Pause hooks en ECS: control total de tus deploys
Amazon anunció en mayo de 2026 controles nativos de pausa y reanudación de despliegues ECS que permiten detener un deployment en puntos específicos del ciclo de vida para ejecutar validaciones, aprobaciones manuales o automatizaciones externas, sin perder las capacidades integradas de traffic shifting, rollback y circuit breaker.
En 30 segundos
- ECS ahora soporta deployment lifecycle hooks: podés pausar un despliegue antes o después de que el tráfico cambie de dirección.
- Para reanudar, llamás a la API
ContinueServiceDeploymentdesde la consola, CLI, SDK, CloudFormation, CDK o Terraform. - El timeout configurable llega hasta 14 días; si se vence, ECS puede continuar o hacer rollback automático según lo que hayas definido.
- EventBridge captura los eventos de pausa y te permite disparar workflows, notificaciones por email/Slack, funciones Lambda o Step Functions.
- La pausa no desactiva circuit breaker ni rollback automático — las protecciones nativas siguen activas mientras el despliegue está detenido.
Qué son los controles de pausa y reanudación en Amazon ECS
Un deployment lifecycle hook en ECS es un punto de parada configurado dentro del ciclo de vida de un despliegue. Cuando el deployment llega a ese punto, ECS frena la ejecución y espera una señal explícita para continuar. Según el anuncio oficial de AWS, la característica está disponible desde mayo de 2026 para todos los servicios ECS con estrategia de deployment configurada.
Hay dos momentos donde podés insertar hooks: antes del cambio de tráfico (pre-traffic) y después (post-traffic). El primero es el más común para aprobaciones manuales. El segundo sirve para verificar que el entorno nuevo está estable antes de cerrar definitivamente el anterior.
La diferencia clave con detener un despliegue: pausar no cancela nada. Las tareas nuevas siguen corriendo, el circuit breaker sigue evaluando salud, y el rollback automático sigue disponible. Es como poner play/pause en un video, no como cerrarlo.
Casos de uso: cuándo pausar tiene sentido
Ponele que tu equipo tiene una política de “cuatro ojos” para cambios en producción. Sin lifecycle hooks, tenías que usar pipelines externos que no siempre se integran limpio con ECS. Ahora podés pausar el despliegue justo antes de que el tráfico migre, esperar la aprobación del tech lead, y recién ahí mandarlo a producción.
Otros escenarios que sí o sí van a sacar provecho de esto:
- Testing de integración post-deploy: pausás después de levantar las tareas nuevas pero antes de enviarles tráfico real, corrés un smoke test, y si pasa, continuás.
- Compliance checks: en entornos regulados (fintech, salud), necesitás evidencia de que alguien revisó el cambio antes de que llegue a usuarios. La pausa genera ese checkpoint auditable.
- Aprobaciones por cambio de horario: si tu política es que los deploys a producción solo pasan en ventanas de mantenimiento nocturnas, pausás el deployment de día y lo reanudás a la noche desde una Lambda triggered por EventBridge Scheduler.
- Feature flags coordinados: desplegás el código nuevo pausado, activás el feature flag en tu sistema de configuración, y después continuás el despliegue.
Lo que me parece bien de este diseño es que no te obliga a elegir entre control manual y automatización. Podés tener ambos: un webhook que notifica a Slack y espera respuesta humana, o una Lambda que evalúa métricas y decide sola.
Cómo configurar pause hooks en tu servicio ECS
La configuración va en la definición del servicio ECS, dentro de deploymentConfiguration. La documentación oficial describe la estructura así:
Vía AWS CLI
Agregás el bloque deploymentLifecycleHooks cuando creás o actualizás el servicio: Tema relacionado: pipelines modernos de CI/CD.
aws ecs update-service \
--cluster mi-cluster \
--service mi-servicio \
--deployment-configuration '{
"deploymentLifecycleHooks": [
{
"hookTargetArn": "arn:aws:events:us-east-1:123456789012:event-bus/default",
"roleArn": "arn:aws:iam::123456789012:role/ECSDeploymentHookRole",
"lifecycleStage": "RECONCILING",
"timeoutAction": "ROLLBACK",
"timeoutInMinutes": 60
}
]
}'
El campo lifecycleStage acepta RECONCILING (pre-traffic) o BAKING (post-traffic). El timeoutAction puede ser CONTINUE o ROLLBACK.
Para reanudar el despliegue
Una vez que el despliegue está pausado, llamás a:
aws ecs continue-service-deployment \
--service-deployment-arn arn:aws:ecs:us-east-1:123456789012:service-deployment/mi-cluster/mi-servicio/abc123
El ARN del deployment lo obtenés de la respuesta de describe-service-deployments o del evento EventBridge. También podés hacer esto desde la consola ECS, desde los SDKs de AWS o desde CloudFormation con el recurso AWS::ECS::Service y la propiedad DeploymentLifecycleHook.
Integración con EventBridge para automatizar el flujo
Cuando ECS pausa un despliegue, emite un evento hacia el event bus que configuraste en hookTargetArn. El stream de eventos de ECS incluye el ARN del service deployment, el stage donde pausó, y los timestamps relevantes.
Con ese evento podés armar la automatización que quieras. Algunos ejemplos reales:
Notificación a Slack + aprobación humana
Una regla de EventBridge captura el evento de pausa y dispara una Lambda. La Lambda formatea el mensaje, lo manda a Slack con dos botones (Aprobar / Rechazar), y registra el deployment ARN en DynamoDB. Cuando alguien toca el botón, un segundo endpoint de API Gateway llama a ContinueServiceDeployment o fuerza el rollback.
Evaluación automática con Step Functions
EventBridge dispara una Step Functions state machine que corre tests de integración, evalúa métricas de CloudWatch (latencia p99, error rate), y si todo pasa, llama a ContinueServiceDeployment sin intervención humana. Si algún check falla, deja el despliegue pausado y alerta al equipo para decisión manual.
¿Y si nadie responde y se acaba el timeout? Exacto, ahí entra timeoutAction: definís de antemano si querés que continúe solo o que revierta. No queda colgado indefinidamente. Relacionado: optimización para alcance global.
Gestión de timeouts: 14 días y qué pasa si se vence
El timeout máximo es de 14 días (20,160 minutos). Suena exagerado, pero tiene sentido para aprobaciones que requieren revisión de CAB (Change Advisory Board) que se reúne una vez por semana, o para deployments que esperan una ventana de mantenimiento semanal.
Para aprobaciones normales, 30-60 minutos es suficiente. Para ventanas nocturnas, entre 12 y 24 horas. La clave es pensar qué pasa si nadie responde a tiempo:
ROLLBACK: ECS revierte al task definition anterior. Más seguro para producción.CONTINUE: ECS sigue el despliegue sin esperar. Tiene sentido si el hook es informativo, no un gate real.
El timeout empieza a correr desde que ECS emite el evento de pausa, no desde que tu sistema lo recibe. Si tu Lambda tiene cold start o EventBridge tiene latencia, el reloj ya está corriendo (que no es poco si configuraste un timeout corto).
Pause hooks vs otras estrategias de despliegue ECS
Los lifecycle hooks no reemplazan a blue/green ni a canary. Se combinan con ellos. Esta tabla aclara cuándo usar qué:
| Estrategia | Control de tráfico | Pausa manual | Rollback automático | Mejor para |
|---|---|---|---|---|
| Rolling update | Gradual por tareas | No nativo | Sí (circuit breaker) | Cambios de bajo riesgo, internal services |
| Blue/Green | Switch total o por % (con CodeDeploy) | Sí, con lifecycle hooks | Sí | Zero-downtime, rollback instantáneo |
| Canary | % incremental configurable | Sí, con lifecycle hooks | Sí | Validación progresiva con tráfico real |
| Linear | % fijo cada N minutos | Sí, con lifecycle hooks | Sí | Rollouts controlados y auditables |
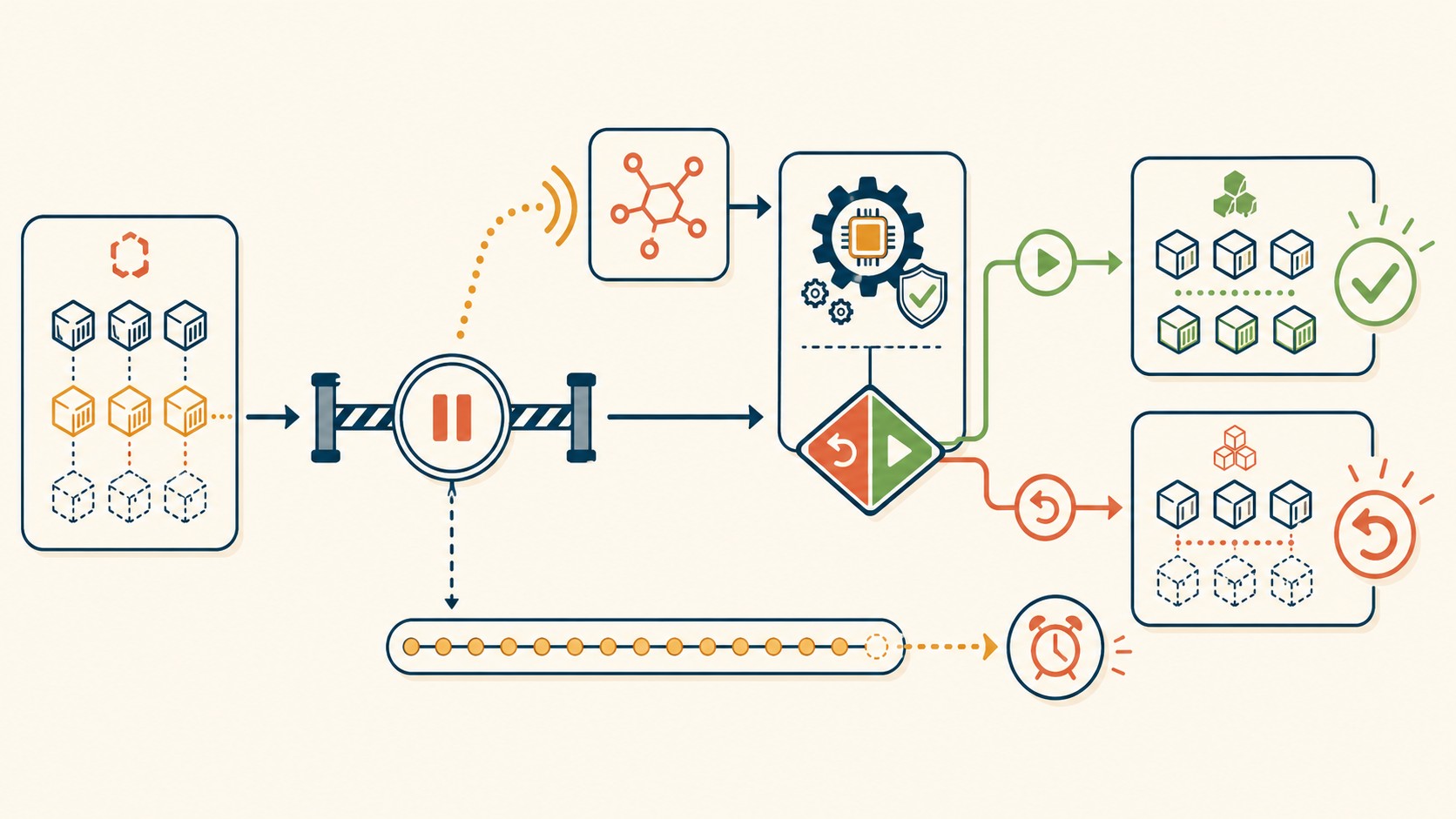
La combinación más potente en la práctica es canary + pause hook post-traffic: mandás el 10% del tráfico a la versión nueva, pausás, esperás 30 minutos de métricas reales, alguien (o algo) aprueba, y recién ahí escalás al 100%. Si algo falla en la espera, rollback en segundos.
Flujo de implementación real de punta a punta
Para que no quede abstracto, acá va un flujo concreto de cómo se ve esto en producción: Esto se conecta con lo que analizamos en automatización de infraestructura local.
- 1. Push a main: el pipeline de CI/CD buildea la imagen y actualiza el task definition en ECS.
- 2. ECS inicia el despliegue: levanta las tareas nuevas en parallel con las viejas.
- 3. Hook pre-traffic (RECONCILING): ECS pausa antes de cambiar el target group. Emite evento a EventBridge.
- 4. Lambda de notificación: recibe el evento, envía mensaje a canal de Slack con deployment ARN, imagen nueva, y commit que lo disparó.
- 5. Aprobación humana: el tech lead toca “Aprobar” en Slack. La Lambda llama a
ContinueServiceDeploymentcon el ARN del deployment. - 6. ECS migra el tráfico: el target group apunta a las tareas nuevas. Las viejas se van drenando.
- 7. Monitoring post-deploy: si el circuit breaker detecta errores en los siguientes minutos, rollback automático sin intervención.
Todo el estado del despliegue es visible en la consola ECS en tiempo real, incluyendo cuánto tiempo lleva pausado y qué timeout le configuraste.
Errores comunes al configurar lifecycle hooks
Usar timeoutAction CONTINUE en production sin pensarlo
Si el timeout vence y la acción es CONTINUE, el despliegue sigue aunque nadie lo haya revisado. Para entornos de producción, casi siempre conviene ROLLBACK como default. Mejor un rollback innecesario que un deploy no revisado en producción.
Confundir el ARN del servicio con el ARN del deployment
La API ContinueServiceDeployment requiere el ARN del deployment, no del servicio. Son distintos. El deployment ARN lo obtenés de describe-service-deployments o del evento EventBridge. Si usás el ARN del servicio, la API falla con un error que no siempre es obvio. Guardá el deployment ARN en el handler de EventBridge desde el primer momento.
Configurar el hook en un servicio con rolling update sin circuit breaker
Los lifecycle hooks funcionan en cualquier deployment type, pero si tenés rolling update sin circuit breaker activado, perdés la capa de protección automática. Durante la pausa, las tareas nuevas corren sin protección de rollback. Activá el circuit breaker siempre que uses hooks, especialmente en producción.
No testear el flujo de timeout en staging
La mayoría de los equipos prueba el happy path (aprobación manual en tiempo) pero no prueba qué pasa cuando el timeout vence. Hacé al menos un test donde dejás vencer el timeout y verificás que la acción configurada (continue o rollback) se ejecuta como esperás.
Preguntas Frecuentes
¿Cómo puedo pausar un despliegue en Amazon ECS para hacer una aprobación manual?
Configurás un deploymentLifecycleHook en la definición del servicio ECS, apuntando a un EventBridge event bus. Cuando el despliegue llega al stage configurado (RECONCILING o BAKING), ECS pausa automáticamente y emite un evento. Para reanudar, llamás a la API ContinueServiceDeployment con el ARN del deployment activo, desde consola, CLI o SDK. Cubrimos ese tema en detalle en consideraciones de seguridad en deployments.
¿Qué son los deployment lifecycle hooks en ECS?
Son puntos de parada configurables dentro del ciclo de vida de un deployment ECS. Permiten detener la ejecución en momentos específicos (antes o después del cambio de tráfico) para ejecutar validaciones, aprobaciones o automatizaciones externas. La característica está disponible desde mayo de 2026 y se configura mediante el campo deploymentLifecycleHooks en deploymentConfiguration.
¿Cómo integrar EventBridge con la pausa de despliegues en ECS?
En la configuración del hook, especificás el ARN de un EventBridge event bus en el campo hookTargetArn. Cuando ECS pausa el despliegue, emite automáticamente un evento a ese bus con el deployment ARN y el lifecycle stage. Desde ahí podés crear reglas que disparen Lambdas, Step Functions, o notificaciones SNS para armar cualquier flujo de aprobación.
¿Cuál es la diferencia entre pause hooks y blue/green deployments?
Blue/green controla cómo se migra el tráfico (switch entre dos entornos). Los pause hooks controlan cuándo avanza el despliegue. No son mutuamente excluyentes: podés usar un pause hook dentro de un deployment blue/green para agregar un gate de aprobación manual antes del traffic shift. La combinación te da tanto rollback instantáneo como control humano del momento exacto del cambio.
¿Cómo configurar un timeout de hasta 14 días para un despliegue pausado?
En el bloque deploymentLifecycleHook, usás el campo timeoutInMinutes con un valor de hasta 20,160 (14 días). Junto con el timeout, definís timeoutAction: CONTINUE para que el despliegue siga si nadie responde, o ROLLBACK para que ECS revierta al task definition anterior. Para producción, ROLLBACK es la opción más segura como default.
Conclusión
La pausa y reanudación de despliegues ECS resuelve un problema real que muchos equipos venían parcheando con workarounds: cómo meter un gate de aprobación humana en un pipeline de ECS sin renunciar a las protecciones nativas de rollback y circuit breaker. Hasta ahora, la solución típica era CodePipeline con approval actions manuales, que agrega complejidad operacional y no siempre integra limpio con ECS.
Ahora el control está dentro del propio ciclo de vida del servicio. La integración con EventBridge lo hace extensible sin límites: podés armar desde una aprobación simple por Slack hasta un workflow de compliance con evidencia auditada en S3. Y el timeout configurable hasta 14 días cubre prácticamente todos los escenarios reales, incluyendo los más burocráticos.
Si tu equipo ya usa ECS en producción y tiene algún tipo de proceso de revisión antes de deploys, esta es la funcionalidad para migrar ese proceso adentro del stack nativo de AWS. Vale la pena dedicarle una tarde a armarlo bien, incluyendo testear qué pasa cuando el timeout vence.
Fuentes
- AWS What’s New — Amazon ECS introduces pause and continue controls for service deployments
- AWS Docs — Deployment lifecycle hooks in Amazon ECS
- AWS Containers Blog — Extending deployment pipelines with ECS blue/green deployments and lifecycle hooks
- AWS Docs — Amazon ECS event stream for CloudWatch Events
- AWS CloudFormation — DeploymentLifecycleHook property type