Infraestructura inmutable: por qué reemplazar servidores
La infraestructura inmutable es un modelo de gestión de servidores donde ningún servidor se modifica después del deployment: si algo cambia, se construye una imagen nueva y se reemplaza el servidor existente. No hay parches en caliente, no hay SSH a producción para “un arreglito rápido”. El resultado es un entorno predecible, auditable y libre del problema conocido como configuration drift.
En 30 segundos
- La infraestructura inmutable prohíbe modificar servidores en producción: cada cambio genera una imagen nueva que reemplaza la anterior.
- El configuration drift es el enemigo principal de los deployments tradicionales: servidores que deberían ser idénticos terminan siendo todos distintos.
- El flujo básico tiene 4 pasos: empaquetar imagen, crear infraestructura nueva, validar, reemplazar la anterior.
- Docker y Kubernetes son las herramientas más usadas hoy para implementar este patrón a escala.
- Infrastructure as Code (Terraform, CloudFormation) es el habilitador clave: sin IaC, la inmutabilidad no escala.
El problema de los servidores “copo de nieve”
Ponele que tenés tres servidores de producción que deberían ser idénticos. Hace seis meses, alguien entró a server-02 a “corregir un problema urgente” y cambió un parámetro de configuración. Dos semanas después, otra persona actualizó una librería en server-03 porque “era necesario para una prueba”. Hoy, los tres servidores parten del mismo playbook de Ansible, pero en la práctica son tres bichos distintos.
Eso es configuration drift: la divergencia progresiva entre el estado real de un servidor y su estado esperado. No pasa de golpe. Pasa de a poco, cambio a cambio, hasta que un día algo explota y nadie sabe exactamente por qué, porque ningún servidor es igual al otro.
¿Por qué esto importa? Porque hace que los deployments sean impredecibles. “Funciona en dev pero no en prod” suele ser drift disfrazado de bug.
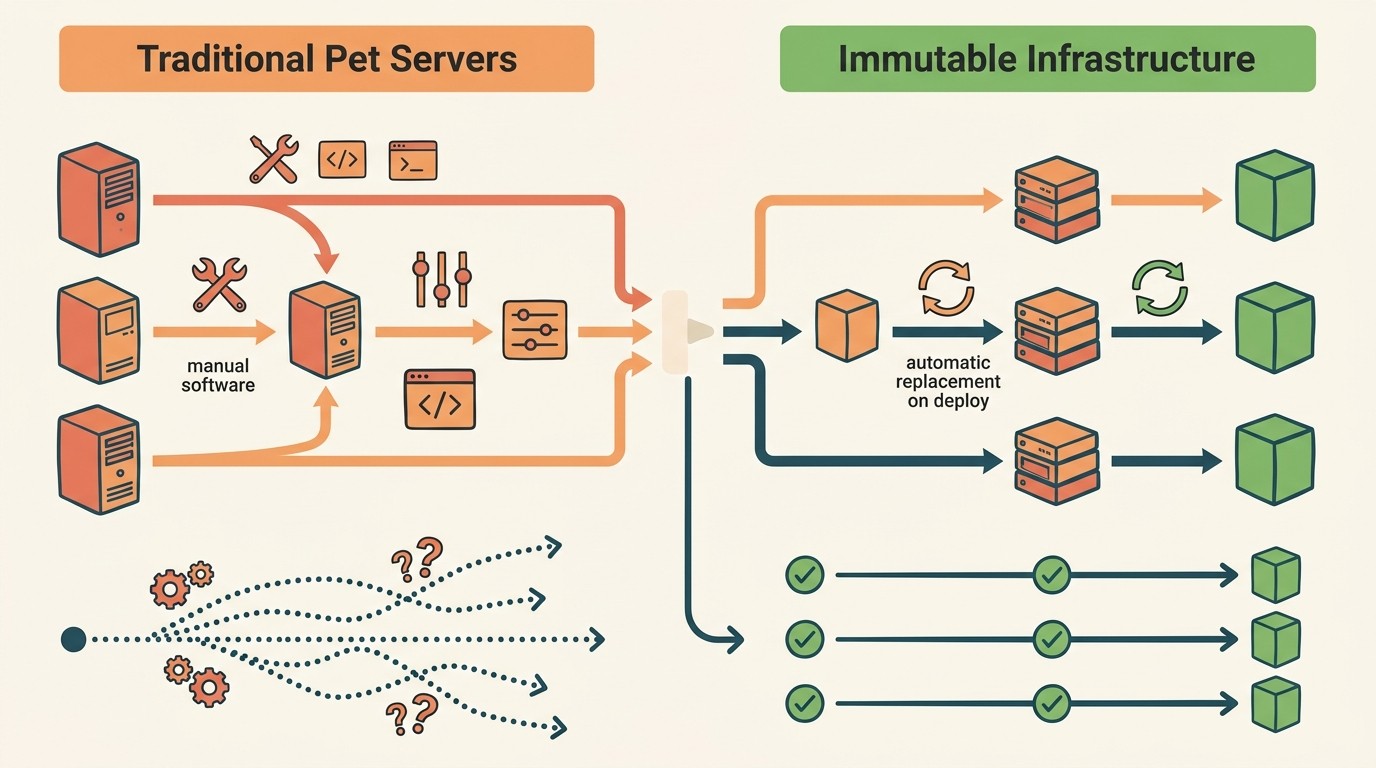
Ganado vs mascotas: el cambio de mentalidad que lo explica todo
La metáfora que mejor describe la diferencia viene de la comunidad DevOps y es bastante directa.
Servidores mascota: los nombrás (“prod-web-01”, “bbdd-principal”), los conocés, cuando se rompen los curás, les hacés mantenimiento preventivo y los tratás como individuos. Si uno falla, es una emergencia. Tenés que diagnosticar, reparar, volver a levantar. El problema es que cada intervención los hace un poquito distintos al resto.
Servidores ganado: son numerados, idénticos y reemplazables. Si uno falla, lo tirás y levantás otro desde la misma imagen base. No hay drama ni diagnóstico prolongado. El nuevo servidor arranca en el estado exacto en que debería estar, porque parte de la misma imagen que todos los demás. Como explicamos en nuestra guía de Docker, esto asegura consistencia total.
Suena brutal, pero es lo que hace tu entorno predecible. Cuando todos los servidores parten del mismo punto de partida, los bugs son reproducibles y los deployments no tienen sorpresas.
Cómo funciona un deployment inmutable: los 4 pasos
Según el análisis publicado en Dev.to en mayo de 2026, el flujo de un deployment inmutable tiene cuatro etapas coordinadas:
- Empaquetar: tu aplicación, sus dependencias y toda la configuración van dentro de una imagen (container Docker, VM image). Todo junto, nada suelto.
- Crear infraestructura nueva: partiendo de esa imagen, se levanta un servidor o conjunto de servidores nuevo. El entorno viejo sigue corriendo sin tocar.
- Validar: se corren los health checks y tests contra el entorno nuevo, antes de que reciba tráfico real.
- Reemplazar: si todo pasa, el tráfico se redirige al nuevo entorno y el viejo se da de baja. Si algo falla, el viejo sigue activo y el rollback es instantáneo.
La clave está en el orden: primero construís, después validás, después reemplazás. Nunca al revés.
Beneficios concretos en producción
La consistencia es el beneficio más obvio: si todos los servidores parten de la misma imagen, el estado de producción es predecible. Sin embargo, hay otros beneficios menos evidentes que terminan siendo igual de importantes.
Recuperación rápida. Un servidor roto no se repara, se reemplaza. En Kubernetes, por ejemplo, reemplazar un pod que falló tarda segundos, no minutos de diagnóstico. En un entorno mutable, primero tenés que entender qué cambió antes de poder arreglarlo.
Reducción de superficie de ataque. Si los servidores no tienen acceso SSH abierto para modificaciones manuales, hay un vector de ataque menos. La documentación del AWS Well-Architected Framework marca explícitamente la infraestructura inmutable como una práctica de confiabilidad precisamente porque elimina la necesidad de acceso operativo a instancias en producción.
Rollback trivial. Volvés a la imagen anterior y listo. No hay que deshacer parches ni recordar qué cambió. La imagen anterior existe, el rollback es tan rápido como el deployment. De manera similar a los incidentes que analizamos en GitHub, la velocidad de recuperación marca la diferencia en disponibilidad.
Configuration drift: cómo destruye tus deployments sin que te des cuenta
El drift no es un evento único. Es acumulativo y silencioso.
Empieza con algo pequeño: un developer entra a producción para debuggear un problema urgente, cambia un valor en un archivo de configuración y “lo va a documentar después” (spoiler: no lo documenta). Tres semanas más tarde, otro cambio manual. Un mes después, una actualización parcial de paquetes en un servidor que no se aplicó en los demás. Al cabo de seis meses, server-01 y server-03 deberían ser idénticos pero tienen comportamientos distintos en carga alta, y nadie puede explicar por qué.
¿Alguien tiene un registro completo de todos esos cambios manuales? Casi nunca.
El drift es la razón por la que “funciona en staging pero no en prod” es un clásico: staging no tuvo los mismos cambios manuales que prod. Con infraestructura inmutable, esa frase deja de existir porque ambos entornos parten de la misma imagen.
Infrastructure as Code: sin esto no hay inmutabilidad real
La infraestructura inmutable sin IaC es marketing. Para que funcione de verdad, toda la infraestructura tiene que estar definida en archivos de código versionados: Terraform, CloudFormation, manifiestos de Kubernetes. Eso es lo que garantiza que podés reproducir exactamente el mismo entorno en cualquier momento.
Las ventajas del IaC en este contexto son concretas:
- Auditoría completa: cada cambio de infraestructura pasa por un pull request. Hay historial, hay revisión, hay contexto.
- Reproducibilidad garantizada: si necesitás levantar el mismo entorno en otra región, corrés el mismo código.
- Detección temprana de drift: herramientas como
terraform planmuestran la diferencia entre el estado declarado y el estado real antes de aplicar cambios.
El punto es que IaC convierte la infraestructura en algo tan versionable como el código de tu aplicación. Si el servidor tiene que cambiar, el cambio va al repositorio, pasa por revisión y genera una nueva imagen. No hay atajos.
Implementación práctica: Docker, Kubernetes y más allá
El punto de entrada más común hoy es Docker. Según la documentación oficial de Docker, la inmutabilidad es un concepto central de los contenedores: una imagen Docker es por definición inmutable una vez construida. Si necesitás cambiar algo, construís una imagen nueva con una tag diferente.
Con Docker
El flujo básico: escribís un Dockerfile que define exactamente el estado de tu aplicación, construís la imagen (docker build), la publicás en un registry y la deployás. Cada deploy es una imagen nueva con su propia tag. La anterior sigue disponible para rollback. Ya lo cubrimos antes en con las mejores prácticas de hosting moderno.
Con Kubernetes
Kubernetes lleva esto a otra escala. Los deployments de Kubernetes usan rolling updates por defecto: levanta pods nuevos desde la imagen nueva, espera a que estén healthy, después elimina los viejos. Si algo falla, kubectl rollout undo revierte al estado anterior en segundos. El cluster nunca tuvo que modificar un pod existente.
VM images con Packer
Para quienes trabajan con VMs en vez de contenedores, HashiCorp Packer hace lo mismo pero para imágenes de máquinas virtuales. Definís la imagen en un archivo de configuración, la construís una vez y la usás para todas las instancias. Mismo principio, diferente abstracción.
En cualquier caso, si estás buscando infraestructura cloud para correr estos entornos, donweb.com tiene opciones de cloud y VPS que se integran bien con flujos IaC estándar.
Comparativa: infraestructura mutable vs inmutable
| Aspecto | Infraestructura mutable | Infraestructura inmutable |
|---|---|---|
| Actualización | Parche en servidor existente | Imagen nueva, servidor nuevo |
| Rollback | Deshacer cambios manualmente | Volver a imagen anterior |
| Configuration drift | Frecuente y difícil de detectar | Imposible por diseño |
| Debugging en producción | SSH directo al servidor | Logs y observabilidad, sin SSH |
| Reproducibilidad | Baja (depende del historial de cambios) | Alta (imagen versionada) |
| Velocidad de rollback | Variable (minutos a horas) | Segundos |
| Complejidad inicial | Baja | Media-alta (requiere IaC + pipeline) |
| Mantenimiento a largo plazo | Costoso y propenso a errores | Predecible y auditable |
Errores comunes al implementar infraestructura inmutable
Meter estado dentro de la imagen
La imagen debe ser stateless. Si guardás datos de usuarios, sesiones o configuraciones que cambian en tiempo de ejecución dentro de la imagen, rompés todo el modelo. El estado tiene que ir afuera: bases de datos externas, object storage, variables de entorno inyectadas al momento del deploy. Una imagen con estado mutable adentro no es inmutable, es un desastre con buena presentación.
No versionar las imágenes correctamente
Usar siempre la tag latest es uno de los errores más comunes y más peligrosos. Si hacés rollback a latest y alguien ya reemplazó esa tag con una imagen nueva, el rollback no lleva donde creés. Cada imagen que va a producción necesita una tag inmutable: el hash del commit, la versión semántica, una combinación de ambas. Lo que no cambie.
Ignorar la estrategia de deploy
Levantar la imagen nueva y bajar la vieja al mismo tiempo es un corte de servicio garantizado. Blue-green deployment (dos entornos en paralelo, cambio de tráfico instantáneo) o rolling update (reemplazar instancias de a una) son las estrategias estándar. Elegir cuál depende del caso de uso, pero ninguna de las dos puede ser “apagar y prender”. Relacionado: cuando se trata de seguridad en infraestructura.
Podés ver más detalles en Understanding immutable infrastructure patterns: when server.
Podés profundizar en esto en nuestro artículo sobre Understanding immutable infrastructure patterns: when server.
Si querés profundizar, tenemos un análisis completo en Understanding immutable infrastructure patterns: when server.
Profundizá en el tema con nuestro análisis de Understanding immutable infrastructure patterns: when server.
Si te interesa profundizar, acá está Understanding immutable infrastructure patterns: when server que lo explora en detalle.
Por supuesto, todo esto se conecta con Understanding immutable infrastructure patterns: when server, donde lo tratamos en profundidad.
Para profundizar en esto, leé nuestro análisis sobre Understanding immutable infrastructure patterns: when server.
Esto se conecta directamente con Understanding immutable infrastructure patterns: when server, donde cubrimos el tema en profundidad.
Esto se vincula directamente con Understanding immutable infrastructure patterns: when server, un análisis más profundo del tema.
Este tema se desarrolla en profundidad en Understanding immutable infrastructure patterns: when server.
Preguntas Frecuentes
¿Qué es la infraestructura inmutable?
La infraestructura inmutable es un modelo donde los servidores nunca se modifican después de su deployment. Cualquier cambio requiere construir una imagen nueva y reemplazar el servidor existente. Esto elimina el configuration drift y hace los entornos reproducibles.
¿Cuál es la diferencia entre servidores mascotas y ganado?
Los servidores “mascota” son tratados como individuos únicos: tienen nombre, historial propio y se reparan cuando fallan. Los servidores “ganado” son idénticos e intercambiables: cuando uno falla, se reemplaza por otro igual. La infraestructura inmutable se basa en el modelo ganado para garantizar consistencia y recuperación rápida.
¿Cómo evitar configuration drift en mis servidores?
La forma más efectiva es adoptar infraestructura inmutable combinada con Infrastructure as Code. Prohibir los cambios manuales en producción y definir toda la configuración en archivos versionados (Terraform, manifiestos Kubernetes) hace que el drift sea imposible por diseño. Herramientas como terraform plan detectan divergencias antes de que se acumulen.
¿Por qué reemplazar servidores en lugar de actualizarlos?
Actualizar un servidor en producción acumula cambios no documentados que con el tiempo crean comportamientos impredecibles. Reemplazarlo desde una imagen nueva garantiza que el estado inicial es conocido y reproducible. El rollback también se simplifica: volvés a la imagen anterior en segundos, sin tener que deshacer parches.
¿Cómo implementar infraestructura inmutable con Docker o Kubernetes?
Con Docker: cada deploy construye una imagen nueva con tag versionada (nunca latest en prod), se publica en un registry y se deploya. Con Kubernetes: los Deployments usan rolling updates para reemplazar pods de a uno, con health checks antes de bajar los viejos. Ambos enfoques requieren que el estado de la aplicación esté externalizado (base de datos, object storage) fuera de la imagen.
Conclusión
La infraestructura inmutable no es una moda ni una complejidad gratuita. Es la respuesta más coherente al problema real del configuration drift, que acumula deuda operativa de forma silenciosa hasta que algo explota en el peor momento posible. El modelo existe desde hace años pero en 2026 tiene las herramientas maduras para implementarlo: Docker con ecosistema estable, Kubernetes ampliamente adoptado, Terraform consolidado como estándar de IaC.
El costo de entrada es real: requiere pipelines de CI/CD bien configurados, imágenes versionadas, separación estricta del estado. Pero el costo de no hacerlo también es real, solo que se paga después y siempre en el peor momento. Si tu equipo todavía entra por SSH a producción para “un arreglito rápido”, ese es el primer hábito a cambiar.