Logging centralizado en Node.js con ELK Stack
Centralizar logs de múltiples servicios Node.js con un ELK Stack propio es la diferencia entre debuggear en minutos o pasarte horas haciendo SSH a cada instancia. La arquitectura que propone este setup publicado en junio de 2026 resuelve eso con un Logger Factory no-bloqueante sobre Winston, cloud-agnostic, que funciona incluso en local con solo 512MB de RAM.
En 30 segundos
- El ELK Stack (Elasticsearch, Logstash, Kibana) centraliza logs de todos tus servicios Node.js sin atarte a AWS CloudWatch ni GCP Cloud Logging.
- El Logger Factory usa
winston-elasticsearchpara enviar logs en background sin bloquear el event loop. - Si Elasticsearch cae, el sistema tiene fallback a stdout/stderr para que tu app no se caiga con él.
- Podés correr todo el stack local con solo 512MB de RAM configurando
ES_JAVA_OPTSen Docker. - La configuración es cloud-agnostic: el mismo setup corre en DigitalOcean, AWS, Hetzner o en tu propio servidor.
El problema del logging centralizado en Node.js: SSH + grep no escala
Ponele que tenés tres microservicios corriendo en producción, un error aparece en los logs, y necesitás entender qué pasó. Abrís una terminal, SSH a la instancia A, grep por el request ID, nada. SSH a la instancia B, tampoco. SSH a la instancia C, ahí está, pero el timestamp no coincide con lo que ves en la B. Para cuando encontraste el problema, pasaron 45 minutos.
Eso es el logging distribuido sin centralizar. Es la norma en equipos que arrancaron rápido y nunca pararon a resolver la observabilidad. Y la solución “obvia” de muchos es mandar todo a CloudWatch o Cloud Logging, que te resuelven el problema a cambio de atarte a un proveedor y pagarle para siempre por almacenar tus propios datos.
El ELK Stack es la alternativa que te da control total. Elasticsearch es el motor de búsqueda y almacenamiento de logs; Logstash (o directamente el transporte de Winston) es el pipeline de ingesta; Kibana es el dashboard donde explorás todo. Juntos conforman una solución de logging centralizado Node.js que podés llevar a cualquier cloud o servidor propio.
Cloud-agnostic vs vendor lock-in: por qué importa en 2026
AWS CloudWatch cuesta aproximadamente USD 0.50 por GB ingestado más USD 0.03 por GB almacenado por mes. GCP Cloud Logging tiene estructura similar. No es necesariamente caro si manejás poco volumen, pero el problema real no es el precio.
El problema es que una vez que todos tus microservicios están emitiendo logs formateados para CloudWatch, con sus namespaces específicos, sus retention policies configuradas en la consola de AWS, y tu equipo entrenado en ese dashboard, mover todo cuesta meses. La “comodidad” inicial te pone cadenas que no ves hasta que intentás quitártelas.
Un ELK Stack propio vive en cualquier VPS o instancia cloud. Si mañana decidís migrar de AWS a donweb.com o a cualquier proveedor con infraestructura propia, tus logs vienen con vos. Eso es libertad de datos real.
| Solución | Vendor lock-in | Costo USD/GB ingestado | Portabilidad | Control de datos |
|---|---|---|---|---|
| ELK Stack propio | Ninguno | Solo infraestructura | Total | 100% tuyo |
| AWS CloudWatch | Alto | ~$0.50/GB | Nula | En AWS |
| GCP Cloud Logging | Alto | ~$0.50/GB (primeros 50GB gratis) | Nula | En GCP |
| Cloudflare Logpush | Medio | Incluido en planes Enterprise | Parcial | Limitado |
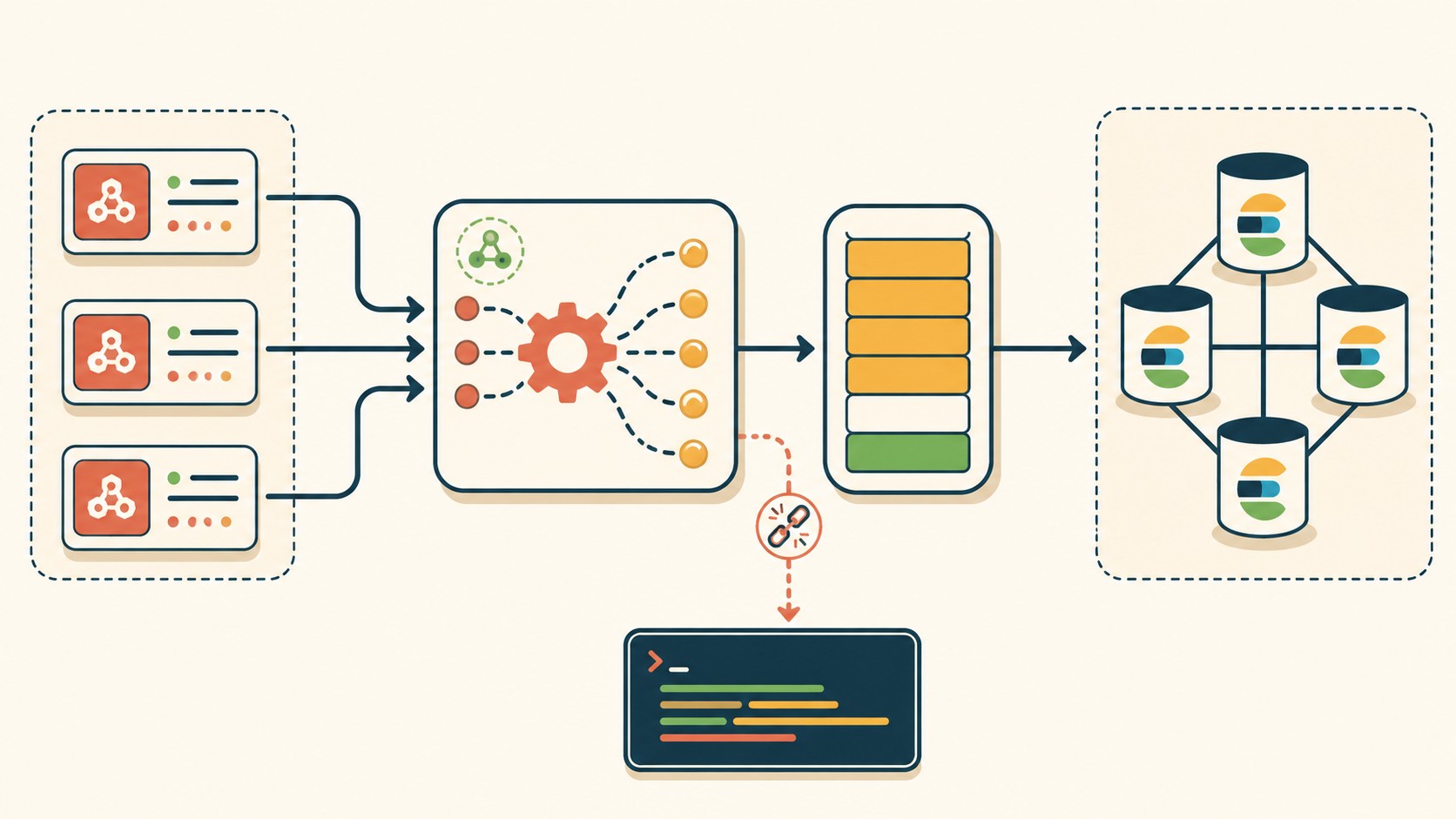
Logger Factory: la arquitectura que separa tu app del transporte
La idea del Logger Factory pattern es simple: tu aplicación no sabe cómo ni adónde van los logs. Llama a logger.info(), logger.error(), y el factory se ocupa del resto. Si mañana cambiás de Elasticsearch a otro backend, no tocás ni una línea de código de negocio. Cubrimos ese tema en detalle en tu pipeline de CI/CD.
En la práctica, el factory crea una instancia de Winston con los transportes configurados y la exporta. El resto de los módulos la importan y usan la interfaz estándar.
Estructura mínima del factory
Un ejemplo concreto con Winston y el transporte de Elasticsearch:
const winston = require('winston');
const { ElasticsearchTransport } = require('winston-elasticsearch');
const esTransportOpts = {
level: 'info',
clientOpts: { node: process.env.ELASTICSEARCH_URL || 'http://localhost:9200' },
indexPrefix: 'app-logs',
flushInterval: 2000, // ms
};
const logger = winston.createLogger({
transports: [
new winston.transports.Console(),
new ElasticsearchTransport(esTransportOpts),
],
});
module.exports = logger;Cada módulo hace const logger = require('./logger') y listo. La infraestructura está encapsulada.
Por qué el logging no-bloqueante es crítico en Node.js
Node.js corre en un único thread. Si tu transporte de logs es síncrono (escribe a disco o a red bloqueando), cada log que generás agrega latencia a todas las requests que están esperando ese thread. En producción con alto volumen, eso mata el performance.
El transporte winston-elasticsearch buffera los logs en memoria y los envía a Elasticsearch de forma asíncrona en background. El flujo es así:
- Tu código llama a
logger.info('request recibida') - Winston pone el log en el buffer interno de
ElasticsearchTransport - El event loop sigue procesando otras requests sin esperar
- Cada
flushIntervalmilisegundos (por defecto 2000ms), el transporte envía el buffer a Elasticsearch en un bulk request
El flushInterval es la variable que más impacta en el balance entre latencia de logs y presión sobre Elasticsearch. Valores bajos (500ms) dan logs casi en tiempo real pero generan más requests. Valores altos (5000ms) son más eficientes pero los logs llegan tarde al dashboard. Para producción, 2000ms es un punto de partida razonable.
Resilience fallback: qué pasa si Elasticsearch se cae
Acá viene lo que casi nadie configura bien y después se arrepiente. Si tu app depende de Elasticsearch para loggear y Elasticsearch tiene un pico de carga o se reinicia, ¿qué pasa con tus logs? ¿Y con tu app?
La respuesta correcta es: los logs caen al fallback (stdout/stderr) y la app sigue corriendo sin enterarse. La respuesta incorrecta (y la que pasa por default si no configurás bien) es que el transporte empieza a tirar errores que se propagan y eventualmente tumban tu proceso. Para más detalles técnicos, mirá al desplegar con tu herramienta elegida.
La configuración de resiliencia mínima:
const esTransportOpts = {
// ...
clientOpts: {
node: process.env.ELASTICSEARCH_URL,
requestTimeout: 3000,
maxRetries: 3,
},
handleExceptions: true,
};
// Fallback explícito si el transporte falla
esTransport.on('error', (error) => {
console.error('Elasticsearch transport error, falling back to console:', error.message);
});¿Y si los reintentos también fallan? Exacto, el log se pierde. Eso es aceptable. Lo que no es aceptable es que tu API de pagos deje de responder porque el cluster de logs está saturado.
ELK local con 512MB de RAM: sí, se puede
Elasticsearch por default intenta usar 1GB de heap mínimo. En una máquina de desarrollo normal eso es un problema. La solución es forzar el límite con la variable de entorno ES_JAVA_OPTS.
Un Docker Compose mínimo para desarrollo local:
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.0
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms256m -Xmx256m
- xpack.security.enabled=false
ports:
- "9200:9200"
kibana:
image: docker.elastic.co/kibana/kibana:8.13.0
ports:
- "5601:5601"
depends_on:
- elasticsearchCon -Xms256m -Xmx256m le estás diciendo a la JVM que use exactamente 256MB de heap. Kibana usa otros ~300MB. Total: andás por los 560MB en el peor caso, dentro del límite de 512MB si tenés swap disponible o si sacrificás un poco del límite de Kibana.
Eso sí: esto es para desarrollo. En producción, Elasticsearch necesita al menos 2GB de heap para un cluster de nodo único con carga real, y 4GB+ para empezar a hablar de performance seria.
Configuración de producción: lo que no podés ignorar
En producción entran otros requisitos. Los más críticos:
Autenticación y TLS
Con xpack.security.enabled=false cualquier persona que llegue al puerto 9200 lee todos tus logs. Eso no puede estar en producción. Activá xpack.security y usá API keys para que cada servicio se autentique con credenciales propias.
Index Lifecycle Management (ILM)
Sin políticas de retención, Elasticsearch acumula logs para siempre. Configurá ILM para que los índices viejos pasen de hot a warm a cold y finalmente se eliminen. Una política típica: 7 días en hot, 30 días en warm, delete al día 90. Kibana tiene un wizard para esto en Stack Management. Esto se conecta con lo que analizamos en consideraciones críticas de privacidad.
Monitoreo del propio Elasticsearch
El cluster de logging también puede fallar. Necesitás métricas sobre el estado del cluster: heap usage, disk usage, index rate, query latency. La documentación oficial de Elastic para Node.js cubre el formato ECS que hace que estos dashboards funcionen out of the box.
Winston vs Pino: cuál usar para logging centralizado en Node.js
Pino es más rápido. En benchmarks publicados por el propio equipo, Pino procesa logs entre 5x y 8x más rápido que Winston en operaciones de alta frecuencia. Si estás loggeando decenas de miles de eventos por segundo, Pino gana.
Winston tiene mejor ecosistema de transportes y es más configurable. El transporte winston-elasticsearch está maduro y mantenido activamente. El equivalente para Pino existe (pino-elasticsearch) pero tiene menos adopción.
Para la mayoría de las aplicaciones Node.js en producción con logging centralizado, Winston es la elección pragmática. Si medís que el logging es un cuello de botella real en tu profiling (no una suposición), ahí tiene sentido evaluar la migración a Pino.
Errores comunes al implementar ELK con Node.js
Usar console.log en producción sin estructura
Los logs de texto libre son imposibles de buscar en Elasticsearch. Si loggéas console.log('Error procesando pago: ' + error.message), no podés filtrar por tipo de error ni agregar métricas. Todo log de producción debería ser JSON estructurado con campos fijos: timestamp, level, service, requestId, message, y opcionalmente el stack trace.
No incluir un request ID en cada log
Sin un ID único por request, es imposible reconstruir la traza de una operación que pasa por múltiples servicios. Generá un UUID al inicio de cada request (en el middleware de entrada) y propagalo en el header X-Request-ID. Cada log de cualquier servicio debe incluir ese ID.
Loggear datos sensibles
Es más común de lo que parece. Un logger.info(req.body) en un endpoint de login manda contraseñas a Elasticsearch. Cualquiera que haya configurado logging rápido para debuggear se topó con esto. Implementá un sanitizador que quite campos como password, token, credit_card antes de loggear cualquier objeto de request. Tema relacionado: monitoreando agentes en local.
Ignorar el flushInterval en producción
El valor por default de winston-elasticsearch es 2000ms. Eso significa que si tu proceso muere abruptamente, perdés hasta 2 segundos de logs. En algunos contextos eso es aceptable; en otros, como debug de errores intermitentes, esos logs son los más valiosos. Ajustá el flushInterval a tu tolerancia real de pérdida de datos.
Esto se conecta con Node.js con ELK Stack, donde cubrimos el tema en detalle.
Para ampliar en estos conceptos, podés consultar nuestro artículo sobre production logging setup.
Preguntas Frecuentes
¿Cómo centralizar logs de múltiples servicios Node.js?
Todos los servicios apuntan al mismo cluster de Elasticsearch usando el transporte de Winston con la misma URL base. Cada servicio incluye su nombre en un campo service del JSON de log. En Kibana podés filtrar por ese campo para ver logs de un servicio específico o combinar todos en una sola vista cronológica.
¿Qué es el ELK Stack y cómo se usa en Node.js?
ELK Stack es la combinación de Elasticsearch (motor de búsqueda y almacenamiento), Logstash (pipeline de ingesta) y Kibana (dashboard de visualización). En Node.js, el camino más directo es saltear Logstash y usar el paquete winston-elasticsearch que envía logs directamente a Elasticsearch desde la aplicación, reduciendo la complejidad de infraestructura.
¿Cómo implementar logging sin bloquear el event loop?
El transporte winston-elasticsearch buffera los logs en memoria y los envía en bulk requests asíncronos cada flushInterval milisegundos (default: 2000ms). El código de la aplicación no espera la confirmación de Elasticsearch, por lo que el event loop queda libre para procesar otras requests. Según este análisis de observabilidad en Node.js, el patrón asíncrono es el estándar recomendado para producción.
¿Cuál es la mejor solución cloud-agnostic para logging en Node.js?
ELK Stack propio es la opción con más control: cero vendor lock-in, datos que viven en tu infraestructura, y costo proporcional solo al servidor que lo corre. Para equipos sin capacidad de operar Elasticsearch, OpenSearch (el fork open source de AWS) con hosting propio en DigitalOcean o Hetzner es una alternativa razonable que mantiene la independencia de proveedor.
¿Cuánta RAM necesita Elasticsearch en producción?
Para desarrollo local, podés forzarlo a 256MB con ES_JAVA_OPTS=-Xms256m -Xmx256m. Para producción con carga real, el mínimo recomendado es 2GB de heap (4GB de RAM en el servidor). Un cluster de nodo único para 10-20 servicios con volumen moderado funciona bien con 4GB de heap y 8GB de RAM total en el servidor.
Conclusión
El logging centralizado en Node.js con ELK Stack resuelve un problema real: cuando algo se rompe en producción, tenés minutos, no horas. La arquitectura del Logger Factory no-bloqueante sobre Winston garantiza que la observabilidad no compita con el performance de la app, y el fallback a stdout asegura que un problema en Elasticsearch no se convierta en un outage de la aplicación.
Lo que hace interesante este setup es que no te obliga a comprometerte con ningún cloud. El mismo Docker Compose que corrés local con 512MB de RAM es el que deployás en cualquier VPS en producción con más recursos. Si tu equipo todavía resuelve los problemas de producción con SSH y grep, este es el momento de cambiar eso.
Fuentes
- Dev.to – Production-Ready Logging: An Agnostic ELK Stack Setup for Node.js
- NPM – winston-elasticsearch: documentación oficial del transporte
- Elastic – ECS Logging para Node.js con Winston
- Medium – Centralized Logging & Tracing para Microservicios
- Medium – Observabilidad en Node.js: métricas, logging y tracing