Pipeline ETL con Airflow, BigQuery y Docker: guía 2026
Armar tu primer pipeline ETL de punta a punta con Apache Airflow, BigQuery y Docker es más accesible de lo que parece, y este es justo el tema que empezó a sonar fuerte entre quienes recién arrancan en data engineering. Un desarrollador documentó en junio de 2026 cómo procesó más de 145.000 filas de datos climáticos australianos de 10 años, y dejó varias lecciones concretas que te sirven para no tropezar en lo mismo.
Un pipeline ETL es un flujo de trabajo que extrae datos de una fuente (Extract), los limpia y transforma (Transform) y los carga en un destino para analizarlos (Load). Apache Airflow es la herramienta open source que orquesta ese flujo: define el orden de las tareas, los reintentos y los horarios, pero no hace la extracción ni la transformación por sí mismo. Eso lo ponés vos en el código de cada tarea.
En 30 segundos
- Airflow orquesta, no procesa: coordina las tareas de extracción, transformación y carga, pero el trabajo pesado lo hace tu código en Python.
- Caso real: 145.000 filas de datos climáticos australianos de 10 años, procesadas en un pipeline de cuatro etapas.
- Dato fuerte: pasar de CSV a Parquet logró un 82,5% de reducción de almacenamiento en el proyecto documentado.
- Stack mínimo: Python 3.8+, Docker, una cuenta de Google Cloud con BigQuery API habilitada y una service account.
- El error más común: usar XCom de Airflow para mover datasets grandes (eso satura la base de metadatos).
¿Qué es un pipeline ETL y por qué Airflow es el estándar?
Ponele que tenés un CSV con diez años de mediciones de clima y querés cargarlo a una base analítica para sacar conclusiones. No lo subís y listo: hay que leerlo, validar que no falten valores, convertir tipos, reestructurar y recién ahí cargarlo. Ese recorrido es ETL.
Airflow es de Apache y se volvió la herramienta de referencia para esto por una razón práctica: definís el pipeline como código Python, con dependencias claras entre tareas. Tiene integraciones nativas con Google Cloud, AWS y Azure, así que no estás reinventando conectores. Según los casos de uso oficiales de Airflow, la enorme mayoría de quienes lo adoptan lo hacen justamente para flujos ETL/ELT orientados a analytics.
Eso sí: Airflow no es un motor de procesamiento. Es un director de orquesta. Si le pedís que transforme un dataset gigante dentro de una tarea pesada sin delegar a una herramienta adecuada, la vas a pasar mal. Sobre eso hablamos en enriquecer datos con IA.
¿Qué necesitás para empezar a construir tu primer pipeline en Google?
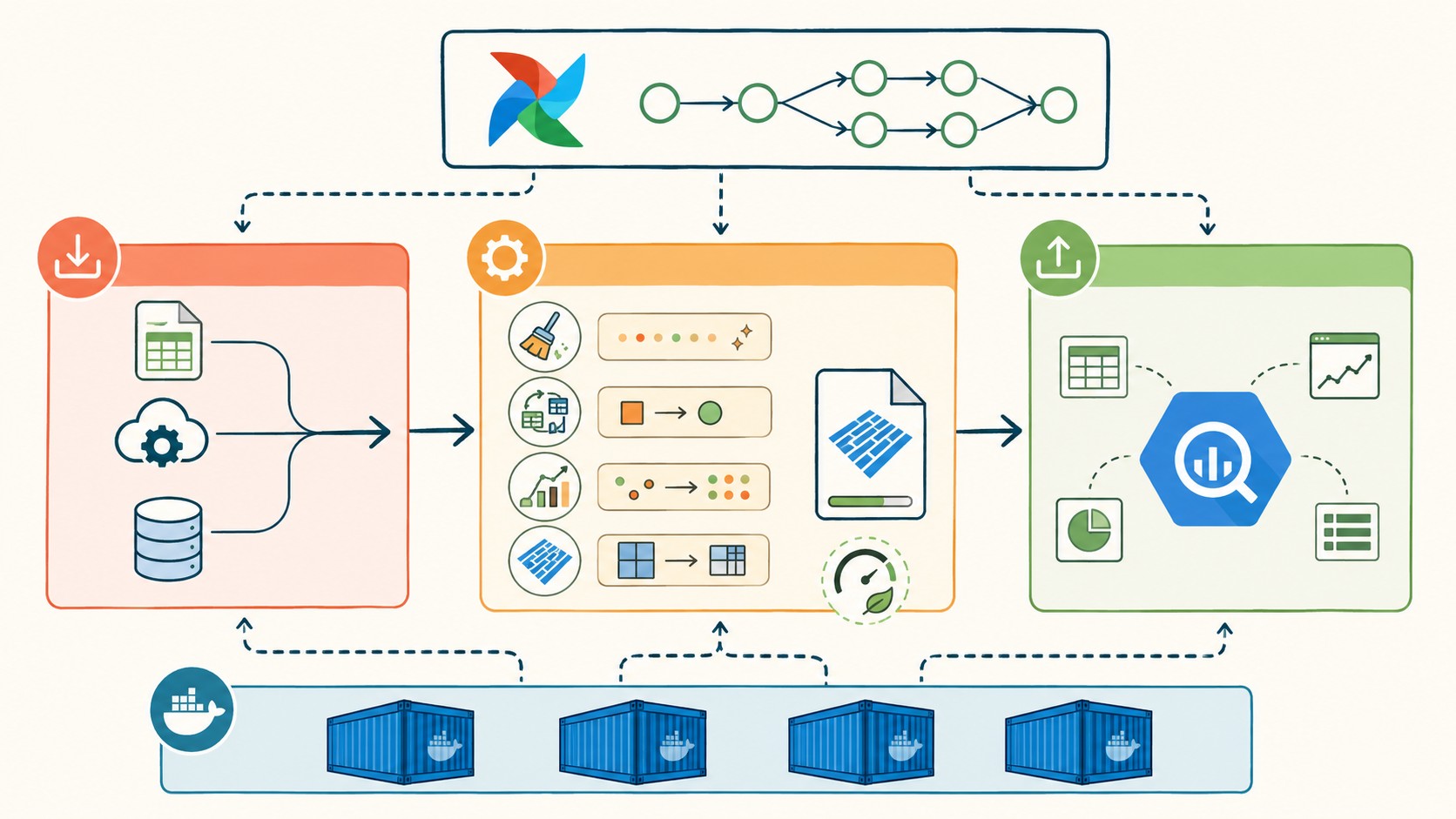
Antes de escribir una línea de DAG, conviene tener el entorno listo. La buena noticia es que con Docker te evitás el clásico “en mi máquina funciona”.
- Python 3.8 o superior: es la base sobre la que corre Airflow y donde escribís la lógica de cada tarea.
- Docker y Docker Compose: levantan Airflow en contenedores aislados, sin pelearte con dependencias del sistema.
- Cuenta de Google Cloud: creás un proyecto, habilitás la BigQuery API y generás una service account con su archivo JSON de credenciales.
- Paquetes de Python:
apache-airflow,google-cloud-bigqueryypandaspara el manejo de datos.
La service account es el punto donde más gente se traba. Generás la clave JSON, la montás como volumen en el contenedor y apuntás la variable de entorno GOOGLE_APPLICATION_CREDENTIALS a esa ruta. Si esa parte queda bien, el resto fluye. Para alojar la infraestructura donde corra todo esto en producción, podés mirar opciones de cloud y VPS en donweb.com.
¿Cómo extraer datos de distintas fuentes con Airflow?
La etapa de extracción es la que parece la más simple y rara vez lo es. En el proyecto documentado en dev.to, la extracción consistió en leer CSV crudos, validar la ingesta, manejar registros inconsistentes y detectar valores faltantes temprano.
¿Por qué tanto cuidado al principio? Porque un dato sucio que pasa sin que lo notes se arrastra por todo el pipeline y aparece roto al final, cuando ya es carísimo de rastrear. Airflow conecta con CSV, APIs REST y bases SQL, pero la validación la tenés que escribir vos: chequear estructura, contar filas, marcar nulos.
El autor lo resume bien: trabajar con un caso real de 145.000 filas le hizo entender por qué la confiabilidad en la ingesta importa tanto. No es un detalle de manual. Es lo que decide si tu pipeline sirve o miente.
¿Cómo transformar y validar datos antes de la carga?
Acá viene lo bueno: la transformación trae más complejidad de la que cualquiera espera al arrancar. El proyecto incluyó manejo de nulls, conversión de tipos inconsistentes, reestructuración de registros y feature engineering. Un ejemplo concreto: clasificar las estaciones del año a partir de las fechas climáticas, para enriquecer el dataset. Lo explicamos a fondo en pipelines de CI/CD modernos.
El dato que más llama la atención es el formato. Al convertir el dataset transformado de CSV a Parquet, el proyecto logró un 82,5% de reducción de almacenamiento. Parquet es columnar y comprime mucho mejor que un CSV plano, y encima BigQuery lo lee más rápido.
Esta fase deja una lección que se subestima: la consistencia de esquema y la calidad de datos no son un lujo. Si los tipos no coinciden o el esquema cambia entre cargas, BigQuery te lo va a recordar con errores en el peor momento.
¿Cómo cargar los datos transformados en BigQuery?
BigQuery es el almacén de datos sin servidor de Google Cloud: procesa consultas sobre volúmenes enormes sin que administres infraestructura. Para cargar desde Airflow usás operadores nativos como BigQueryCreateEmptyTableOperator y BigQueryInsertJobOperator.
El patrón recomendado es cargar primero a una tabla de staging y después promover a la tabla final, validando en el medio. En el proyecto se implementó verificación de conteo de filas (row-count) para confirmar que lo que entró coincide con lo que se procesó. La documentación oficial de Google Cloud sobre orquestación de DAGs detalla cómo encadenar estos operadores.
Un truco que ahorra dolores de cabeza: usá Cloud Storage como intermediario para archivos grandes en vez de empujar todo directo. Y siempre poné lógica de reintento en la carga, porque las cargas fallan por motivos que no controlás. Te puede servir nuestra cobertura de alternativas a BigQuery en Google Cloud.
¿Cómo optimizar el pipeline para rendimiento y costo?
Optimizar un ETL no es solo correr más rápido. Es gastar menos y escalar sin sustos.
- Formato columnar: Parquet sobre CSV. Ya viste el 82,5% de ahorro de almacenamiento, y la lectura en BigQuery también mejora.
- Particionamiento: particioná las tablas de BigQuery por fecha para que las consultas escaneen solo lo que necesitan y pagues por menos GB procesados.
- Paralelización: extracción, transformación y carga de distintos lotes pueden correr en simultáneo dentro del DAG.
- Evitá XCom para datos grandes: XCom guarda en la base de metadatos de Airflow. Para datasets pesados, pasá por Cloud Storage.
BigQuery cobra por GB procesado en consultas. Si particionás bien y guardás en Parquet, la factura baja sola.
Esto conecta directamente con Docker in production pipelines, donde comparamos las alternativas disponibles.
Si querés profundizar en esto, tenemos un artículo sobre container memory debugging.
Mirá nuestro artículo sobre ETL pipelines with BigQuery para profundizar en cómo armar pipelines escalables.
Errores comunes al armar tu primer pipeline ETL
- Usar XCom para mover datasets enteros: XCom es para metadatos chicos, no para tu tabla de 145.000 filas. Si la metés ahí, saturás la base de Airflow. Solución: Cloud Storage como puente.
- Ignorar la idempotencia: si una tarea se reintenta y duplica datos, tu carga queda inflada. Diseñá cada tarea para que correrla dos veces dé el mismo resultado.
- No manejar los rate limits de las APIs: si extraés de una API y no ponés backoff exponencial, te van a cortar. Agregá esperas crecientes entre reintentos.
- Saltarte las pruebas y el manejo de errores: sin retry policies ni alertas, te enterás de que el pipeline falló cuando alguien pregunta por un reporte que no existe.
Preguntas Frecuentes
¿Qué es un pipeline ETL?
Un pipeline ETL es un flujo automatizado que extrae datos de una fuente, los transforma (limpia, convierte y reestructura) y los carga en un destino analítico como BigQuery. ETL son las siglas de Extract, Transform y Load. Es la forma estándar de preparar datos crudos para análisis.
¿Airflow extrae y transforma los datos por sí mismo?
No. Airflow orquesta el pipeline: define el orden de las tareas, los horarios y los reintentos, pero el código que extrae, transforma y carga lo escribís vos en Python. Pensalo como el director de orquesta, no como el músico. Esto se conecta con lo que analizamos en Jenkins y GitHub Actions comparados.
¿Por qué conviene usar Parquet en lugar de CSV?
Parquet es un formato columnar que comprime mucho mejor y se lee más rápido en BigQuery. En el proyecto documentado, pasar de CSV a Parquet logró una reducción de almacenamiento del 82,5%. Eso significa menos costo y consultas más veloces.
¿Para qué sirve Docker en un pipeline de Airflow?
Docker levanta Airflow en contenedores aislados con todas sus dependencias, así que el pipeline corre igual en tu máquina y en producción. Con Docker Compose levantás todo el entorno con un solo comando y evitás el clásico problema de “en mi máquina funcionaba”.
¿Cuánto cuesta cargar datos en BigQuery?
BigQuery cobra por la cantidad de GB procesados en las consultas, no por almacenar las tablas en sí (que tiene su propia tarifa más baja). Si particionás las tablas por fecha y guardás en Parquet, reducís los GB escaneados y bajás el costo de cada consulta.
Conclusión
Construir tu primer pipeline ETL de punta a punta con Airflow, BigQuery y Docker no es un ejercicio teórico: el caso de los 145.000 registros climáticos muestra que cada etapa tiene decisiones reales que pesan. La validación temprana te salva de datos sucios, Parquet te ahorra un 82,5% de almacenamiento y Docker te da un entorno que no se rompe al pasar a producción.
Si recién arrancás, empezá chico: un DAG con tres tareas, datos de prueba y Docker Compose en local. Cuando eso funcione de punta a punta, escalás a Cloud Composer. La diferencia entre un pipeline que sirve y uno que miente está en los detalles de ingeniería de cada etapa, no en la cantidad de herramientas que usás.
Fuentes
- Apache Airflow – Casos de uso oficiales para ETL y analytics
- Google Cloud – Orquestar DAGs de Airflow con BigQuery (documentación oficial)
- Dev.to – Building My First End-to-End ETL Pipeline with Airflow, BigQuery, and Docker
- Profile.es – Guía de Apache Airflow
- Medium – Canalización de datos con Apache Airflow y GCP