Scheduling de posts en sitios estáticos por USD 0
El scheduling de posts en un sitio estático se puede resolver sin servidor, sin CMS y sin base de datos en runtime, gastando cero. El truco que documentó Jean Carlo Schmitz en su nota de dev.to del 16 de junio de 2026 es simple: tratar la base de datos como un insumo del build y no como una dependencia en vivo. Escribís hoy, sale el martes a las 7.
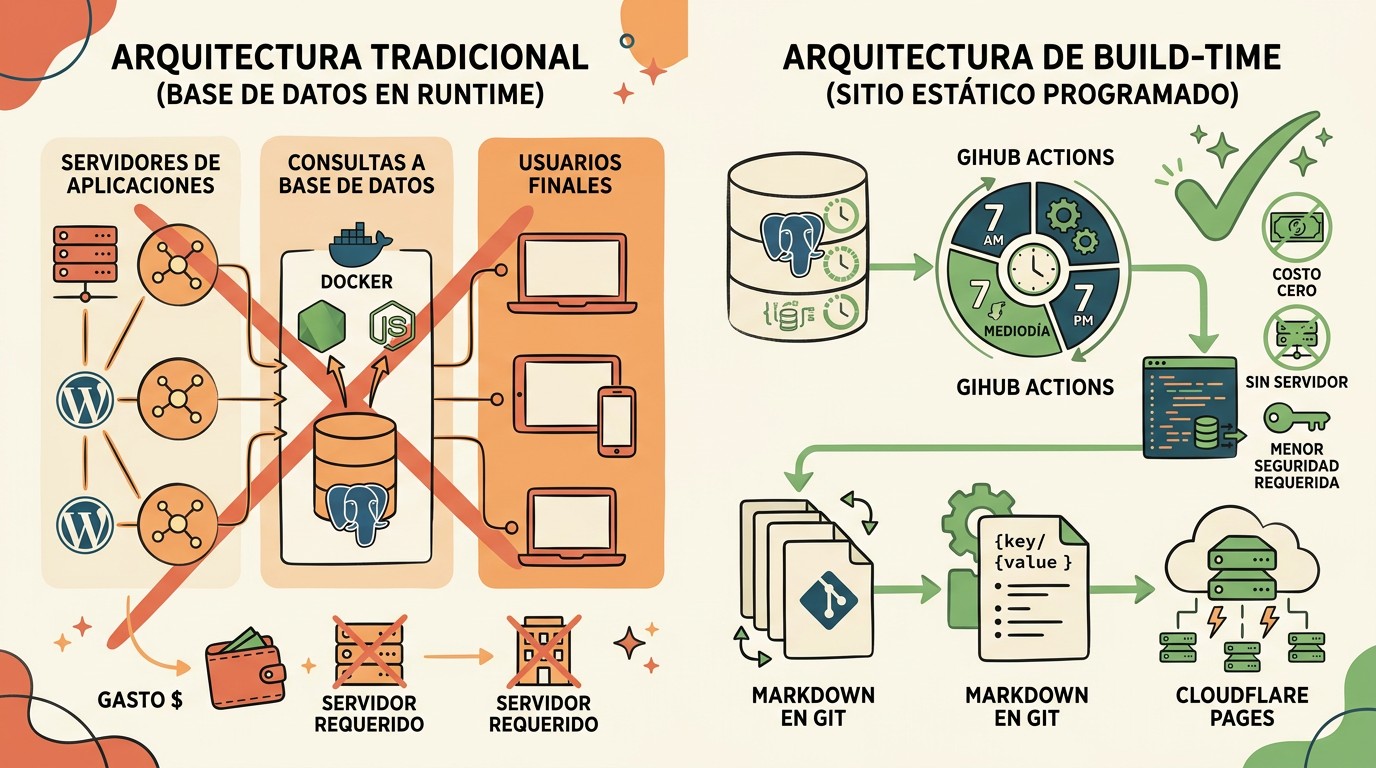
El scheduling de posts en un sitio estático es la técnica de programar la publicación de contenido en una web pre-renderizada, donde el HTML se congela en el momento del build. En vez de consultar una base de datos en cada visita, el sitio la lee una sola vez durante la construcción y materializa los posts como archivos en disco. Un cron job dispara builds periódicos que publican lo que ya tocaba salir.
En 30 segundos
- La base de datos vive en el build, no en runtime: un script Node la lee una vez y escribe los posts como Markdown antes de desplegar.
- Un cron de GitHub Actions dispara el deploy: corre cada X horas y publica lo que tenga la fecha cumplida.
- El sitio shippeado no tiene código de base de datos: ni connection string, ni API route, ni nada en el bundle del cliente.
- Costo total: USD 0 combinando GitHub Actions, un hosting de estáticos y un Postgres serverless en capa gratuita.
- La contra: la precisión es de horas, no de minutos. El cron no es un reloj suizo.
¿Qué es el scheduling de posts en sitios estáticos?
Ponele que querés escribir una nota un domingo a la tarde y que aparezca recién el miércoles, sin vos despierto apretando un botón. En un sitio dinámico eso es trivial: el servidor mira el reloj y decide qué mostrar. En uno estático no, porque el HTML ya quedó congelado en el momento del build.
Acá está la tensión que parece irresoluble. Estático significa todo pre-renderizado, sin servidores que cuidar. Scheduling significa que el contenido aparece según el reloj. Suenan a opuestos. La respuesta de manual suele ser “metele un CMS” o “renderizá del lado del servidor”, y justamente eso es lo que el enfoque que estamos viendo evita. Complementá con asegurar tus secretos en el pipeline.
¿Por qué un sitio estático necesita otra estrategia para programar?
Un sitio estático no tiene a quién preguntarle la hora. No hay un proceso corriendo que pueda fijarse “¿ya son las 7 del martes?” y recién ahí mostrar el post. Todo el HTML se generó antes, durante el build, y desde ahí no se mueve hasta el próximo despliegue.
Una base de datos tradicional consultada en vivo rompe la premisa entera. Si el cliente o una API route pegan a Postgres en cada request, dejas de tener un sitio estático y vuelves a pagar (y a mantener) infraestructura que siempre está prendida. El planteo de Schmitz invierte la lógica: la base es donde guardás tus borradores y la fecha de publicación, una especie de planilla elegante que el pipeline de build lee de pasada.
¿Cómo funciona el scheduling con GitHub Actions y cron jobs?
El motor es un cron job. En GitHub Actions definís un workflow programado con sintaxis cron clásica (algo como 0 */6 * * * para correr cada 6 horas) y ese disparo arranca un build nuevo. El build vuelve a leer las fuentes, detecta qué posts ya tienen la fecha cumplida y los incluye en el sitio.
El mismo patrón aparece hace años en otros stacks. Nicholas Zakas lo contó para Jekyll con Netlify y GitHub Actions, y Damir Arh lo documentó para su blog con builds disparados por Actions. La idea es idéntica: el cron no publica nada por sí mismo, solo le avisa al pipeline “fijate si hay algo nuevo que sacar”. Lo explicamos a fondo en elegir tu herramienta de CI/CD.
¿Cómo se consulta la base de datos en tiempo de build?
Acá viene lo bueno. El contenido vive en una base (Schmitz usa Postgres sobre Neon, que tiene capa gratuita). Durante el build, un script de Node se conecta una sola vez, corre un SELECT con un WHERE published_at <= now() y escribe cada fila que pasó el filtro como un archivo Markdown en disco.
A esto lo llama Schmitz “materialización”: convertir filas en archivos. Una vez que esos archivos existen, el resto del build (en su caso, el SSG de SvelteKit, más el sitemap, el RSS y las imágenes OG) los lee como si siempre hubieran estado ahí. El sitio final no tiene ni una línea de código de base de datos. La DB, una vez terminado el build, podría no existir.
¿Cómo evitar perder posts si la base de datos falla?
¿Y qué pasa si Neon está caído justo cuando corre el cron? Si el build lee cero filas y publica un sitio vacío, te borraste el blog entero sin querer. Por eso los archivos materializados se commitean al repositorio git como fallback.
Si la consulta devuelve vacío o falla, el build usa los archivos que ya estaban versionados en lugar de pisar todo con la nada. Es la red de seguridad: el build recibe el cambio a la base, corre, lee las filas, materializa los archivos, los commitea, y si en la próxima la base no responde, el último estado bueno sigue ahí guardado. Validar contra lecturas vacías antes de escribir es la diferencia entre un sistema robusto y una bomba de tiempo. Ya lo cubrimos antes en entre Jenkins y GitHub Actions.
¿Cuáles son las limitaciones de esta arquitectura?
No todo es color de rosa. La precisión temporal es el límite más obvio: si el cron corre cada 6 horas, un post programado para las 7:01 puede salir a las 9 o a las 12. Para un blog personal zafa. Para algo con embargo periodístico al minuto, no.
El otro techo es la cantidad de archivos. Algunas plataformas de hosting de estáticos imponen un límite de archivos por deploy. Si tu blog genera miles de páginas (cada post con su HTML, sus imágenes OG, sus variantes), en algún momento ese número aprieta. Tomalo con pinzas según tu plataforma, porque cada hosting de estáticos pone su propio cap.
¿Cuánto cuesta implementar scheduling en un sitio estático?
Cero, si te quedás en las capas gratuitas. GitHub Actions regala minutos de CI para repos públicos, los hostings de estáticos sirven sitios sin cargo dentro de cuotas generosas, y Neon ofrece un Postgres serverless gratis para proyectos chicos. Sumá esas tres piezas y el scheduling de posts en un sitio estático te sale USD 0 al mes.
Si en cambio necesitás infraestructura propia para un proyecto más grande, con dominio y hosting administrado en Argentina, podés mirar donweb.com. Pero para el caso que describe la nota, la gracia es justamente no pagar nada.
Mirá cómo hacemos eso acá: How I schedule blog posts on a 100% static site for $0, no s.
| Enfoque | Servidor en runtime | Base de datos en vivo | Costo mensual | Precisión del horario |
|---|---|---|---|---|
| CMS tradicional (WordPress, etc.) | Sí | Sí | Variable (hosting + DB) | Al minuto |
| Estático con base build-time | No | Solo durante el build | USD 0 (capas gratuitas) | Por horas (según cron) |
| Estático con archivos en git | No | No | USD 0 | Por horas (según cron) |
Errores comunes al programar posts en sitios estáticos
- Esperar precisión al minuto del cron: GitHub Actions no garantiza que el job arranque exacto a la hora pactada, puede demorarse bajo carga. Ajustá la expectativa o bajá el intervalo, sabiendo que vas a gastar más minutos de CI.
- No commitear los archivos materializados: si dependés solo de la base y un día no responde, el build lee vacío y te deja el sitio pelado. Versioná siempre el último estado bueno en git.
- Meter el connection string en el bundle del cliente: no hace falta y es un agujero de seguridad. La base se toca únicamente en el build, nunca desde el navegador del visitante.
- Olvidar la zona horaria en el WHERE: si tu
published_atestá en UTC y vos pensás en hora local, el post sale corrido varias horas. Fijá la zona explícita en la consulta.
Preguntas Frecuentes
¿Cómo programar posts automáticos en un blog estático?
Configurás un cron job (por ejemplo en GitHub Actions) que dispara un build periódico. En cada build, un script lee la fuente de contenido, filtra los posts cuya fecha de publicación ya pasó y los incluye en el sitio. No hace falta servidor ni intervención manual. Para más detalles técnicos, mirá comparar modelos de IA para contenido.
¿Se pueden schedulear posts sin servidor ni base de datos en runtime?
Sí. La clave es usar la base de datos solo durante el build, no en vivo. El script la consulta una vez, materializa los posts como archivos y el sitio shippeado queda 100% estático, sin connection string ni API routes. Incluso podés prescindir de base y usar archivos en git.
¿Qué tan preciso es el horario de publicación?
La precisión depende del intervalo del cron. Si corre cada 6 horas, un post puede salir hasta varias horas después de su fecha programada. Sirve para blogs y contenido sin urgencia al minuto, no para embargos periodísticos exactos.
¿Cuánto cuesta montar este sistema?
USD 0 si te quedás en capas gratuitas: GitHub Actions para el cron, un hosting de estáticos para servir el sitio y un Postgres serverless como Neon para el contenido. El gasto recién aparece si escalás mucho el tráfico o la cantidad de páginas.
¿Qué pasa si la base de datos se cae durante el build?
Si commiteaste los archivos materializados en git, el build usa esa versión guardada como fallback en lugar de publicar un sitio vacío. Por eso conviene validar contra lecturas vacías antes de sobrescribir el contenido existente.
Conclusión
Lo que cambió acá no es la tecnología, son las piezas viejas combinadas distinto. Cron jobs, builds y bases de datos existen hace años. La movida fina es dejar de pensar la base como algo a lo que el sitio le habla en vivo, y empezar a verla como un insumo que el build lee una vez y descarta.
Si tenés un blog estático y querés programar posts, el camino es claro: armá un cron que dispare builds, materializá el contenido a archivos durante la construcción y commiteá esos archivos como respaldo. Ganás publicación automática sin pagar un servidor ni resignar la simpleza de lo estático. Eso sí, asumí que la precisión es de horas y diseñá el sistema para que un fallo de la base nunca te deje el sitio en blanco.
Fuentes
- dev.to – Cómo Jean Carlo Schmitz programa posts en un sitio 100% estático por USD 0
- Serverless.com – Static site post scheduler
- Nicholas Zakas – Scheduling Jekyll posts con Netlify y GitHub Actions
- Go Make Things – How to schedule posts with a static website
- Damir’s Corner – Blog post publishing con GitHub Actions

![[FREE] I built a no-code RPG game engine plugin for WordPress. Here's a 30 minute build demo - ilustracion](https://donweb.news/wp-content/uploads/2026/04/plugin-rpg-wordpress-sin-codigo-hero-768x429.jpg)


![Kelsey Hightower: Kubernetes and retiring at the top [video] - ilustracion](https://donweb.news/wp-content/uploads/2026/06/kelsey-hightower-retiro-google-kubernetes-hero-768x429.jpg)