Agentes Claude para DevOps: monitoreo inteligente con IA
Un agente Claude para DevOps es un sistema que lee tus métricas y logs, interpreta qué está pasando en contexto, lo explica en lenguaje claro y propone (o ejecuta) la remediación, siempre frenando antes de cualquier acción destructiva para pedir aprobación. Según la guía publicada en claudeguide.io en junio de 2026, no reemplaza tu stack de monitoreo: lo complementa.
Los agentes Claude para DevOps son agentes basados en el modelo de Anthropic que se conectan a tu sistema de monitoreo (Datadog, Grafana, PagerDuty, Prometheus), correlacionan señales dispersas y traducen el ruido de alertas en una hipótesis de causa raíz accionable. La pieza clave de su arquitectura es el approval gate: las acciones de solo lectura son automáticas, las destructivas nunca lo son.
En 30 segundos
- Qué es: un agente que lee métricas y logs, explica el incidente en lenguaje natural y propone remediación, con freno obligatorio antes de acciones destructivas.
- Qué NO hace: no reemplaza Datadog, Grafana ni PagerDuty. Se conecta a ellos vía API y cubre lo que esas herramientas no hacen bien.
- Tres gaps que cubre: explicar en contexto, correlacionar múltiples señales en una causa raíz, y comunicar a gente que no lee dashboards.
- Seguridad: restarts, rollbacks y scale-downs siempre pasan por un approval gate humano. Queries y lectura de logs son automáticas.
- Fecha: guía publicada el 17 de junio de 2026 en claudeguide.io.
¿Por qué Datadog y Grafana detectan el problema pero no te lo explican?
Ponele que son las 14:35 y te entra una alerta: el uso de memoria saltó al 90%. Datadog hizo su trabajo, detectó la anomalía. Pero ahora sos vos, medio dormido si es de madrugada, el que tiene que abrir cinco pestañas, cruzar el gráfico de memoria con el log de deploys y darte cuenta de que el spike arrancó justo después del deploy de las 14:30.
Ese trabajo de cruzar señales es lo que las herramientas tradicionales no hacen. Según la guía de claudeguide.io, las herramientas de monitoreo existentes son buenas detectando anomalías pero flojas en tres cosas concretas.
- Explicar qué pasa en contexto: relacionar “este pico de memoria correlaciona con el deploy de las 14:30” en vez de solo gritar “memoria al 90%”.
- Correlacionar entre señales: juntar CPU, latencia y tasa de error en una sola hipótesis de causa raíz, sobre todo en incidentes nuevos que no están en el playbook.
- Comunicarle a gente que no lee dashboards: traducir el incidente para quien necesita entender el impacto sin saber leer un gráfico de time-series.
Un agente Claude para DevOps llena esos huecos sin tocar tu stack de monitoreo. Esa es la idea central: complementar, no arrancar de cuajo lo que ya funciona. Para más detalles técnicos, mirá riesgos de seguridad en pipelines CI/CD.
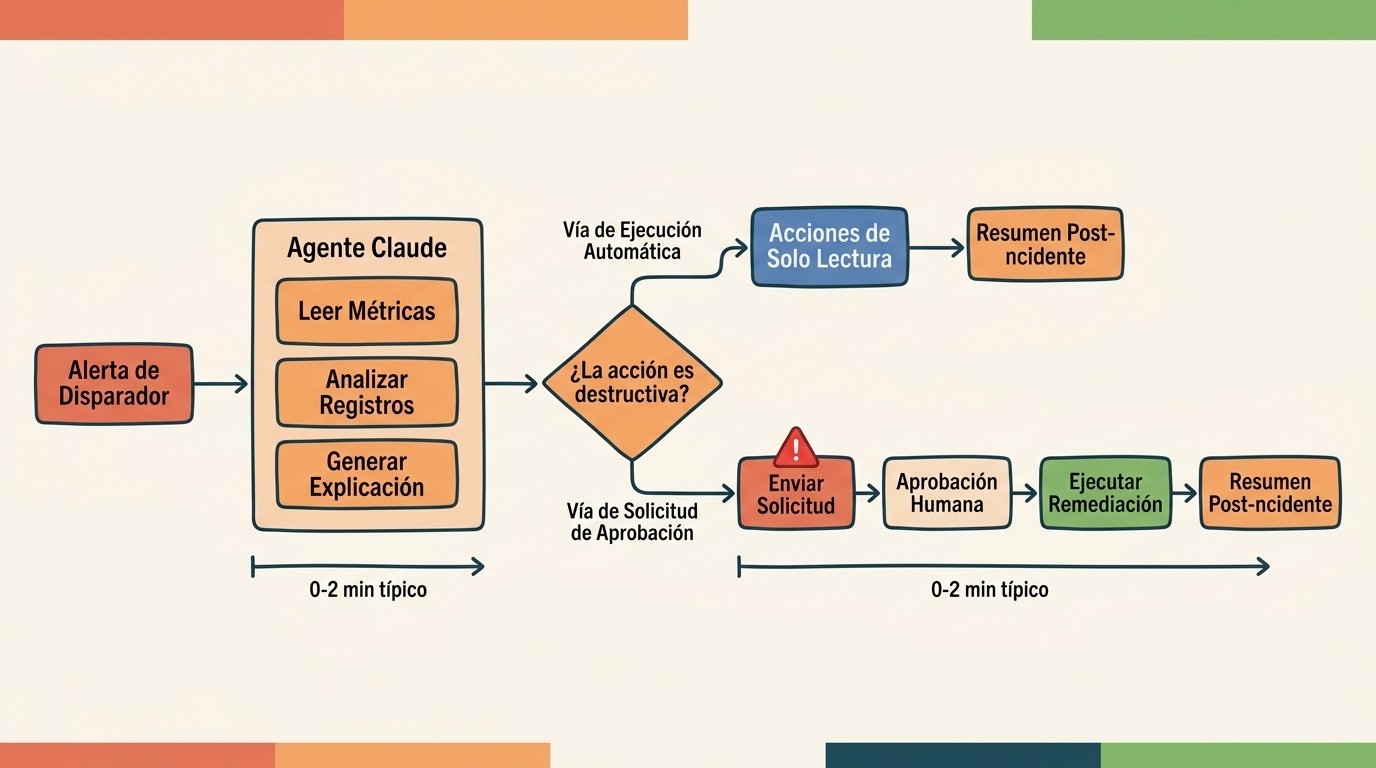
¿Cuál es el flujo completo desde que dispara la alerta hasta el remedio?
El flujo que describe la guía es lineal y, lo importante, tiene un punto de freno en el medio. Funciona así:
- Dispara la alerta. El evento entra desde tu sistema de monitoreo.
- El agente lee métricas y logs. Consulta las series de tiempo y hace tail de los logs relevantes. Todo esto es solo lectura.
- Análisis. Correlaciona las señales y arma una hipótesis.
- Explicación en lenguaje claro. Manda el diagnóstico a Slack o PagerDuty, en castellano (o el idioma que sea), no en jerga de dashboard.
- Remediación propuesta. Sugiere qué hacer.
- Approval gate. Acá frena. Si lo que sigue es destructivo, espera tu OK.
- Ejecución segura. Recién con aprobación, ejecuta.
- Resumen post-incidente. Cierra con un parte de qué pasó y qué se hizo.
Fijate que el approval gate no está al final de todo, está antes de ejecutar cualquier cosa que pueda romper. Lectura libre, escritura con permiso. Esa separación es el corazón del diseño.
¿Qué ejecuta solo el agente y qué necesita tu aprobación?
Esta es la pregunta que más importa si lo vas a meter en producción. La regla, según la guía, es simple: lo que no rompe nada se hace solo, lo que sí puede romper espera aprobación.
| Tipo de acción | Ejemplos | ¿Requiere aprobación? |
|---|---|---|
| Solo lectura | Queries de métricas, tail de logs, lectura de configuración | No, automáticas |
| Destructivas | Reinicios, rollbacks, scale-downs | Sí, approval gate obligatorio |
¿Por qué esta división y no dejar que haga todo solo? Porque un diagnóstico equivocado que solo lee no te cuesta nada, pero un rollback automático sobre una hipótesis errada te puede tirar producción abajo a las 3 de la mañana. El agente puede equivocarse leyendo. No queremos que se equivoque ejecutando. Sobre eso hablamos en comparativa de plataformas CI/CD modernas.
¿Cómo se conecta con Datadog, Prometheus o lo que ya tengas?
La premisa de toda la propuesta es que el agente no reemplaza nada. Se conecta a tu sistema existente vía API y consume lo que esos sistemas ya recolectan: métricas de time-series, logs, estado de configuración.
La guía plantea tres tipos de agente sobre esta base: uno de análisis de incidentes, uno de triage de alertas y uno de remediación segura con approval gates explícitos. Cada uno se apoya en herramientas que consultan tu monitoreo, por ejemplo una función que trae métricas de time-series del sistema. Acá hay que ser honesto: la parte de código de la fuente original venía truncada, así que no voy a detallarte firmas de funciones ni endpoints exactos que no pueda verificar. Lo que sí queda claro es el principio: el agente lee de tu stack, no lo sustituye.
Si estás montando la infraestructura donde corre todo esto (los servidores, el cloud, el VPS que aloja tu monitoreo), donweb.com tiene opciones de hosting y cloud en Argentina para sostenerlo sin depender de un datacenter del otro lado del mundo.
¿Cuáles son las buenas prácticas para remediar de forma segura en producción?
La guía ya te da la práctica número uno servida: el approval gate antes de toda acción destructiva. Sobre esa base, hay criterios que cualquiera que haya estado de guardia un fin de semana valora.
- Diseñá bien el gate de aprobación: que quede claro quién aprueba (DevOps, SRE, on-call) y que la acción propuesta llegue con su explicación, no como un botón ciego.
- Logueá las decisiones: qué propuso el agente, qué se aprobó, qué se ejecutó. Sin ese rastro, el post-mortem es a ciegas.
- Probá en staging antes: ningún remedio nuevo debería estrenarse contra producción.
- Tené plan de fallback: qué hacés si el remedio aprobado no resuelve, o empeora.
El límite conceptual es claro: el agente analiza y propone, el humano decide lo que duele. Mientras esa frontera se respete, sumás velocidad de diagnóstico sin regalar el control. Te puede servir nuestra cobertura de elegir entre Jenkins y GitHub Actions.
¿Qué casos reales muestran la diferencia frente a una alerta pelada?
Dos escenarios donde se nota el cambio.
Memory leak después de un deploy
Datadog te dice “memoria al 90%”. El agente, en cambio, lee la métrica, la cruza con el registro de deploys y te devuelve algo como “el pico de memoria correlaciona con el deploy de las 14:30”. Pasás de un número suelto a una hipótesis con sospechoso. El tiempo que ahorrás es justo el de abrir pestañas y atar cabos a mano.
Triage de alertas y ruido
Cualquiera que haya tenido un canal de PagerDuty escupiendo veinte alertas por minuto sabe que el problema no es la falta de información, es el exceso. Un agente de triage agrupa, prioriza y correlaciona CPU, latencia y tasa de error en una sola causa raíz probable, en vez de tirarte veinte notificaciones sueltas que en el fondo son el mismo incidente.
Errores comunes al adoptar un agente Claude para DevOps
- Darle permiso de ejecución total desde el día uno: el approval gate existe por algo. Saltearlo “para ir más rápido” es la receta para que un rollback automático sobre un diagnóstico flojo te complique el día.
- Creerle el diagnóstico sin verificar: el agente propone hipótesis, no verdades reveladas. En incidentes nuevos puede correlacionar mal. Tomalo como un primer análisis, no como sentencia.
- Pensar que reemplaza a Datadog o Grafana: no recolecta métricas, las lee. Si apagás tu monitoreo esperando que el agente lo haga todo, te quedás sin los datos que el propio agente necesita.
- No loguear las decisiones del agente: sin registro de qué propuso y qué se aprobó, el post-incidente se vuelve adivinanza.
Preguntas Frecuentes
¿Qué son los agentes Claude para DevOps?
Son agentes basados en el modelo Claude de Anthropic que leen métricas y logs de tu sistema de monitoreo, interpretan qué pasa en contexto, lo explican en lenguaje natural y proponen o ejecutan remediación. Siempre frenan antes de acciones destructivas para pedir aprobación humana.
¿Cómo funciona el monitoreo inteligente con IA?
El agente recibe la alerta, consulta métricas y logs en modo solo lectura, correlaciona las señales en una hipótesis de causa raíz y manda una explicación clara a Slack o PagerDuty. La correlación entre CPU, latencia y tasa de error es lo que diferencia al análisis con IA de una alerta tradicional. Esto se conecta con lo que analizamos en cómo Claude se compara con GPT-5.
¿Puede Claude ejecutar remedios automáticos en incidentes?
Solo las acciones de lectura (queries, tail de logs, lectura de config) son automáticas. Las acciones destructivas como reinicios, rollbacks y scale-downs pasan siempre por un approval gate que requiere aprobación humana antes de ejecutarse.
¿Necesito reemplazar Datadog con Claude?
No. El agente Claude se conecta a Datadog, Grafana, Prometheus o PagerDuty vía API y consume los datos que esos sistemas ya recolectan. Cubre lo que esas herramientas no hacen bien (explicar y correlacionar) sin reemplazar tu stack de monitoreo.
¿Qué mejora trae Claude a mis herramientas de monitoreo?
Aporta tres cosas que las herramientas tradicionales hacen mal: explicar el incidente en contexto, correlacionar múltiples señales en una sola causa raíz, y comunicar el problema a gente que no lee dashboards. Lo hace sin reemplazar lo que ya tenés instalado.
Conclusión
Lo que cambia con un agente Claude para DevOps no es la detección, eso ya lo hacían Datadog y Grafana. Lo que cambia es el salto entre “algo anda mal” y “esto es lo que anda mal y esto haría para arreglarlo”. El agente cierra ese hueco: lee, correlaciona, explica y propone, sin tocar el gatillo de las acciones que duelen.
Si lo vas a probar, empezá por lo que no rompe: dejalo analizar y explicar incidentes en modo solo lectura, medí si su diagnóstico te ahorra tiempo real, y recién después evaluá darle remediación con approval gates. La arquitectura está pensada para que no le sueltes la mano hasta que se la haya ganado.