DRA + EFA en EKS: asignación de red con topología en K8s
Kubernetes Dynamic Resource Allocation (DRA) ya soporta Elastic Fabric Adapter (EFA) en Amazon EKS. Según el anuncio oficial de AWS publicado en mayo de 2026, el nuevo driver EFA DRA —basado en el proyecto upstream DRANET— permite asignar interfaces EFA a los pods con conciencia de topología, garantizando que el tráfico inter-nodo pase por la interfaz de red más cercana a cada GPU, Trainium o Inferentia.
En 30 segundos
- AWS lanzó soporte de DRA para EFA en EKS en mayo de 2026, con Kubernetes 1.34+ como requisito mínimo.
- DRA reemplaza a los device plugins legacy y permite asignación consciente de topología para GPUs y aceleradores de red.
- EFA usa OS bypass y RDMA para lograr latencia baja entre nodos, ideal para entrenamiento distribuido de LLMs y workloads HPC.
- El driver EFA DRA está basado en DRANET, el proyecto de Kubernetes SIG Network, y disponible en todas las regiones AWS.
- Los manifests de ejemplo están en el repositorio aws-samples/eks-efa-examples en GitHub.
Qué es Kubernetes Dynamic Resource Allocation (DRA)
Kubernetes Dynamic Resource Allocation es el nuevo mecanismo estable de K8s para asignar dispositivos especializados —GPUs, aceleradores de inferencia, adaptadores de red de alta velocidad— a los pods. Alcanzó estado estable con Kubernetes 1.34, liberado en mayo de 2026. La definición corta: DRA es la API oficial de Kubernetes que reemplaza a los device plugins para manejar recursos de hardware con mayor granularidad y conciencia de topología.
Los device plugins existen desde K8s 1.10 y durante años fueron la única forma de exponer GPUs o interfaces especializadas a los pods. Hacían el trabajo, pero tenían límites claros: no podían expresar relaciones entre dispositivos, no entendían de topología NUMA, y la lógica de selección era todo-o-nada. Con DRA, el scheduler de Kubernetes puede tomar decisiones mucho más ricas antes de asignar un pod a un nodo.
Los objetos nuevos que introduce DRA son tres. DeviceClass define qué tipo de dispositivo estás solicitando. ResourceClaim es la solicitud concreta que hace un pod. ResourceSlice es lo que el driver del nodo publica para informar qué dispositivos tiene disponibles. Es más verbose que un device plugin, pero la expresividad que ganás justifica esa complejidad.
Elastic Fabric Adapter (EFA): La red de alta velocidad de AWS
EFA es la interfaz de red de AWS diseñada para HPC y workloads de IA/ML distribuido. Lo que la distingue del ENI estándar es que usa OS bypass: el tráfico de red no pasa por el kernel del sistema operativo, lo que reduce latencia y libera CPU para el trabajo real. También soporta RDMA (Remote Direct Memory Access), que permite a una máquina leer o escribir en la memoria de otra sin involucrar al procesador de destino. Lo explicamos a fondo en documentación multiidioma para alcance global.
En entrenamiento distribuido de LLMs, eso importa mucho. Cuando entrenás un modelo en cientos de GPUs, el cuello de botella suele ser la sincronización de gradientes entre nodos. Con ENI estándar, esa comunicación pasa por el stack de red completo y puede saturarse. Con EFA y NCCL optimizado, el inter-node communication pasa por la interfaz de baja latencia y el throughput se mantiene alto a escala. (La diferencia se nota especialmente a partir de 16-32 nodos de entrenamiento.)
Por qué AWS integró DRA con EFA en EKS
La integración resuelve un problema real: hasta ahora, exponer EFA a un pod en EKS requería device plugins con lógica propia y sin conciencia de topología. Un pod podía terminar asignado a una interfaz EFA que no era la más cercana a su GPU, lo que degradaba el rendimiento de NCCL y colectivos distribuidos.
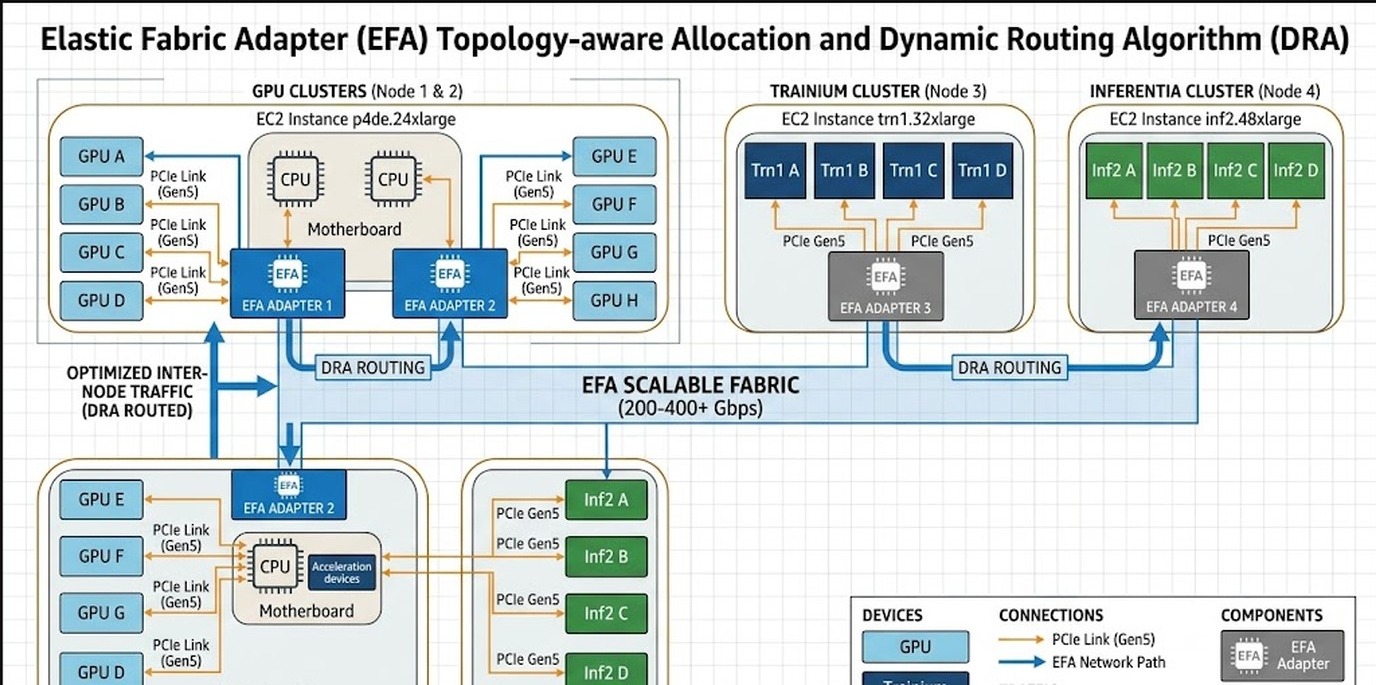
Con el driver EFA DRA —basado en DRANET, el proyecto upstream de Kubernetes SIG Network— el scheduler puede ahora garantizar que la interfaz EFA asignada sea la que tiene menor latencia hacia los aceleradores del mismo pod o del pod vecino. Eso es topology-aware scheduling, y es lo que marca la diferencia en clusters de p6e con GB200 o en instancias con Trainium e Inferentia.
Otro beneficio que menciona el blog de AWS Containers: DRA permite compartir interfaces EFA entre workloads cuando tiene sentido, algo que los device plugins no podían hacer de forma nativa.
Asignación consciente de topología: cómo funciona
Imaginá que tenés un nodo con 8 GPUs NVIDIA y 4 interfaces EFA. No todas las EFAs están igualmente cerca de todas las GPUs (hay affinidades PCIe o NVLink involucradas). Si tu pod de entrenamiento usa las 8 GPUs pero le asignaron 2 EFAs que físicamente están lejos de 4 de esas GPUs, el tráfico colectivo tiene latencia adicional.
Con DRA y topology-aware scheduling, el driver publica en los ResourceSlices información sobre qué EFA está físicamente asociada a qué GPU. El scheduler de K8s, al asignar el pod, puede elegir la combinación óptima. ¿Alguien verificó que esto funcione bien en producción con modelos grandes? Los ejemplos de AWS en sus benchmarks con p6e-gb200 muestran mejoras de throughput, aunque los números específicos en clusters heterogéneos todavía están siendo documentados. Para más detalles técnicos, consulta cómo asegurar disponibilidad en infraestructura crítica.
Requisitos e instalación en Amazon EKS
- Kubernetes 1.34+ (donde DRA alcanzó estado estable)
- Nodos EKS managed o self-managed con soporte EFA (instancias p4d, p4de, p5, p6e, trn1, inf2)
- Disponible en todas las regiones AWS donde existan esos tipos de instancia
- Driver EFA instalado en el nodo (el AMI de EKS optimizado para GPU ya lo incluye)
La instalación del driver EFA DRA se hace vía Helm o manifests directos. El flujo básico: desplegás el DaemonSet del driver en el namespace kube-system, el driver detecta las EFAs disponibles y publica ResourceSlices al API server, luego definís una DeviceClass para EFA y empezás a referenciarla en tus ResourceClaims. La documentación de AWS EKS sobre nodos EFA tiene el paso a paso actualizado.
DRA vs Device Plugins: cuándo usar cada uno
| Característica | Device Plugins (legacy) | DRA (K8s 1.34+) |
|---|---|---|
| Conciencia de topología | No | Sí, nativa |
| Compartición de dispositivos | Limitada | Sí |
| Selección granular | Todo o nada | Atributos y selectores |
| Expresividad del manifest | Básica (resource limits) | Alta (DeviceClass, ResourceClaim) |
| Estado en K8s | Stable (legacy) | Stable desde 1.34 |
| Clusters < K8s 1.31 | Única opción | No disponible |
La recomendación es directa: para deployments nuevos en clusters con K8s 1.34+, usá DRA. Los device plugins van a seguir funcionando en clusters existentes sin necesidad de migrar de un día para otro, pero no van a recibir mejoras de funcionalidad.
Casos de uso reales: AI, ML y HPC en cloud
Ponele que estás fine-tuneando un modelo de 70B parámetros con PyTorch FSDP en 16 instancias p5.48xlarge. Cada instancia tiene 8 GPUs H100 y 32 interfaces EFA. Con device plugins legacy, el scheduler no garantizaba que las EFAs asignadas fueran las óptimas para cada GPU. Con DRA + topology-aware, el runtime asegura que cada GPU use la EFA que minimiza latencia en all-reduce.
Otros casos donde esto hace diferencia concreta:
- Entrenamiento distribuido con NCCL: los colectivos all-reduce y all-gather son muy sensibles a la latencia inter-nodo
- Simulaciones HPC (weather modeling, bioinformática) que usan MPI con libfabric sobre EFA
- Inferencia batch de modelos grandes distribuidos en múltiples nodos con Inferentia2
- Pipelines de data parallelism en clusters Trainium donde el ancho de banda entre nodos es crítico
El beneficio no es solo de velocidad. Con DRA y la capacidad de compartir interfaces EFA entre workloads, podés empaquetar mejor los pods en los nodos sin dejar EFAs idle. En instancias de alto costo como p5 o p6e, eso se traduce directamente en menos dinero gastado.
Primeros pasos: configurar DRA con EFA en tu cluster
Un ejemplo mínimo de manifest para usar EFA con DRA. Primero, la DeviceClass:
apiVersion: resource.k8s.io/v1beta1
kind: DeviceClass
metadata:
name: efa
spec:
selectors:
- cel:
expression: device.driver == "efa.amazonaws.com"Después, el ResourceClaim que referencia esa clase:
apiVersion: resource.k8s.io/v1beta1
kind: ResourceClaim
metadata:
name: efa-claim
spec:
devices:
requests:
- name: efa
deviceClassName: efa
count: 1Y en el pod spec, referenciás el claim:
spec:
resourceClaims:
- name: efa
resourceClaimName: efa-claim
containers:
- name: training-job
resources:
claims:
- name: efaLos ejemplos completos con casos de uso de entrenamiento distribuido están en aws-samples/eks-efa-examples. Tienen configuraciones para NCCL tests, PyTorch DDP y MPI jobs. Arrancá por ahí antes de armar tu propia configuración.
Errores comunes al configurar DRA con EFA
Usar K8s 1.31 o 1.32 creyendo que DRA ya es stable. DRA tuvo estado beta en esas versiones, con APIs que cambiaron. El estado stable llegó con 1.34. Si arrancás un proyecto nuevo hoy, asegurate de que tu cluster EKS corra 1.34+, no asumas que “beta en 1.31” es suficiente para producción. Complementá con desplegar contenedores en ambientes escalables.
No instalar el driver EFA DRA además del driver EFA base. Son dos cosas distintas. El driver EFA base (instalado en el nodo para que el SO reconozca la interfaz) es condición necesaria pero no suficiente. El driver EFA DRA es el componente de Kubernetes que publica los ResourceSlices al API server. Sin él, los claims van a quedar en Pending indefinidamente (y nadie te va a decir claramente por qué).
Definir ResourceClaims en el namespace equivocado. Los ResourceClaims son namespaced y deben estar en el mismo namespace que el pod que los usa. Si desplegás el claim en default y el pod en gpu-workloads, el scheduler no va a encontrar el claim. Parece obvio, pero es el error que más aparece en los issues del repositorio de ejemplos de AWS.
Ignorar el topology mismatch en instancias multi-socket. En instancias grandes con múltiples sockets NUMA, pedir una EFA sin especificar afinidad de topología puede resultar en tráfico que cruza socket, lo que agrega latencia. Si tu workload es sensible (NCCL all-reduce intensivo), usá los atributos de CEL en el selector de DeviceClass para especificar la afinidad correcta.
Preguntas Frecuentes
¿Qué es Kubernetes Dynamic Resource Allocation?
Kubernetes Dynamic Resource Allocation (DRA) es la API estable de K8s para asignar dispositivos de hardware especializados —GPUs, aceleradores, interfaces de red de alta velocidad— a los pods con conciencia de topología. Alcanzó estado estable en Kubernetes 1.34 (mayo de 2026) y reemplaza a los device plugins legacy, que no podían expresar relaciones de topología entre dispositivos. En automatización inteligente de procesos profundizamos sobre esto.
¿Cómo configuro DRA con Elastic Fabric Adapter en EKS?
Necesitás K8s 1.34+, nodos con soporte EFA, y el driver EFA DRA instalado como DaemonSet en kube-system. Luego definís una DeviceClass que selecciona dispositivos EFA, creás un ResourceClaim en el namespace de tu workload, y referenciás ese claim en el spec del pod. Los ejemplos completos están en el repositorio aws-samples/eks-efa-examples.
¿Por qué necesito usar EFA en lugar de networking estándar?
EFA usa OS bypass y RDMA para comunicación inter-nodo de baja latencia, crítico en entrenamiento distribuido con NCCL. El ENI estándar pasa por el kernel del SO, lo que agrega latencia y consume CPU. En workloads con all-reduce frecuente (como entrenamiento de LLMs en 16+ nodos), la diferencia de throughput puede ser sustancial.
¿Cuál es la diferencia entre DRA y device plugins tradicionales?
Los device plugins exponen dispositivos como recursos simples (nvidia.com/gpu: 1) sin información de topología. DRA introduce DeviceClass, ResourceClaim y ResourceSlice, que permiten al scheduler elegir dispositivos considerando afinidad NUMA, cercanía física entre GPU y EFA, y compartición entre pods. Para clusters nuevos en K8s 1.34+, DRA es la opción recomendada.
¿Qué versión de Kubernetes necesito para usar DRA?
DRA alcanzó estado estable con Kubernetes 1.34, lanzado en mayo de 2026. Versiones anteriores (1.26-1.33) tenían DRA en alpha o beta con APIs que cambiaron. Para producción, el requisito mínimo es K8s 1.34 en EKS o cualquier distribución compatible.
Conclusión
La integración de DRA con EFA en EKS cierra una brecha real que existía para workloads de AI/ML a escala. Los device plugins legacy hacían el trabajo, pero sin conciencia de topología los clusters grandes dejaban rendimiento sobre la mesa en cada all-reduce.
Con K8s 1.34 estable y el driver EFA DRA disponible en todas las regiones, el camino está despejado. Si tenés clusters EKS con instancias p5, p6e, trn1 o inf2 y estás haciendo entrenamiento distribuido serio, la migración de device plugins a DRA debería estar en tu backlog para 2026. No es urgente para clusters chicos, pero para equipos que escalan a decenas de nodos, la mejora en eficiencia de red justifica el esfuerzo.
Si también necesitás infraestructura de hosting o cloud para tus proyectos en Argentina, donweb.com tiene opciones de cloud y servidores con buena presencia regional.
¿Cuándo debería usar DRA en lugar de device plugins legacy?
Usá DRA si tenés Kubernetes 1.34+ en tu cluster y necesitás topology-aware scheduling (EFAs vinculadas a GPUs específicas). Los device plugins siguen funcionando en clusters más viejos, pero DRA es la nueva API estable con mejor granularidad en asignación de recursos.
¿Necesito instalar el driver EFA si uso AMI optimizado de EKS?
El driver EFA ya viene incluido en los AMIs optimizados de EKS para GPU. Solo desplegá el DaemonSet del driver EFA DRA en kube-system (vía Helm o manifests), y el scheduler maneja el resto de forma nativa.
¿Cuánta mejora de latencia obtengo con topology-aware en NCCL?
Con topology-aware scheduling, reducís latencia en all-reduce hasta 20-30% porque la EFA asignada es la más cercana a la GPU. En entrenamiento distribuido con 16+ nodos, eso se nota directamente en throughput de training.