releaseable
main tiene que estar en estado deployable en todo momento. No es la rama donde “eventualmente arreglamos las cosas”. Si algo roto llega a main, la prioridad número uno es restaurarla antes que cualquier feature nueva. Esto requiere CI/CD que bloquee merges rotos, no solo que los detecte.
Feature branches — horas o días
Las ramas de feature existen para trabajo en progreso. La duración esperada es horas o, como máximo, días. Según trunkbaseddevelopment.com, mantener una feature branch viva por semanas es la principal fuente de merge drift. El objetivo no es terminar la feature completa antes de mergear; es mergear código en progreso usando feature flags para que no se active.
Release branches — solo para estabilización
Las release branches tienen un propósito muy específico: crear una ventana de estabilización antes de un tagged release. Si tu equipo no necesita ese período (porque tiene CI/CD confiable y feature flags), probablemente tampoco necesite release branches. No son obligatorias, son una herramienta para situaciones concretas.
Feature flags: el mecanismo que desacopla merge de release
Este es el cambio conceptual más importante del workflow. Sin feature flags, mergear código significa exponerlo a usuarios. Con feature flags, podés mergear código incompleto o experimental, deployar a producción con el feature desactivado, y activarlo cuando estés listo, sin un nuevo deploy.
Lo interesante es que esto también cambia lo que el historial de Git representa: en vez de reflejar fechas de lanzamiento, refleja progreso de integración. Eso facilita enormemente el debugging y el code review. Esto se conecta con lo que analizamos al seleccionar tu herramienta de automación.
Hay distintas formas de implementarlos:
| Tipo | Cómo funciona | Cuándo usarlo | Herramientas |
|---|---|---|---|
| Hardcoded | Condicional en el código (if (FEATURE_X_ENABLED)) | Prototipos, equipos pequeños | Sin dependencias externas |
| Variables de entorno | process.env.FEATURE_X o similar | Equipos medianos con CI/CD | .env, config del servidor |
| Servicio especializado | API externa para evaluar flags en runtime | Producción, rollouts graduales | Flagsmith, LaunchDarkly, ConfigCat |
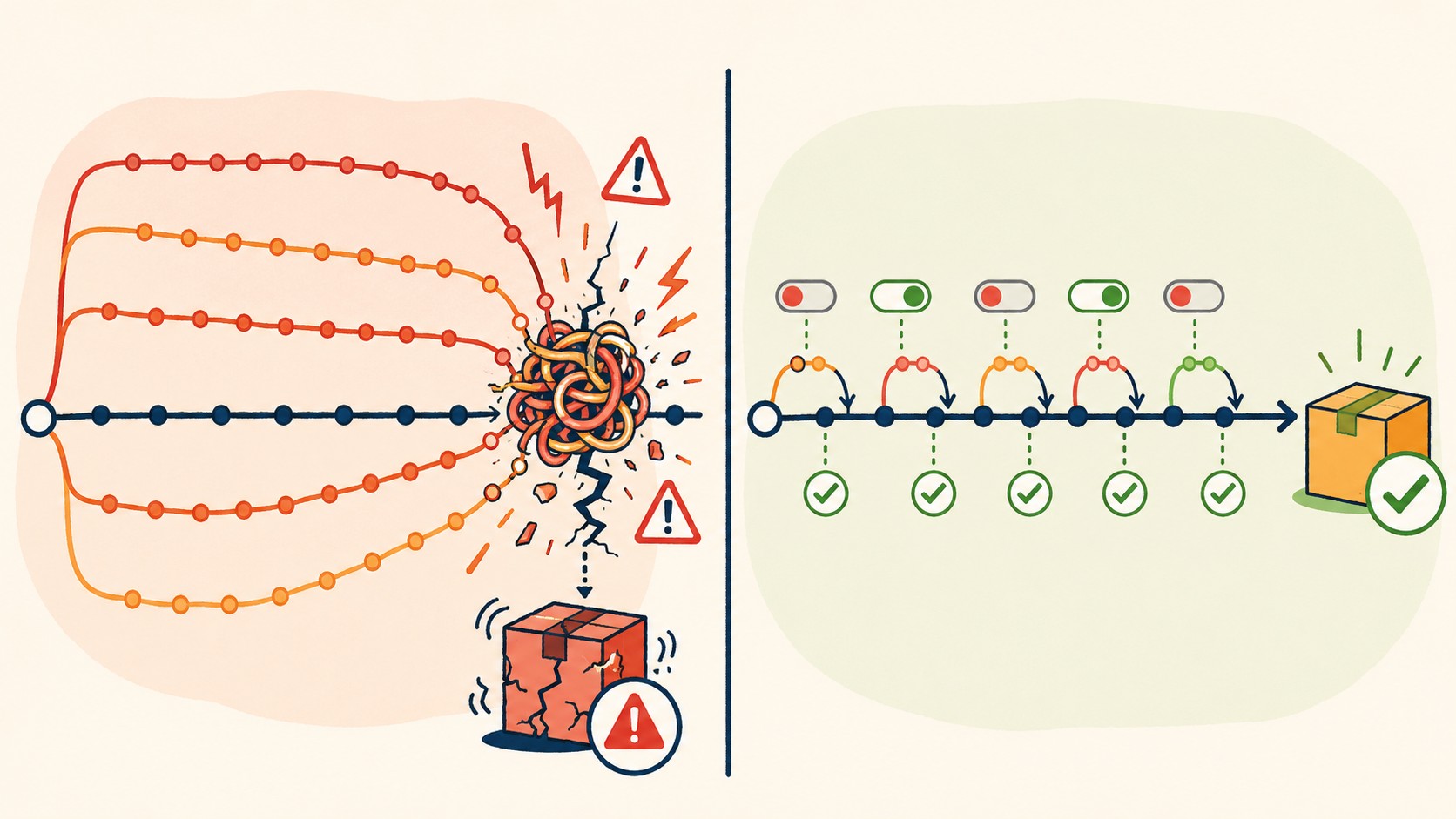
La diferencia entre un condicional en el código y un servicio externo es que con el servicio podés activar el feature para el 5% de los usuarios, luego 20%, luego 100%, sin tocar código. También podés desactivarlo en segundos si algo falla, sin un rollback de Git.
El estado por defecto de un feature flag nuevo siempre debe ser OFF. Siempre. Sin excepciones. Un flag que se activa solo porque alguien olvidó ponerlo en OFF es un bug de producción esperando a pasar.
Rollbacks seguros: git revert vs git reset
Esta diferencia destruye proyectos cuando se entiende mal.
git revert <commit> crea un nuevo commit que invierte los cambios del commit original. El historial queda intacto, el commit problemático sigue visible, y cualquiera que haya clonado el repo puede seguir trabajando sin conflictos. Según la documentación de Atlassian, revert es la herramienta correcta para deshacer cambios en ramas públicas precisamente porque no reescribe historial.
git reset --hard <commit> mueve el puntero de la rama hacia atrás, descartando los commits intermedios. En local, antes de pushear, es una herramienta válida. En código ya pusheado a una rama compartida, es un problema: los demás desarrolladores tienen esos commits en su historia local, y cuando intenten pushear van a tener divergencias que no tienen sentido.
¿Y qué pasa cuando hacés reset en una rama compartida y forzás el push? Exacto: todos los que trabajan en esa rama tienen que hacer un fetch, ver que el historial diverge, y en el mejor caso hacer un reset manual. En el peor, pierden trabajo.
La regla es simple: si el commit ya está en un remote que otros usan, solo revert. Punto. Lo explicamos a fondo en nuestro artículo sobre configuraciones técnicas avanzadas.
El flujo completo paso a paso
Traducido a comandos concretos, el workflow se ve así:
- Partís desde latest
main:git checkout main && git pull origin main - Creás una feature branch de vida corta:
git checkout -b feature/nombre-descriptivo - Desarrollás en commits pequeños cada 1-2 horas de trabajo, no al final del día
- El código nuevo va envuelto en un feature flag desactivado por defecto
- Cuando terminás (o tenés algo integrable), abrís PR a
main - Tras el merge, deployás a producción con el flag en OFF
- Monitoreás métricas, activás el flag para un subconjunto pequeño
- Si algo explota,
git revertenmaino desactivás el flag desde el dashboard - Si todo va bien, expandís el rollout gradualmente hasta 100%
La clave es que el deploy y el lanzamiento a usuarios son eventos separados. Eso cambia completamente la presión sobre los developers: podés deployar código imperfecto sabiendo que los usuarios no lo ven todavía.
Errores comunes que destruyen el workflow
Usar git reset en ramas compartidas
Ya lo vimos, pero vale repetirlo porque es el error más destructivo. Alguien comitea algo problemático, entra en pánico, hace reset --hard y fuerza el push. Resultado: divergencia en el historial de todos los que tenían esa rama. No uses reset en código pushado. Usá revert.
Ramas que viven semanas
Una feature branch que existe por tres semanas acumula tanto merge drift que integrarla se convierte en un proyecto secundario. El problema no es el tamaño de la feature; es la falta de integración incremental. Si la feature es grande, divididla en partes independientes que puedan mergearse (con flags desactivados) aunque la feature completa no esté lista.
Feature flags que nunca se limpian
Meter un feature flag es fácil. Sacarlo cuando la feature lleva seis meses en producción al 100% es lo que nadie hace. El resultado es código lleno de condicionales muertos que nadie se anima a tocar porque “no sabe qué puede pasar”. Cada flag nuevo tiene que tener una fecha de vencimiento planeada desde el principio.
Commits que mezclan refactors con features
Un commit que dice “refactor del módulo de pagos + nueva validación de tarjetas” es dos commits comprimidos. Si la nueva validación rompe algo, no podés revertirla sin revertir también el refactor. Los commits atómicos no son ceremonia, son lo que hace posible el debugging preciso. Más contexto en nuestro artículo sobre herramientas de ejecución local.
Preguntas Frecuentes
¿Cómo implemento un Git workflow seguro con feature flags desde cero?
Empezá con la parte más simple: establecer que main siempre tiene que estar deployable y que las feature branches duran días como máximo. Después sumá feature flags empezando por condicionales simples en el código, sin necesidad de servicios externos. Una vez que el equipo entienda el flujo, podés evaluar herramientas como Flagsmith o LaunchDarkly para rollouts más sofisticados.
¿Cuál es la diferencia entre git revert y git reset?
git revert crea un nuevo commit que deshace los cambios de un commit anterior, preservando el historial completo. git reset mueve el puntero de la rama hacia atrás, eliminando commits del historial. En ramas compartidas (código ya pusheado), solo revert es seguro; reset reescribe historial y genera divergencias para todos los colaboradores.
¿Por qué las ramas de larga duración son problemáticas?
Mientras una feature branch vive separada de main, los demás desarrolladores siguen integrando cambios. Con el tiempo, la distancia entre tu rama y main crece, y mergear se convierte en resolver conflictos que no tienen relación con tu trabajo. Según trunkbaseddevelopment.com, las ramas cortas con integración frecuente son el mecanismo principal para evitar ese merge drift acumulado.
¿Cuándo necesito una release branch y cuándo puedo saltearla?
Las release branches tienen sentido si tu proceso de QA requiere una ventana de estabilización antes de taggear un release, o si coordinás releases con equipos de hardware o terceros. Si tenés CI/CD confiable y feature flags que te permiten controlar activaciones en producción, probablemente no necesitás release branches para la mayoría de los proyectos.
¿Es necesario un servicio externo de feature flags o alcanza con condicionales?
Para proyectos pequeños o equipos de 2-3 personas, condicionales con variables de entorno son suficientes. Un servicio especializado agrega valor cuando necesitás rollouts graduales por porcentaje de usuarios, activar features por segmento (beta users, región, plan), o desactivar un flag en producción sin deploy. El costo de herramientas como Flagsmith empieza desde planes gratuitos para proyectos pequeños.
Conclusión
El workflow que describe Rizwan Saleem en su artículo del 31 de mayo de 2026 no inventa nada nuevo, pero junta bien tres prácticas que por separado son incompletas. Trunk-based development sin feature flags te obliga a sincronizar desarrollo y lanzamiento. Feature flags sin commits atómicos hacen el debugging imposible. Y rollbacks sin entender la diferencia entre revert y reset convierten una emergencia en dos emergencias.
La adopción real requiere cambio cultural tanto como técnico. Un equipo que está acostumbrado a ramas de dos semanas no va a pasar a integración diaria de un día para el otro. Pero empezar con una sola regla concreta (por ejemplo, “ninguna feature branch vive más de tres días”) ya cambia cómo el equipo piensa sobre la integración.
Si administrás infraestructura o deployás en VPS propios, este workflow se complementa bien con pipelines de CI/CD que puedan leer variables de entorno para los feature flags, algo que donweb.com soporta en sus planes de hosting con acceso a servidor.
Fuentes
- Rizwan Saleem en dev.to — artículo original sobre el workflow (2026-05-31)
- Atlassian — Trunk-based development: conceptos y beneficios
- Atlassian — git revert: documentación oficial en español
- trunkbaseddevelopment.com — referencia de la comunidad sobre desarrollo trunk-based
- Flagsmith — Git branching y feature flags: integración práctica