Mistral Small 4: 128 expertos open source bajo Apache 2.0
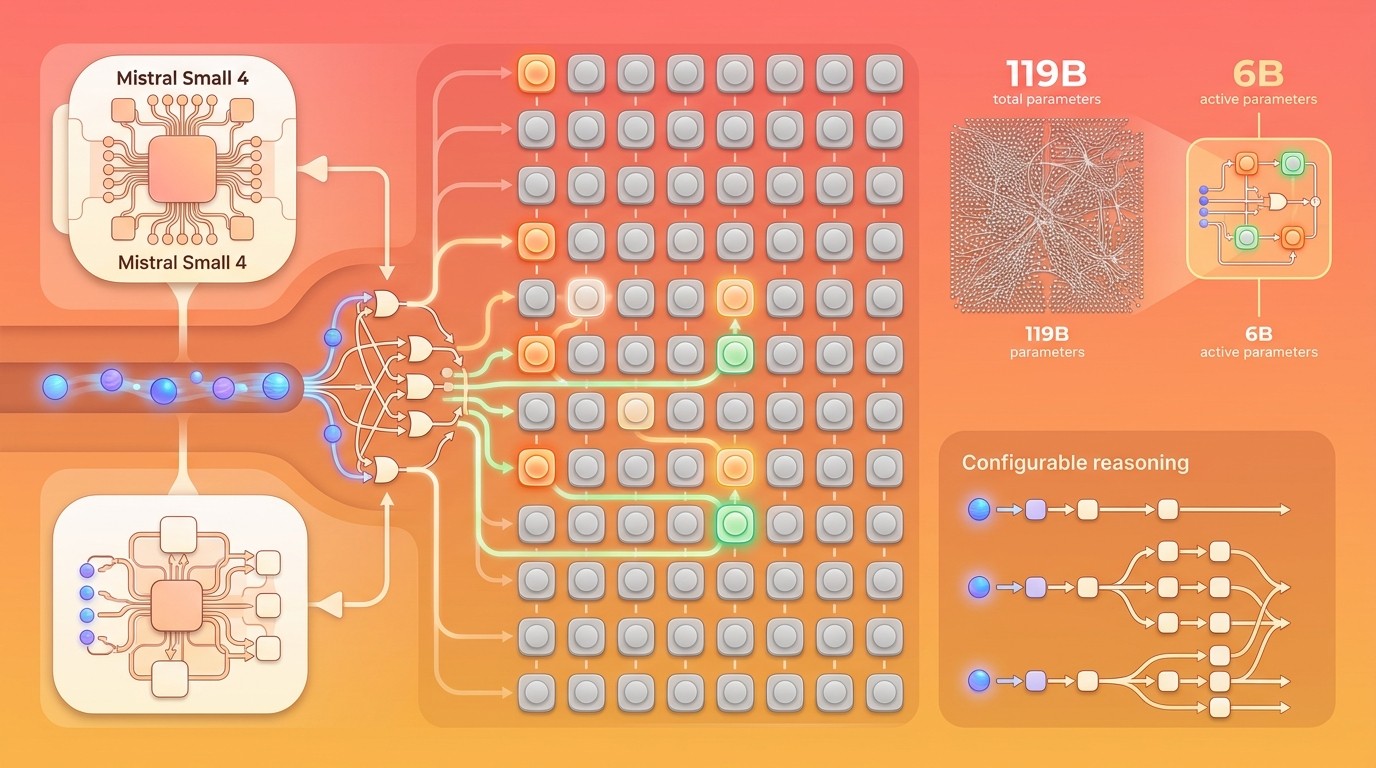
Mistral AI lanzó Mistral Small 4, un modelo open source de 119 mil millones de parámetros con arquitectura Mixture of Experts (128 expertos, 6B activos por inferencia) bajo licencia Apache 2.0. Presentado en la GTC 2026 de NVIDIA, unifica razonamiento, visión y coding en un solo modelo con ventana de contexto de 256K tokens y razonamiento configurable por request.
En 30 segundos
- Mistral Small 4 es un modelo MoE de 119B parámetros totales pero solo 6B activos por token, lo que permite correrlo en hardware más accesible que su tamaño sugiere. Se distribuye bajo Apache 2.0, es decir: uso comercial sin restricciones.
- Unifica tres capacidades que antes requerían modelos separados: razonamiento profundo (Magistral), procesamiento de imágenes (Pixtral) y generación de código (Devstral). Un parámetro
reasoning_effortpermite alternar entre respuestas rápidas y razonamiento paso a paso según la complejidad de cada consulta. - En benchmarks, supera a GPT-OSS 120B con un 20% menos de tokens de salida y logra un score AGLR de 0.72. Comparado con Mistral Small 3, reduce la latencia un 40% y triplica el throughput.
- Junto al modelo, Mistral presentó Forge, una plataforma enterprise para entrenar modelos custom sobre datos propios en colaboración con NVIDIA.
Mistral AI es una empresa francesa de inteligencia artificial, fundada en 2023 por exinvestigadores de Google DeepMind y Meta, que desarrolla modelos de lenguaje abiertos y comerciales para generación de texto, razonamiento y programación.
Mistral Small 4 es un modelo de lenguaje grande con arquitectura Mixture of Experts desarrollado por Mistral AI, que combina 128 módulos especializados para manejar tareas de razonamiento, visión por computadora y generación de código en una sola instancia, con 119B parámetros totales y solo 6B activos por token procesado.
Qué es Mistral Small 4 y por qué importa
Mistral AI eligió la GTC 2026 de NVIDIA —el evento de referencia en infraestructura de IA— para presentar su nueva apuesta open source. Según el anuncio oficial, Mistral Small 4 es el primer modelo de la compañía francesa que unifica las capacidades que antes vivían en tres modelos separados: Magistral (razonamiento), Pixtral (multimodal) y Devstral (coding).
La decisión de publicarlo bajo Apache 2.0 no es menor. A diferencia de licencias más restrictivas como las que usan Meta con Llama (que imponen límites por cantidad de usuarios) o las de algunos modelos chinos con cláusulas de uso aceptable, Apache 2.0 te permite usar, modificar y distribuir el modelo sin restricciones comerciales. Eso incluye startups que quieran integrarlo en productos propios sin pagar regalías ni pedir permiso.
El modelo tiene 119 mil millones de parámetros en total, pero gracias a la arquitectura MoE solo activa 6B por cada token que procesa. Esto cambia radicalmente los requisitos de hardware: no necesitás la infraestructura que demandaría un modelo denso de 119B. La ventana de contexto de 256K tokens le permite procesar documentos extensos de una sola pasada, y el soporte multilingüe cubre más de 24 idiomas, con español incluido.
El posicionamiento estratégico es claro. Mistral apunta al segmento donde los equipos necesitan un modelo capaz pero desplegable on-premise, sin depender de APIs propietarias. Y con la licencia Apache 2.0, eliminan la principal barrera que frenaba la adopción empresarial de modelos open source.
Arquitectura Mixture of Experts: 128 expertos, 6B activos
La arquitectura Mixture of Experts no es nueva, pero Mistral la lleva a un nivel distinto con 128 módulos especializados. Para ponerlo en contexto: la mayoría de los modelos MoE actuales trabajan con 8 a 16 expertos. Tener 128 permite una especialización mucho más granular. Cada experto puede enfocarse en un subconjunto más reducido de tareas o dominios lingüísticos.
El mecanismo funciona así: para cada token que entra al modelo, un router (una red neuronal liviana) selecciona los 4 expertos más relevantes de los 128 disponibles. Solo esos 4 se activan y procesan el token, mientras los otros 124 permanecen inactivos. El resultado es que el costo computacional por token equivale al de un modelo de ~6B parámetros, no de 119B.
¿Por qué importa la cantidad de expertos? Pensalo como la diferencia entre tener 8 empleados generalistas y 128 especialistas. Con 128, el routing puede ser más preciso: un token relacionado con código Python activa expertos distintos a los que se activan para una consulta médica en francés. La granularidad del routing es lo que permite que un modelo “chico” en cómputo activo compita con modelos densos mucho más grandes.
Eso sí: hay un trade-off que no se puede ignorar. Los 119B parámetros siguen necesitando estar en memoria, aunque solo se usen 6B por inferencia. Eso implica que la huella de VRAM es considerable —más sobre esto en la sección de deploy— y que la ventaja real de MoE se nota en throughput y latencia, no tanto en consumo de memoria.
La ventana de contexto de 256K tokens completa el paquete técnico. Podés pasarle documentos de cientos de páginas, repositorios completos de código o conversaciones extensas sin truncamiento. Según MarkTechPost, el modelo mantiene coherencia a lo largo de todo ese contexto gracias a optimizaciones en la capa de atención específicas para arquitecturas MoE.
Razonamiento configurable: de respuesta rápida a pensamiento profundo
Esta es, para mi gusto, la feature más interesante de Mistral Small 4. El parámetro reasoning_effort te permite controlar cuánto “piensa” el modelo antes de responder, y lo hacés por request individual, no a nivel de configuración global.
Los modos disponibles son:
reasoning_effort: "none"— Respuesta directa sin cadena de razonamiento intermedia. Latencia mínima, ideal para tareas simples como clasificación, extracción de datos o respuestas factuales. Se comporta de manera similar a Mistral Small 3.2.reasoning_effort: "low"— Un paso intermedio de razonamiento antes de la respuesta final. Buen balance entre velocidad y calidad para la mayoría de las consultas.reasoning_effort: "high"— Razonamiento paso a paso completo, equivalente a lo que hacía Magistral. Para problemas de matemáticas, lógica compleja, análisis de código o cualquier tarea donde la precisión justifique la latencia extra.
Lo potente de este diseño es que podés usarlo en un pipeline donde las consultas simples (“extraé el email de este JSON”) van con none y las complejas (“analizá este contrato y encontrá cláusulas problemáticas”) van con high, sin cambiar de modelo ni de endpoint. Para la temperatura, Mistral recomienda valores bajos (0.1-0.3) en modo high para mantener consistencia en el razonamiento, y más flexibilidad (0.5-0.8) en modo none para tareas creativas.
Ejemplo concreto: imaginá un chatbot de soporte técnico. Cuando un usuario pregunta “¿cuál es el horario de atención?”, el sistema manda la consulta con reasoning_effort: "none" y responde en milisegundos. Cuando pregunta “tengo un error de CORS al hacer fetch desde mi frontend desplegado en Vercel hacia mi API en un servidor dedicado, ¿cómo lo soluciono?”, el sistema usa reasoning_effort: "high" para analizar el problema paso a paso. Mismo modelo, mismo deploy, distinta profundidad según necesidad.
Capacidades multimodal y coding en un solo modelo
Mistral Small 4 acepta texto e imágenes como input. Podés pasarle una captura de pantalla de un diseño y pedirle que genere el HTML/CSS, o enviarle una foto de un diagrama de arquitectura y que te explique los componentes. Hereda las capacidades de Pixtral para análisis de documentos escaneados, gráficos y tablas.
En el lado de coding, los resultados son sólidos. En LiveCodeBench, supera a GPT-OSS 120B generando un 20% menos de tokens de salida. Esto último es un dato clave: no solo importa la calidad de la respuesta sino cuánto “habla” el modelo para llegar a ella. Menos tokens de salida significa menor costo por consulta y menor latencia.
El function calling nativo con JSON estructurado es otra pieza importante. El modelo puede decidir cuándo llamar a una función externa, generar los argumentos en formato JSON válido y procesar la respuesta, todo sin prompts elaborados ni hacks de parsing. Esto lo hace apto para flujos agénticos donde el modelo necesita interactuar con APIs, bases de datos o herramientas externas. Si te interesa, podes leer mas sobre nuestra guía para integrar la API de Gemini.
Ejemplo concreto: un equipo de desarrollo puede configurar Mistral Small 4 como agente de code review. El modelo recibe un diff de Git, analiza los cambios con reasoning_effort: "high", identifica potenciales bugs o vulnerabilidades, y usa function calling para crear comentarios en el pull request vía la API de GitHub. Todo corriendo en infraestructura propia, sin enviar código propietario a una API externa.
Benchmarks y rendimiento: cómo se compara con la competencia
Los números que publica Mistral pintan bien, pero como siempre con benchmarks del fabricante, conviene mirarlos con cierta distancia hasta que la comunidad los valide de forma independiente.
El dato más llamativo es el score AGLR (Average Generation Length-adjusted Ranking) de 0.72, logrado con un promedio de 1.6K caracteres de salida. Qwen, para alcanzar scores comparables, necesita entre 3.5x y 4x más tokens de salida. Esto sugiere que Mistral Small 4 es más conciso sin sacrificar precisión, lo cual tiene impacto directo en costos y latencia de producción.
| Modelo | Parámetros totales | Parámetros activos | Arquitectura | Contexto | Licencia | AGLR Score | Razonamiento configurable |
|---|---|---|---|---|---|---|---|
| Mistral Small 4 | 119B | 6B (4 de 128 expertos) | MoE | 256K | Apache 2.0 | 0.72 | Sí (por request) |
| GPT-OSS 120B | 120B | ~30B (estimado) | MoE | 128K | Restrictiva | ~0.68 | No |
| Llama 4 Scout | 109B | 17B | MoE | 256K | Llama License | ~0.65 | No |
| Qwen 2.5 72B | 72B | 72B (denso) | Dense | 128K | Apache 2.0 | ~0.70* | No |
*Qwen logra scores similares pero con 3.5-4x más tokens de salida, lo que implica mayor costo y latencia.
Frente a su predecesor, Mistral Small 3, las mejoras son cuantificables: 40% menos latencia y 3x más throughput en condiciones equivalentes de hardware. Eso significa que con la misma infraestructura podés servir el triple de requests por segundo.
Ahora bien, hay que ser honestos. Los benchmarks del fabricante siempre tienden a favorecer al modelo propio. La comparación más objetiva va a llegar cuando la comunidad corra evaluaciones estandarizadas en las mismas condiciones. Lo que sí es verificable es la arquitectura, la licencia y la cantidad de parámetros activos, y esos números son competitivos por donde los mires.
Cómo instalar y desplegar Mistral Small 4 en tu infraestructura
Acá es donde la realidad de un modelo de 119B parámetros se pone concreta. Aunque solo 6B se activan por token, los 119B necesitan estar cargados en memoria para que el routing funcione. Los requisitos mínimos de hardware son:
- 4x NVIDIA H100 (80GB cada una) — La configuración más accesible en data centers actuales
- 2x NVIDIA H200 (141GB cada una) — Menos GPUs, más memoria por unidad
- 1x NVIDIA DGX B200 — Para quien tiene acceso a la última generación
Para el despliegue, Mistral recomienda vLLM como motor de inferencia principal, que ya tiene soporte nativo para la arquitectura MoE del modelo. Otras opciones incluyen llama.cpp (para quienes prefieren C++ y cuantización agresiva), LM Studio (con interfaz gráfica), y SGLang para pipelines más complejos.
Hay una imagen Docker oficial que simplifica el setup. Y para reducir la huella de memoria, Mistral publicó una versión con cuantización NVFP4 que baja los requisitos de VRAM significativamente, a costa de una pérdida marginal de calidad. También incluyen un “eagle head” para speculative decoding, que acelera la generación prediciendo tokens futuros en paralelo.
Los pesos están disponibles en Hugging Face y en NVIDIA NIM. Si no tenés el hardware para correrlo on-premise y buscás una alternativa accesible, Donweb ofrece servidores dedicados y cloud con GPUs que pueden servir como punto de partida para equipos en Latinoamérica que quieran experimentar con este tipo de modelos.
Pasos básicos para un deploy con vLLM:
- Descargá los pesos desde Hugging Face:
huggingface-cli download mistralai/Mistral-Small-4-119B-2603 - Instalá vLLM con soporte MoE:
pip install vllm>=0.7.0 - Levantá el servidor:
vllm serve mistralai/Mistral-Small-4-119B-2603 --tensor-parallel-size 4(ajustá según tu cantidad de GPUs) - El endpoint queda compatible con la API de OpenAI, así que podés apuntar cualquier cliente existente sin cambiar código
Mistral Forge: la apuesta enterprise junto a NVIDIA
Junto al modelo, Mistral presentó Forge, una plataforma que va un paso más allá del fine-tuning tradicional. Según TechCrunch, Forge permite a las empresas entrenar modelos custom sobre sus propios datos desde cero, no solo ajustar un modelo preexistente.
La diferencia es sustancial. Con fine-tuning ajustás el comportamiento de un modelo base. Con RAG le das acceso a información externa en tiempo de consulta. Con Forge, entrenás un modelo que internalizó tu dominio de datos. Para sectores con datos altamente específicos (defensa, telecomunicaciones, espacio) esto puede ser la diferencia entre un modelo que “entiende” tu industria y uno que repite información genérica.
Los partners iniciales incluyen a Ericsson (telecomunicaciones), la Agencia Espacial Europea (ESA), Reply (consultoría IT) y DSO (defensa de Singapur). No son nombres menores: cada uno tiene dominios de datos enormes y altamente especializados que no están bien representados en los datasets de entrenamiento públicos.
Me parece que esta movida posiciona a Mistral de manera inteligente en el mercado enterprise. Mientras OpenAI y Anthropic compiten por vender acceso API y Google apuesta por integrar IA en sus servicios cloud, Mistral ofrece una propuesta distinta: “traé tus datos, usá nuestra plataforma, entrenamos un modelo que es tuyo”. Con el modelo base bajo Apache 2.0 como anzuelo y Forge como producto de monetización, la estrategia tiene coherencia. Reportes ubican a Mistral camino a los $1.000 millones de ARR (ingresos anuales recurrentes), lo que sugiere que el modelo open source + servicios enterprise está funcionando.
Implicaciones para el ecosistema open source de IA
Que un modelo de esta capacidad salga bajo Apache 2.0 marca una tendencia que no se puede ignorar. Hace un año, un modelo con razonamiento configurable, visión y coding de este nivel solo estaba disponible como API propietaria. Hoy lo podés descargar de Hugging Face y desplegarlo en tu infraestructura.
Para startups y equipos chicos, esto cambia la ecuación de costos de forma drástica. Correr un modelo propio tiene un costo fijo de infraestructura, pero elimina los costos variables por token que cobran las APIs de OpenAI, Anthropic o Google. Si tu volumen de consultas es alto, el punto de equilibrio puede llegar rápido. Y con Apache 2.0, no hay letra chica que te limite cuando escalás. Si te interesa, podes leer mas sobre las novedades presentadas en el GTC 2026.
La tendencia de modelos “unificados” también es significativa. Hasta hace poco, un equipo necesitaba un modelo para texto, otro para visión, otro para código y otro para razonamiento. Mantener cuatro modelos en producción es un dolor operativo considerable. Que todo viva en un solo artefacto desplegable simplifica la arquitectura, reduce puntos de falla y baja la barrera de entrada.
El tema es que no todo es color de rosa. Los requisitos de hardware siguen siendo una barrera real. 4x H100 no es algo que cualquier startup tenga en un rack. Las opciones de cuantización ayudan, pero todavía estamos lejos de correr un modelo de esta envergadura en un servidor común. La comunidad ya está trabajando en versiones más agresivamente cuantizadas, y herramientas como Axolotl permiten hacer fine-tuning sobre el modelo base para dominios específicos, lo cual puede mejorar la relación calidad/costo en aplicaciones verticales.
Qué significa para empresas y equipos en Latinoamérica
El soporte para más de 24 idiomas con español incluido es un punto relevante para la región. Históricamente, los modelos open source rendían significativamente peor en español que en inglés. Con 128 expertos especializados, Mistral Small 4 tiene la capacidad de dedicar módulos específicos a idiomas no ingleses, lo cual debería mejorar la calidad de las respuestas en nuestro idioma.
Para empresas latinoamericanas que manejan datos sensibles (fintech, salud, gobierno), la posibilidad de deployar on-premise bajo Apache 2.0 resuelve un problema regulatorio concreto. No necesitás enviar datos de clientes a una API en Estados Unidos. Todo puede correr en tu infraestructura local, bajo tu control.
El costo de las GPUs sigue siendo el elefante en la sala. 4x H100 tiene un precio de lista que supera los USD 120.000. En la nube, el alquiler por hora es más accesible pero se acumula. Equipos que recién arrancan van a seguir dependiendo de APIs, pero para empresas medianas con volumen, la inversión en infraestructura propia empieza a tener sentido económico.
Errores comunes
Creer que 119B parámetros requieren infraestructura de 119B
La confusión más frecuente con modelos MoE es asumir que necesitás la misma potencia de cómputo que un modelo denso del mismo tamaño. En realidad, Mistral Small 4 activa solo 6B parámetros por token. La demanda de cómputo es comparable a un modelo denso de 6-10B. Eso sí: la memoria (VRAM) sí necesita alojar los 119B parámetros completos, porque el router necesita acceso a todos los expertos. No confundas cómputo con memoria.
Usar reasoning_effort “high” para todo
La tentación es obvia: si el modo de razonamiento profundo da mejores resultados, ¿por qué no usarlo siempre? Porque la latencia y el costo se multiplican. Para una clasificación simple o una extracción de datos, reasoning_effort: "none" va a darte la misma calidad en una fracción del tiempo. El valor real está en poder elegir por request. Si mandás todo con high, estás desperdiciando la principal ventaja del modelo.
Asumir que Apache 2.0 significa “sin responsabilidad”
La licencia Apache 2.0 te da libertad de uso, modificación y distribución comercial sin restricciones. Pero no te exime de las regulaciones locales sobre IA (como la EU AI Act en Europa o regulaciones sectoriales en cada país). Que el modelo sea libre no significa que su aplicación lo sea automáticamente. Si lo usás para tomar decisiones que afectan personas (créditos, contratación, diagnósticos), las responsabilidades legales siguen siendo tuyas.
En la misma línea de modelos abiertos que están sacudiendo el mercado, cubrimos cómo Mistral lanza Small 4: modelo open source con 128 expertos b.
Esto se relaciona con Mistral lanza Small 4: modelo open source con 128 expertos b, que muestra cómo el ecosistema open source sigue ganando terreno en IA.
Esto se relaciona con lo que contamos en Mistral lanza Small 4: modelo open source con 128 expertos b, donde analizamos el tema en detalle.
Si te interesa, podes leer mas sobre Mistral lanza Small 4: modelo open source con 128 expertos b.
Esto se conecta directamente con Mistral lanza Small 4: modelo open source con 128 expertos b.
Si te interesa profundizar, tenemos un artículo sobre Mistral lanza Small 4: modelo open source con 128 expertos b.
Si querés profundizar en esto, tenemos un artículo sobre Mistral lanza Small 4: modelo open source con 128 expertos b.
Preguntas Frecuentes
¿Qué es Mistral Small 4 y qué lo diferencia de otros modelos open source?
Mistral Small 4 es un modelo de lenguaje con arquitectura Mixture of Experts (128 expertos, 6B activos) que unifica razonamiento, visión y coding en un solo artefacto bajo licencia Apache 2.0. Lo que lo diferencia es la combinación de razonamiento configurable por request, 256K tokens de contexto y una arquitectura MoE con más expertos que cualquier otro modelo open source comparable.
¿Qué hardware necesito para correr Mistral Small 4 en mi servidor?
El mínimo recomendado es 4x NVIDIA H100 (80GB cada una), 2x H200, o 1x DGX B200. Existen versiones cuantizadas en NVFP4 que reducen los requisitos de VRAM, pero seguís necesitando hardware con GPUs de datacenter. No es viable en GPUs consumer como RTX 4090 en su versión completa.
¿Mistral Small 4 es realmente gratis para uso comercial?
Sí. La licencia Apache 2.0 permite uso comercial sin restricciones, sin regalías y sin necesidad de solicitar permisos. Podés integrarlo en productos, servicios y aplicaciones comerciales. El costo real es la infraestructura para correrlo, no el modelo en sí.
¿Cómo se compara Mistral Small 4 con GPT-4o y Llama 4?
Frente a GPT-OSS 120B (el modelo open source de referencia de OpenAI), Mistral Small 4 logra resultados superiores en LiveCodeBench con un 20% menos de tokens de salida. Frente a Llama 4 Scout (109B), tiene más expertos (128 vs 16), menos parámetros activos (6B vs 17B) y licencia más permisiva (Apache 2.0 vs Llama License). GPT-4o, al ser propietario, sigue ofreciendo ventajas en ciertos benchmarks, pero no se puede desplegar on-premise.
Conclusión
Mistral Small 4 cambia la ecuación en modelos open source al demostrar que es posible unificar razonamiento, visión y coding en un solo artefacto desplegable bajo una licencia genuinamente libre. El razonamiento configurable por request es probablemente la feature más práctica del modelo: elimina la necesidad de mantener múltiples endpoints para distintos niveles de complejidad.
Lo que queda por verse es cómo se comporta en evaluaciones independientes más allá de los benchmarks del fabricante, y cuánto tarda la comunidad en producir versiones cuantizadas que bajen la barrera de hardware. Si los resultados se sostienen, Mistral Small 4 va a ser difícil de ignorar para cualquier equipo que esté evaluando modelos para producción.
Para los próximos días, lo que conviene seguir de cerca: los primeros benchmarks independientes en el Hugging Face Open LLM Leaderboard, las versiones cuantizadas de la comunidad (especialmente GGUF para llama.cpp), y los primeros reportes de producción sobre latencia real y estabilidad en despliegues multi-GPU.
Fuentes
- Mistral AI – Anuncio oficial de Mistral Small 4
- Hugging Face – Repositorio oficial con pesos y documentación del modelo
- MarkTechPost – Análisis técnico de la arquitectura MoE y benchmarks
- TechCrunch – Cobertura de Mistral Forge y la estrategia enterprise
- The Decoder – Análisis de rendimiento y comparativa con la competencia





