Patrones de arquitectura en Kubernetes: cuándo usar cada uno
Los patrones de arquitectura en Kubernetes son soluciones reutilizables para problemas que aparecen una y otra vez al correr aplicaciones en un cluster: cómo replicar, cómo separar responsabilidades, cómo manejar estado y cómo elegir quién coordina. Conocerlos te ahorra meses de prueba y error. Acá tenés cuándo usar cada uno, con YAML y casos reales.
Un patrón de arquitectura en Kubernetes es una forma probada de combinar sus primitivas (Pod, Deployment, StatefulSet, sidecars, probes) para resolver un requisito concreto de una aplicación distribuida. No es una herramienta nueva: es la manera correcta de usar las que ya tenés. Sirve a cualquier equipo que despliegue servicios sobre un cluster y quiera que escalen sin romperse.
En 30 segundos
- Pod es la unidad mínima de despliegue; puede tener uno o varios contenedores que comparten red y volúmenes.
- Deployment es para apps sin estado: maneja rolling updates y rollback automático sobre un ReplicaSet.
- StatefulSet es para apps con estado: da nombres estables (db-0, db-1) y un PersistentVolume por réplica.
- Sidecar y Ambassador meten contenedores auxiliares en el Pod para logging, config o proxy, sin tocar la app principal.
- Liveness y Readiness son dos probes distintas y las dos hacen falta: una reinicia, la otra controla el tráfico.
¿Cuándo usar cada patrón de arquitectura de Kubernetes?
La pregunta que casi nadie se hace antes de escribir el primer YAML: ¿esta app tiene estado o no? Eso define la mitad de las decisiones. La otra mitad la define si necesitás meter funciones auxiliares (logs, métricas, proxy) sin contaminar el código de tu aplicación.
Te dejo una matriz para decidir rápido, según lo que estés corriendo.
| Necesito… | Patrón | Por qué |
|---|---|---|
| Correr N réplicas idénticas de una app web/API sin estado | Deployment | Rolling updates, rollback y autoscaling sobre ReplicaSet |
| Una base de datos, cola o cluster con identidad por réplica | StatefulSet | DNS estable y volumen propio por Pod |
| Recolectar logs o sincronizar config sin tocar la app | Sidecar | Contenedor auxiliar en el mismo Pod, volumen compartido |
| Abstraer el acceso a un servicio externo | Ambassador | Proxy local que unifica la interfaz; la app habla a localhost |
| Que solo una instancia procese una tarea a la vez | Leader Election | Lease API de coordination.k8s.io evita trabajo duplicado |
| Tráfico avanzado (canary, mTLS, circuit breaking) | Service Mesh | Istio o Linkerd, solo si lo justifica la complejidad |
Fundamentos: Pod, ReplicaSet y Deployment
El Pod es la base de todo. Según la documentación oficial de Kubernetes, un Pod es la unidad mínima desplegable y puede contener uno o varios contenedores que comparten red, almacenamiento y ciclo de vida. La regla general es un contenedor por Pod, salvo que tengas contenedores tan acoplados que tenga sentido juntarlos.
Ahora bien, casi nunca creás Pods sueltos. ¿Por qué? Porque si el nodo se cae, el Pod se va con él y no vuelve. Para eso está el ReplicaSet, que mantiene viva una cantidad fija de réplicas.
El tema es que el ReplicaSet tampoco se usa solo. Lo envolvés en un Deployment, que es el objeto que de verdad vas a escribir. Como explica la guía de Deployments, este maneja actualizaciones declarativas: cambiás la imagen, Kubernetes reemplaza los Pods de a poco (rolling update) y, si algo sale mal, hacés rollback a la versión anterior con un comando.
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
selector:
matchLabels: { app: web }
template:
metadata:
labels: { app: web }
spec:
containers:
- name: web
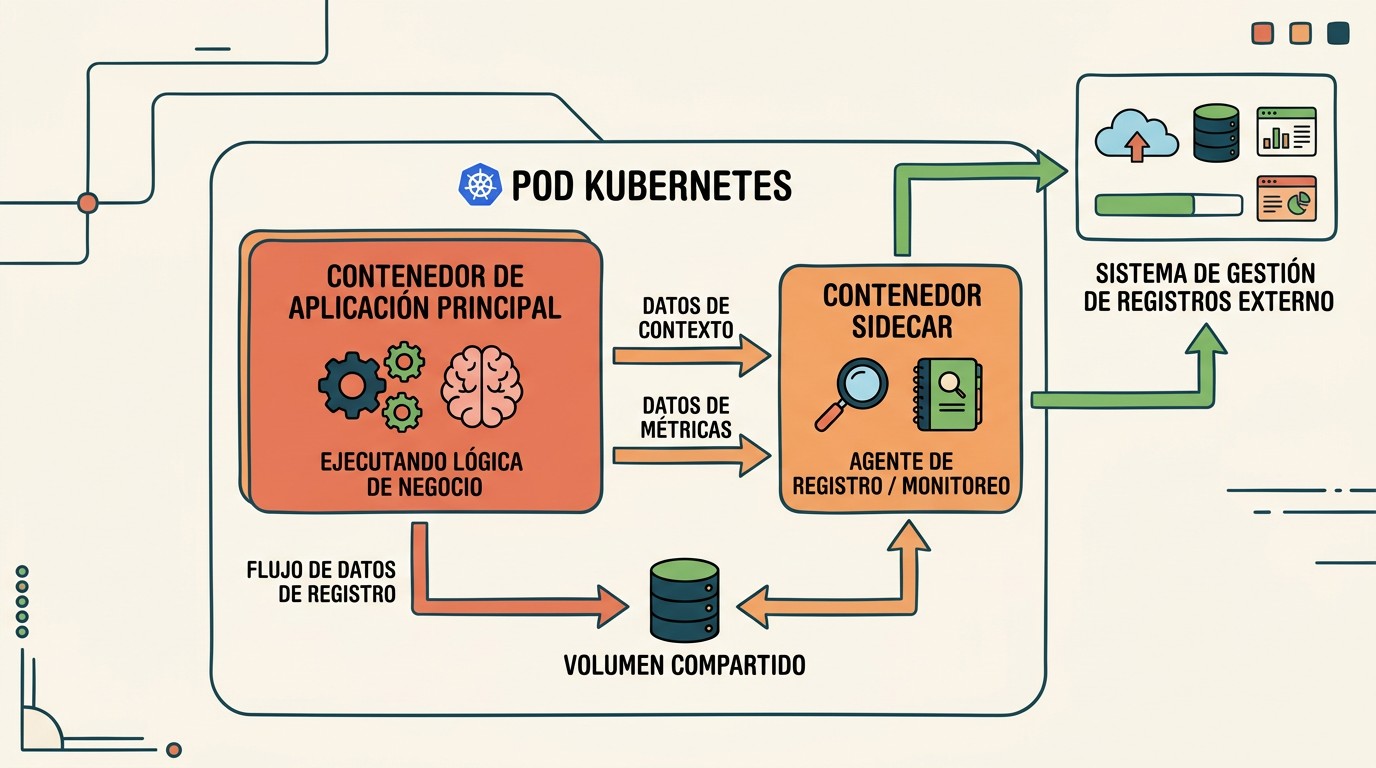
image: nginx:1.27¿Cómo implementar el patrón Sidecar en Kubernetes?
Ponele que tu app escribe logs a un archivo y vos querés mandarlos a un sistema central, pero no querés meter el cliente de logging dentro del código de la app. Ahí entra el Sidecar. Esto se conecta con lo que analizamos en implementar pipelines de CI/CD efectivos.
La idea es simple: metés un segundo contenedor en el mismo Pod que se ocupa de la función auxiliar. Comparten un volumen, así que uno escribe y el otro lee.
- Recolección de logs: un contenedor Fluentd lee el volumen donde la app deja sus archivos y los envía afuera.
- Sincronización de config: un sidecar de tipo config-loader actualiza la configuración sin reiniciar el contenedor principal.
- Monitoreo: un exporter expone métricas de la app en un puerto aparte.
La ventaja grande es la reutilización: el mismo sidecar de Fluentd lo enchufás en diez aplicaciones distintas sin tocar el código de ninguna. La app no sabe ni le importa que ese contenedor exista.
¿Cómo usar el patrón Ambassador para abstraer servicios externos?
El Ambassador es primo del Sidecar, pero con otro objetivo. Acá el contenedor auxiliar es un proxy: tu aplicación habla con localhost:8080 y el proxy se encarga de llegar al servicio externo real, con failover, reintentos o lo que necesites.
¿Para qué sirve esto en la práctica? Para unificar interfaces. Si mañana cambiás el servicio externo (otra base de datos, otro endpoint), tocás el Ambassador y la app ni se entera. El código de la aplicación siempre apunta al mismo localhost.
Es el mismo razonamiento que el patrón Facade en software: una capa que esconde la complejidad de lo que hay detrás. Si alguna vez configuraste un proxy para abstraer credenciales o endpoints, ya entendiste la lógica. Para más detalles técnicos, mirá elegir la herramienta de automatización correcta.
Elección de líder en sistemas distribuidos: Leader Election
Acá viene un problema clásico. Corrés tres réplicas de un worker que procesa una cola, y de repente las tres agarran el mismo trabajo. Resultado: tareas duplicadas, datos pisados, dolor de cabeza.
La solución es elegir un líder. Una sola instancia procesa, las otras quedan en standby listas para tomar el relevo si el líder se cae. Kubernetes resuelve esto con la Lease API del grupo coordination.k8s.io/v1: las instancias compiten por un objeto Lease y la que lo gana es el líder, con un tiempo de renovación que define cada cuánto reafirma su título.
Si el líder deja de renovar el Lease (porque murió), otra instancia lo toma. Es el mismo mecanismo que usan los propios componentes del control plane de Kubernetes para no pisarse entre réplicas.
¿Cuándo usar StatefulSet para aplicaciones con estado?
Cuando tu aplicación necesita recordar quién es cada réplica, el Deployment no te sirve. Necesitás un StatefulSet.
La diferencia, según la documentación de StatefulSet, es que cada Pod recibe un nombre estable y predecible (db-0, db-1, db-2) y una identidad de red que sobrevive a los reinicios. Cada réplica obtiene además su propio PersistentVolume, que no se comparte con las demás.
- Bases de datos: PostgreSQL, MongoDB o Cassandra, donde db-0 puede ser el primario y los demás réplicas.
- Colas y brokers: sistemas como Kafka, donde cada nodo tiene una identidad fija dentro del cluster.
- Escalado ordenado: los Pods se crean y se eliminan en orden, no todos a la vez como en un Deployment.
Eso sí: el StatefulSet es más exigente de operar. Si tu app no necesita identidad estable ni almacenamiento por réplica, usá un Deployment y listo. No te compliques. En documentar componentes para múltiples entornos profundizamos sobre esto.
Probes de salud: Liveness y Readiness en Kubernetes
Las dos probes más malentendidas del ecosistema. Y mezclarlas te puede tirar abajo un servicio en producción.
- Liveness probe: responde a “¿está vivo el contenedor?”. Si falla, Kubernetes reinicia el contenedor. Sirve para detectar deadlocks o procesos colgados.
- Readiness probe: responde a “¿puede recibir tráfico?”. Si falla, Kubernetes saca al Pod del Service Endpoint, así que deja de recibir requests, pero no lo reinicia.
La distinción crítica: si tu app tarda 30 segundos en arrancar y solo configurás liveness, Kubernetes la va a matar antes de que termine de iniciar, y vas a entrar en un loop de reinicios eterno. La readiness existe justo para cubrir ese arranque lento. Las dos hacen falta, no es una o la otra.
livenessProbe:
httpGet: { path: /healthz, port: 8080 }
initialDelaySeconds: 15
readinessProbe:
httpGet: { path: /ready, port: 8080 }
initialDelaySeconds: 5Sumale a esto los resource requests y limits. Definir cuánta CPU y memoria pide cada contenedor no es opcional: sin requests, el scheduler ubica Pods a ciegas y terminás con nodos saturados.
Avanzado: Service Mesh con Istio y Linkerd
El Service Mesh es la artillería pesada, y por eso mismo hay que pensarlo dos veces. Un mesh como Istio o Linkerd te da gestión de tráfico (canary releases, circuit breaking), seguridad con mTLS automático entre servicios, y observabilidad sin tocar tu código.
La comparación corta entre los dos grandes:
- Istio: más features y más control fino, a cambio de más complejidad operacional.
- Linkerd: más simple y liviano, pensado para equipos que quieren mTLS y métricas sin un máster en configuración.
La advertencia honesta: un Service Mesh agrega un proxy por cada Pod y una capa de configuración que alguien tiene que mantener. Si no necesitás canary, mTLS o circuit breaking, te estás metiendo en un quilombo operativo para nada. Usalo solo cuando esas features avanzadas te resuelvan un problema real. Más contexto en ejecutar servicios descentralizados en tu cluster.
Errores comunes al aplicar patrones en Kubernetes
- Usar Deployment para una base de datos: sin identidad estable ni volumen por réplica, vas a corromper datos. Para estado, StatefulSet.
- Configurar solo liveness y olvidar readiness: apps de arranque lento entran en loop de reinicios. Las dos probes, siempre.
- Meter Service Mesh “por las dudas”: sumás complejidad y latencia sin necesidad. Si no usás sus features, no lo instales.
- Correr Pods sueltos: sin un controlador que los respalde, un nodo caído se lleva tu app y no vuelve.
Si vas a desplegar todo esto, el cluster necesita una base de infraestructura sólida. Para hosting y servidores en Argentina podés mirar donweb.com, que es una opción local para el origin de tus servicios.
Preguntas Frecuentes
¿Cuál es la diferencia entre Deployment y StatefulSet?
Deployment es para aplicaciones sin estado donde las réplicas son intercambiables, con rolling updates y rollback automático. StatefulSet es para apps con estado: da nombres estables (db-0, db-1), identidad de red persistente y un PersistentVolume propio por réplica. Bases de datos y colas van con StatefulSet.
¿Qué patrón de arquitectura debo usar en Kubernetes?
Depende de dos preguntas: si tu app tiene estado y si necesitás funciones auxiliares. App sin estado, Deployment. App con estado, StatefulSet. Logging o config sin tocar el código, Sidecar. Acceso a servicios externos, Ambassador. Evitar trabajo duplicado entre réplicas, Leader Election.
¿Qué son las probes de salud en Kubernetes?
Son chequeos que hace Kubernetes sobre cada contenedor. La liveness probe verifica si el contenedor está vivo y lo reinicia si falla. La readiness probe verifica si puede recibir tráfico y lo saca del Service Endpoint si falla, sin reiniciarlo. Las dos son necesarias.
¿Cómo implementar el patrón Sidecar con Fluentd?
Metés un contenedor Fluentd en el mismo Pod que tu aplicación y compartís un volumen entre ambos. La app escribe sus logs en ese volumen y el sidecar de Fluentd los lee y los envía a un sistema central. La app no necesita ningún cambio en su código.
¿Cuándo conviene usar un Service Mesh como Istio?
Solo cuando necesitás features avanzadas: canary releases, circuit breaking, mTLS automático entre servicios u observabilidad detallada. Istio agrega un proxy por Pod y complejidad operacional, así que si no usás esas capacidades, no compensa instalarlo. Linkerd es la alternativa más simple.
Conclusión
Kubernetes te da primitivas potentes, pero el valor está en saber combinarlas. La decisión de fondo casi siempre es la misma: ¿tu app tiene estado o no? De ahí salen el 80% de las elecciones entre Deployment y StatefulSet, y el resto lo resolvés con sidecars, probes bien configuradas y, solo si de verdad lo necesitás, un service mesh.
Empezá simple. Un Deployment con liveness y readiness bien puestas cubre la mayoría de los casos. Sumá complejidad solo cuando un problema concreto te la pida, no antes. Esa es la diferencia entre un cluster que escala tranquilo y uno que se cae cada vez que actualizás.
![Open System Firmware: Experiences deploying LinuxBoot, coreboot at Google (2021) [video] - ilustracion](https://donweb.news/wp-content/uploads/2026/06/linuxboot-coreboot-firmware-abierto-google-hero-768x432.jpg)