Kubernetes v1.36: escalado vertical sin reinicio en Beta
Kubernetes v1.36 habilita el escalado vertical de pods sin reinicio a nivel de pod completo con la feature InPlacePodLevelResourcesVerticalScaling, activada por default desde el lanzamiento del 30 de abril de 2026. Podés ajustar CPU y memoria del presupuesto agregado del pod sin tocar contenedores individuales, y en muchos casos sin interrumpir el workload.
En 30 segundos
- Kubernetes v1.36 lleva a Beta el escalado vertical in-place a nivel de pod (pod-level resources), habilitado por default vía feature gate.
- Podés cambiar el presupuesto agregado de CPU y memoria del pod sin reiniciar contenedores, si el
resizePolicylo permite. - El escalado a nivel contenedor ya alcanzó GA en v1.35; esta feature extiende ese mecanismo al modelo de recursos compartidos del pod.
- Limitaciones reales: solo CPU y memoria son redimensionables, Windows no está soportado, y la clase QoS del pod no cambia tras el resize.
- VPA 1.2+ puede automatizar el proceso con el modo
InPlaceOrRecreate, evitando reinicios cuando la plataforma lo soporta.
Qué es el escalado vertical de pods en Kubernetes
El escalado vertical en Kubernetes es el proceso de ajustar los recursos (CPU y memoria) asignados a un workload, en vez de agregar más réplicas como hace el escalado horizontal. El Horizontal Pod Autoscaler (HPA) crea y destruye pods según la carga; el Vertical Pod Autoscaler (VPA) modifica cuánto CPU/memoria tiene cada pod.
Hasta v1.35, cambiar los recursos de un pod implicaba matarlo y recrearlo. Ponele que tenés una app Java con un sidecar de Istio y un initContainer de logging: reiniciar todo ese conjunto para darle 500m más de CPU es caro, interrumpe conexiones, y en clusters con muchos pods puede encadenar una ola de reinicios bastante fea (spoiler: eso destruye la ilusión de alta disponibilidad).
El in-place resize existe para eso: aplicar el cambio de recursos mientras el pod sigue corriendo, sin recrearlo.
Novedades en Kubernetes v1.36: Pod-Level Resources Vertical Scaling llega a Beta
Hay que separar dos features que evolucionaron en paralelo:
- In-Place Pod Vertical Scaling (container-level): llegó a GA en v1.35 (diciembre 2025). Permite ajustar recursos por contenedor individual.
- Pod-Level Resources: llegó a Beta en v1.34. Permite definir un presupuesto de CPU/memoria a nivel del pod completo, que los contenedores sin límites individuales heredan automáticamente.
- In-Place Pod-Level Resources Vertical Scaling: la combinación de ambas. Llegó a Beta en v1.36, habilitada por default con el feature gate
InPlacePodLevelResourcesVerticalScaling.
¿Por qué importa el modelo pod-level? Si tenés un pod con cinco contenedores y ninguno tiene límites individuales definidos, todos comparten el presupuesto del pod. Con v1.36 podés expandir ese presupuesto compartido durante picos de demanda sin tener que recalcular límites por contenedor. El Kubelet trata el cambio como un evento de resize para cada contenedor que hereda sus límites del pod-level, según el anuncio oficial de Narang Dixita Sohanlal (Google).
Cómo funciona el in-place pod resize sin reinicio
El mecanismo depende del campo resizePolicy que definís dentro de cada contenedor. Tiene dos valores posibles: NotRequired (el resize se aplica sin reiniciar) y RestartContainer (el contenedor se reinicia para absorber el cambio).
CPU y memoria se tratan de forma diferente por defecto. CPU se puede ajustar in-place en la mayoría de los casos. Memoria es más compleja: reducirla puede requerir reinicio porque el OS no libera páginas de memoria asignadas simplemente porque le pedís menos. El Kubelet consulta el resizePolicy de cada contenedor afectado y decide si reinicia o no. Lo explicamos a fondo en diferentes enfoques en optimización de recursos.
Cuando iniciás un resize a nivel pod, el Kubelet propaga el cambio a todos los contenedores que heredan sus límites del pod-level budget. Si alguno de esos contenedores tiene resizePolicy: RestartContainer para memoria, ese contenedor se reinicia; los demás pueden no hacerlo.
La secuencia es: aplicás el patch al pod, el Kubelet detecta el cambio en spec.resources, evalúa qué contenedores se ven afectados, consulta sus políticas, y aplica los cambios de forma selectiva. En ningún momento se recrea el pod completo (salvo que todos los contenedores requieran reinicio, en cuyo caso el comportamiento es similar a una recreación, aunque sin pasar por el scheduler).
Limitaciones técnicas que tenés que conocer antes de activarlo
Acá viene lo importante: esto no es magia.
- Solo CPU y memoria: no podés resizar otros recursos como GPU o almacenamiento efímero con este mecanismo.
- Sin soporte en Windows: los nodos Windows no implementan esta feature.
- La clase QoS no cambia: si tu pod empezó como Burstable, sigue siendo Burstable después del resize. No podés cambiar la clase QoS en caliente.
- Pod-level requests >= suma de container requests: si los contenedores tienen requests individuales definidos, el presupuesto pod-level no puede ser menor que la suma de esos requests. La validación falla antes de llegar al Kubelet.
- Sidecars con
RestartPolicy: Always: los sidecars que siempre se reinician tienen comportamiento propio que puede interactuar de formas inesperadas con el resize.
Ojo: durante el período Beta, el comportamiento puede cambiar entre minor versions. No es GA todavía, así que si tu cluster tiene SLAs muy estrictos, testealo a fondo antes de confiar en él en producción.
In-Place Resize manual vs VerticalPodAutoscaler automático
Hay dos caminos para aprovechar esta feature:
| Característica | Resize manual (kubectl patch) | VPA automático |
|---|---|---|
| Control | Total, vos decidís cuándo y cuánto | Automático según métricas |
| Velocidad de reacción | Manual, latencia humana | Segundos/minutos según config |
| Modo sin reinicio | Depende de resizePolicy | Modo InPlaceOrRecreate en VPA 1.2+ |
| Complejidad de setup | Baja (un patch) | Media (instalar VPA, crear objeto VPA) |
| Recomendaciones | Vos sabés lo que ponés | Basadas en histórico de uso real |
| Riesgo de over-provisioning | Alto si no monitoreás | Bajo con historial suficiente |
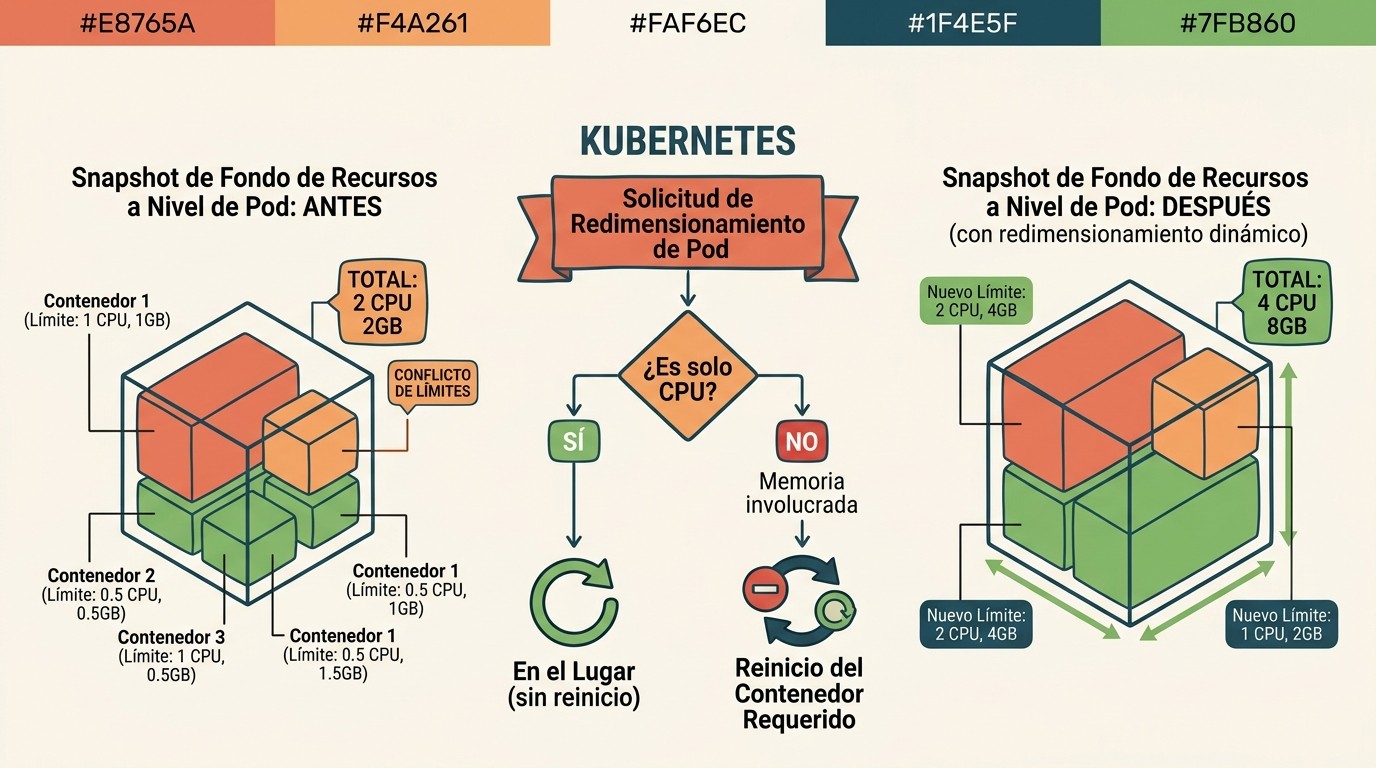
El VPA con modo InPlaceOrRecreate intenta el resize in-place primero; si no es posible, recae en recrear el pod. Esto es útil cuando querés automatización sin sacrificar disponibilidad en los casos donde el resize in-place funciona. Requería VPA 1.2+ según la documentación del VerticalPodAutoscaler.
Para workloads críticos con patrones de tráfico predecibles (por ejemplo, picos diarios a las 10am), el resize manual programado puede ser más predecible que el VPA. Para workloads con tráfico errático, el VPA gana por lejos.
Casos de uso reales: cuándo esto te salva el día
Ponele que tenés un pod de procesamiento de imágenes con un sidecar de nginx que hace proxy y un contenedor principal que pesa mucho en CPU durante ciertos jobs. Con el modelo pod-level, no necesitás definir límites individuales: ponés un budget de 4 CPU en el pod, el contenedor principal usa lo que necesita, nginx toma el resto. Cuando llega un job pesado, expandís el budget a 8 CPU sin reiniciar nada. Complementá con distribuir contenido técnico en múltiples idiomas.
Otro caso concreto: aplicaciones con startup muy lento que se benefician de un “CPU boost” al arrancar. Podés dar 4 CPU al pod durante el inicio (cuando la JVM está compilando, cargando clases, etc.) y después bajarlo a 1 CPU para el estado steady-state, sin recrear el pod. Subís los recursos, esperás que arranque, los bajás. Todo en caliente.
Un tercer escenario que aparece seguido en clusters de microservicios con Istio: el sidecar de Envoy consume recursos variables según el tráfico. Con pod-level resources y resize in-place, podés ajustar el presupuesto total del pod según el tráfico del servicio sin que Envoy necesite su propio límite individual.
Guía práctica: implementar escalado vertical in-place en tu cluster
Si estás en Kubernetes v1.36, el feature gate InPlacePodLevelResourcesVerticalScaling está habilitado por default. No tenés que hacer nada especial para activarlo.
Para un resize manual, el flujo básico es:
- Definí
resizePolicyen cada contenedor del pod spec. Para CPU:NotRequired. Para memory: evaluá si podés tolerar un reinicio de contenedor. - Aplicá el cambio con
kubectl patch pod <nombre> --patch '{"spec":{"resources":{"requests":{"cpu":"2"},"limits":{"cpu":"2"}}'(sintaxis simplificada). - Monitoreá el estado con
kubectl describe pod <nombre>y buscá la secciónResize Status. Los valores posibles sonProposed,InProgress,DeferredoInfeasible. - Si el nodo no tiene recursos disponibles, el resize queda en
Deferredhasta que haya espacio. No falla, espera.
Para el resize automático con VPA, necesitás instalar el componente VPA en tu cluster y crear un objeto VerticalPodAutoscaler apuntando a tu deployment con updateMode: InPlaceOrRecreate. La documentación oficial de Kubernetes tiene los ejemplos actualizados para v1.36.
El flujo de testing recomendado: activalo en un namespace de staging, tirá carga con algo como k6 o locust, observá cómo el Kubelet maneja los eventos de resize, y revisá si hay reinicios inesperados de contenedores. Recién entonces llevalo a producción.
Errores comunes al trabajar con in-place resize
Error 1: asumir que memoria nunca requiere reinicio. CPU casi siempre se puede ajustar in-place. Memoria, dependiendo del OS y la configuración del contenedor, puede requerir reinicio. Si definís resizePolicy: NotRequired para memoria y el Kubelet determina que igual necesita reiniciar, lo va a hacer. Revisá los eventos del pod después de un resize de memoria. Esto se conecta con lo que analizamos en plataformas principales para automatización.
Error 2: confundir VPA con in-place resize manual. VPA es un controlador separado que automatiza las recomendaciones y puede aplicarlas. El in-place resize es el mecanismo que el Kubelet usa para aplicar cambios. VPA puede usar ese mecanismo, pero también puede recrear pods. Si instalás VPA sin configurar InPlaceOrRecreate, probablemente termine recreando pods aunque tu cluster soporte in-place.
Error 3: definir pod-level requests menores a la suma de container requests. Si tus contenedores tienen requests individuales y el pod-level budget es menor que la suma, la validación falla. El pod-level budget es un techo, no un reemplazo de los requests individuales. Revisá los valores con kubectl describe pod antes de hacer el patch.
Error 4: no monitorear el estado del resize. El resize puede quedar en Deferred si el nodo está al límite. Si dejás de monitorear, creés que aplicaste más recursos y en realidad el pod sigue igual. Configurá alertas sobre el campo resizeStatus.
Esto tiene mucho que ver con Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Re, donde cubrimos el tema en detalle.
Esto se conecta con Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Re, donde cubrimos el tema en detalle.
Si querés profundizar en esto, chequeá nuestro artículo sobre Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Re.
Preguntas Frecuentes
¿Qué es el escalado vertical en Kubernetes?
El escalado vertical en Kubernetes es el ajuste de CPU y memoria asignados a un pod existente, en contraste con el escalado horizontal que agrega réplicas. El Vertical Pod Autoscaler (VPA) gestiona este proceso automáticamente; también podés hacerlo manualmente con kubectl patch. Desde Kubernetes v1.35, el escalado vertical a nivel contenedor es GA, y desde v1.36, el ajuste del presupuesto compartido a nivel pod completo está en Beta.
¿Cómo cambiar la memoria de un pod sin downtime?
Para cambiar memoria sin downtime, necesitás que el contenedor tenga resizePolicy: NotRequired para el recurso memoria. Eso indica al Kubelet que intente el cambio sin reiniciar. Pero atención: hay casos donde el OS no puede liberar memoria ya asignada al proceso, y el Kubelet puede igual reiniciar el contenedor si determina que es necesario. Para CPU, NotRequired funciona de forma más consistente. Ya lo cubrimos antes en problemas críticos identificados en GKE.
¿Cuál es la diferencia entre HPA y VPA en Kubernetes?
HPA (Horizontal Pod Autoscaler) escala la cantidad de réplicas de un deployment según métricas de uso. VPA (Vertical Pod Autoscaler) ajusta los recursos (CPU/memoria) de cada pod individual. HPA es mejor para workloads stateless con tráfico variable; VPA es mejor para workloads donde agregar réplicas no soluciona el problema (bases de datos, procesamiento intensivo). Podés usar los dos juntos en algunos escenarios, aunque requiere configuración cuidadosa para evitar que se pisen.
¿Requiere reinicio cambiar CPU en Kubernetes v1.36?
No necesariamente. Si el contenedor tiene resizePolicy: NotRequired para CPU (o no tiene resizePolicy definida, que es el default), el Kubelet aplica el cambio de CPU sin reiniciar el contenedor. Esta es la ventaja principal del in-place resize: ajustar CPU en caliente sin interrumpir el proceso. El Kubelet usa cgroups para actualizar los límites sin tocar el proceso.
¿Cómo funciona el in-place resize con sidecars?
Con el modelo pod-level resources de v1.36, los sidecars sin límites individuales heredan su capacidad efectiva del presupuesto compartido del pod. Cuando expandís el presupuesto pod-level, el Kubelet trata el cambio como un evento de resize para cada contenedor que hereda del pod-level, incluidos sidecars. Si el sidecar tiene resizePolicy: NotRequired, absorbe el cambio sin reiniciarse. Si tenés sidecars con RestartPolicy: Always (sidecars nativos de Kubernetes v1.29+), revisá la documentación de interacción entre ambos features antes de activarlo en producción.
Conclusión
El Kubernetes escalado vertical pods sin reinicio a nivel pod-level es la pieza que faltaba para cerrar el círculo iniciado en v1.33. Con v1.35 el resize por contenedor llegó a GA; con v1.36, el modelo de recursos compartidos del pod entero también puede ajustarse en caliente. Para clusters con pods complejos (sidecars, Istio, apps con múltiples contenedores sin límites individuales), esto simplifica bastante la gestión operativa.
Dicho esto, estamos en Beta. El feature gate está habilitado por default, lo que significa que Kubernetes considera que el mecanismo es suficientemente estable para uso general, pero la API puede cambiar antes de GA. Si lo vas a usar en producción, testéalo bien y configurá alertas sobre el estado de resize.
El próximo paso lógico para la mayoría de los equipos es combinar esto con VPA en modo InPlaceOrRecreate para tener ajuste automático sin interrupciones. Si tu infraestructura corre sobre cloud, los proveedores de VPS y cloud en Argentina como donweb.com ya ofrecen clusters administrados donde este tipo de features se vuelven especialmente útiles para optimizar costos sin sacrificar disponibilidad.
![Kelsey Hightower: Kubernetes and retiring at the top [video] - ilustracion](https://donweb.news/wp-content/uploads/2026/06/kelsey-hightower-retiro-google-kubernetes-hero-768x429.jpg)