5 deploys fallidos: por qué testear IAM antes de producción
Testing permisos IAM AWS antes de deployar no es opcional: es la diferencia entre un pipeline que funciona y dos semanas de tickets. Según el caso documentado en mayo de 2026, un solo permission set para data engineers requirió cinco deploys consecutivos antes de funcionar correctamente, bloqueando trabajo real en producción cada vez.
En 30 segundos
- Un permission set para data engineers requirió 5 deploys y 2 semanas antes de funcionar: S3, luego Athena con KMS, luego EMR Serverless, cada uno era un bug nuevo en producción.
- El problema real no es que IAM sea complejo, sino que sin testing automatizado cada falla es una falla productiva que bloquea usuarios reales.
- IAM Access Analyzer y el Policy Simulator de AWS permiten validar políticas antes de deployar, integrados directamente en CodePipeline o GitHub Actions.
- El principio de least privilege es imposible de aplicar correctamente si no tenés infraestructura de testing que te diga exactamente qué permisos hacen falta.
- Los casos más comunes de falla son condiciones KMS, role boundaries en EMR, y service principals en Athena — ninguno aparece en los ejemplos básicos de la documentación.
El ciclo reactivo: 5 deploys, 2 semanas y engineers bloqueados
Ponele que configurás un permission set para tu equipo de data. Los S3 reads funcionan. Glue Data Catalog también. Mandás a producción y, al día siguiente, llega el primer ticket: AccessDeniedException: User is not authorized to perform: s3:GetObject.
Agregás el permiso. Siguiente deploy. Día siguiente, nuevo ticket: ahora falla s3:PutObject. Agregás ese también. Después falla el cleanup, o sea el s3:DeleteObject. En este punto ya hiciste cuatro ciclos de deployment y dos días de trabajo para tener S3 read/write/delete operativo.
Exactamente eso pasó en el caso documentado en mayo de 2026 por un engineer trabajando con data engineers en AWS. Primer deploy: S3 y Glue funcionaron, Athena falló porque el query engine necesita KMS decrypt a través de un service principal y faltaba la condition correspondiente. Segundo deploy: Athena funcionó, pero EMR Serverless falló por permisos faltantes en el job submission. Tercer deploy: el job submission funcionó, pero la ejecución falló por permisos insuficientes en el execution role boundary. Cinco iteraciones totales. Dos semanas.
Cada falla bloqueó a un engineer real que abría un ticket en vez de correr su job. Eso es el costo real del testing reactivo.
IAM Access Analyzer es una herramienta de AWS que analiza políticas de acceso para detectar permisos excesivos, accesos no esperados y violaciones de least privilege antes de que lleguen a producción.
Las trampas ocultas de IAM: cuándo “completar el rol” no alcanza
El tema es que IAM no es una lista plana de acciones. Es una jerarquía de condiciones, service principals, role boundaries y políticas que interactúan de formas que no son obvias hasta que algo falla en producción. Lo cubrimos en detalle en nuestro artículo sobre elegir entre plataformas de CI/CD.
Veamos los casos concretos del incidente de dos semanas:
Athena y KMS: la condición que nadie documenta primero
Para que Athena ejecute consultas, el engine necesita desencriptar mediante KMS a través de un service principal específico. Eso requiere una condition en la política de KMS que autorice ese service principal. Si armás el permiso de Athena de la forma “básica”, sin esa condition, las queries van a fallar con un error que no menciona KMS en ningún lugar obvio.
EMR Serverless: el role boundary como piso y techo
Con EMR Serverless hay dos niveles de permisos distintos: los del job submission y los del execution role. Podés tener el primero sin el segundo. El job se lanza correctamente pero la ejecución falla. El error que ves no necesariamente te dice “te falta permiso en el execution role boundary”, sino que aparece como un error de runtime del job que podés tardar un rato en mapear correctamente a IAM.
¿Por qué esto importa? Porque cuando estás depurando en producción, cada ciclo es un deploy, un ticket, una espera. El costo no es técnico: es de tiempo y confianza del equipo.
Herramientas AWS para validación automática de permisos
AWS tiene herramientas nativas para esto. El problema es que la mayoría de los equipos las conoce pero no las integra en el pipeline.
| Herramienta | Qué hace | Cuándo usarla | Limitación |
|---|---|---|---|
| IAM Access Analyzer | Valida políticas contra mejores prácticas, detecta accesos externos inesperados, custom policy checks | Pre-deploy, en CodePipeline | No simula ejecución real, analiza sintaxis y lógica |
| IAM Policy Simulator | Simula si una acción específica está permitida o denegada para un rol/user dado | Testing manual de permisos puntuales | No automatizable fácilmente en pipeline standard |
| CloudTrail + Last Accessed | Muestra qué permisos se usaron realmente en los últimos 90 días | Auditoría de least privilege, post-deploy | Retrospectivo, no preventivo |
| SCPs (Service Control Policies) | Límites de permisos desde la cuenta/OU hacia abajo | Multi-cuenta, governance organizacional | No testean permisos, los restringen desde arriba |
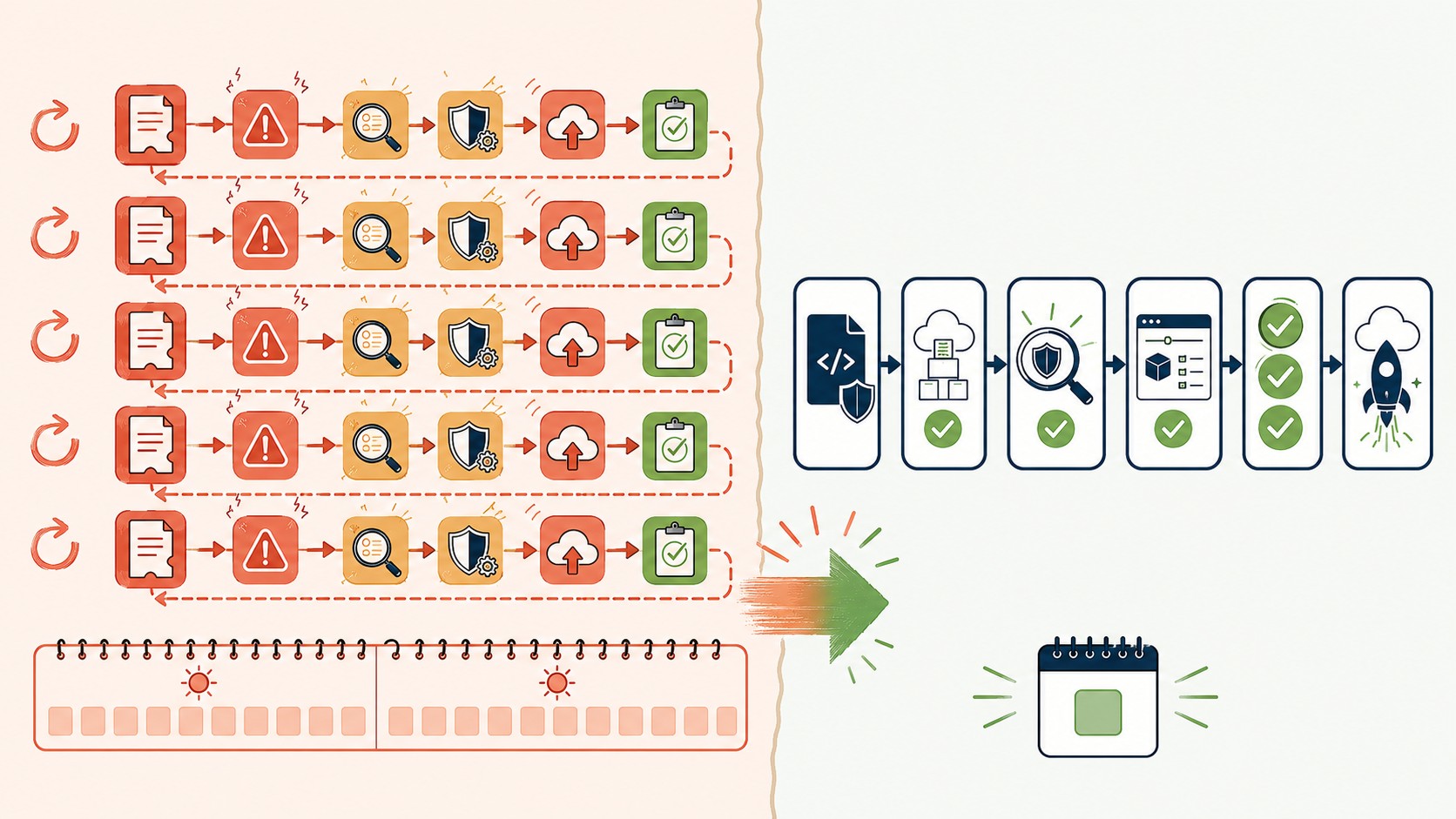
La combinación que tiene más sentido en 2026 es IAM Access Analyzer en el pipeline para validación pre-deploy, más CloudTrail Last Accessed para auditorías periódicas de least privilege.
Implementar testing automatizado en tu pipeline CI/CD
La integración concreta se ve así: antes del deploy real, el pipeline ejecuta aws accessanalyzer validate-policy sobre cada política en JSON. Si hay findings con severidad ERROR o SECURITY_WARNING, el step falla y el deploy no continúa. Ya lo cubrimos antes en configurar infraestructura para múltiples regiones.
Con GitHub Actions, el bloque mínimo es:
- Step de validación de schema JSON de las políticas (malformaciones básicas)
- Step de
aws accessanalyzer validate-policycon fail si hay findings críticos - Step opcional de simulación con
aws iam simulate-principal-policypara acciones específicas de alto riesgo - Deploy condicional solo si todos los steps anteriores pasan
Con CodePipeline, AWS tiene un patrón de referencia documentado que usa CloudFormation macros para interceptar el deployment de roles e invocar Access Analyzer automáticamente antes de que la stack llegue a la cuenta.
Ojo: el repositorio de ejemplo de AWS en GitHub (iam-policy-tester-pipeline) tiene un punto de partida concreto para esto. No está pensado para copy-paste directo a producción, pero la estructura del pipeline es sólida.
Testear permisos cross-service: S3, Glue, Athena, EMR, KMS
Los servicios de datos de AWS son el caso más complejo porque casi todos involucran cross-service: Athena llama a S3, S3 usa KMS, Glue cataloga lo que está en S3, EMR usa Glue y S3 y KMS a la vez. Cada salto cross-service es un punto potencial de falla de permisos que no aparece en el servicio que el usuario ve.
Del caso documentado, el mapa de permisos que hay que testear para un data engineer típico incluye:
- S3:
s3:GetObject,s3:PutObject,s3:DeleteObjecten los buckets correspondientes (con prefijos específicos si aplica least privilege) - Glue Data Catalog:
glue:GetDatabase,glue:GetTable,glue:GetPartitionmínimamente - Athena:
athena:StartQueryExecution,athena:GetQueryExecutionmás la condition de KMS en la política de clave - EMR Serverless (job submission):
emr-serverless:StartJobRun,emr-serverless:GetJobRun - EMR Serverless (execution role boundary): el execution role tiene que poder acceder a S3 y KMS, y el boundary tiene que permitir explícitamente eso
Si armás un test suite para este stack, podés cubrir el 90% de los casos de falla con ese conjunto. El 10% restante son condiciones muy específicas de configuración de cuenta que solo aparecen en setups multi-cuenta con SCPs restrictivos.
Principio de least privilege sin sacrificar velocidad
Acá viene lo bueno: el argumento habitual contra least privilege es que lleva demasiado tiempo. Que es más fácil poner s3:* y que todo funcione. La realidad es que esa decisión te cuesta el doble de tiempo cuando hay un incidente de seguridad o cuando intentás hacer una auditoría de accesos.
La “solución rápida” de usar wildcards es exactamente lo que genera el ciclo de cinco deploys que vimos antes (solo que en sentido inverso: arrancás con demasiados permisos en vez de muy pocos, y cuando querés ajustarlos no sabés qué es necesario y qué no).
El flujo correcto para least privilege con testing automatizado:
- Empezá con los permisos que documentan los servicios como mínimos recomendados
- Usá el Policy Simulator para validar acciones específicas antes de deployar
- Post-deploy, monitoreá CloudTrail Last Accessed durante 2-4 semanas de uso real
- Con esos datos, ajustá las políticas para remover lo que no se usa
- Cada ajuste pasa por el pipeline con Access Analyzer antes de aplicarse
El tiempo de setup es real. Pero lo amortizás rápido cuando el primer permission set sale bien a la primera en vez de requerir cinco deploys y dos semanas de soporte. Más contexto en ejecutar agentes sin dependencias externas.
Setups multi-cuenta y validación de permisos entre cuentas
Si tenés dev/staging/prod en cuentas separadas (que es lo recomendado en AWS), el testing de permisos se complica: los SCPs de la OU de producción pueden bloquear cosas que en dev funcionan sin problema. Un permiso que pasa todas las validaciones en dev puede fallar en prod porque la SCP de esa OU tiene restricciones adicionales.
El punto es que el testing tiene que incluir simulación contra las SCPs de la cuenta destino, no solo validación de la política en sí. IAM Access Analyzer puede hacer esto si le pasás el contexto de la cuenta destino en el análisis.
Con AWS Identity Center (el servicio de SSO empresarial), los permission sets se aplican como roles en cada cuenta miembro. Si la cuenta tiene SCPs que restringen ciertos servicios o regiones, el permission set que funciona en dev puede producir AccessDeniedException en prod aunque la política sea idéntica. Hay que testear la combinación, no las partes por separado.
Errores comunes al testear permisos IAM
Testear solo las acciones directas, no las cross-service
Validás que el rol puede hacer s3:GetObject y das el caso por cerrado. Pero si ese bucket usa KMS con una clave gestionada por el cliente, también necesitás kms:Decrypt con la condition correcta. El error que aparece en producción menciona S3, no KMS, y tardás un rato en entender qué falta realmente.
Confundir el rol que hace el request con el execution role
En servicios como EMR Serverless o Lambda, hay dos roles involucrados: el que llama al servicio y el que el servicio usa para ejecutar. Podés tener el primero configurado correctamente y olvidarte del segundo. El resultado es un job que se lanza pero falla durante la ejecución, con logs que apuntan al servicio y no al permiso faltante.
Asumir que dev y prod tienen las mismas restricciones
Si la cuenta de dev no tiene SCPs restrictivas y prod sí, cualquier permiso que funcione en dev puede fallar en prod. El testing tiene que reproducir las restricciones de la cuenta destino, no solo validar la política en aislamiento. Muchos equipos descubren esto cuando hacen el primer deploy a producción de algo que “funcionó perfecto en dev durante semanas”. Sobre eso hablamos en comparar seguridad entre plataformas.
No documentar por qué se incluyó cada permiso
Seis meses después, nadie sabe si ese kms:ReEncryptFrom es necesario o sobrante. Sin documentación de por qué se agregó cada permiso, las auditorías de least privilege se convierten en ruleta rusa: removés algo y esperás a ver si rompe algo en producción.
Para entender mejor estas vulnerabilidades, consultá nuestro artículo sobre automated permission testing.
Preguntas Frecuentes
¿Cómo testear permisos IAM antes de deployar a producción?
Integrá aws accessanalyzer validate-policy en tu pipeline como step previo al deploy. Si hay findings críticos, el pipeline falla y el cambio no llega a la cuenta. Para validaciones más específicas, aws iam simulate-principal-policy te permite testear si una acción concreta está permitida o denegada para un principal dado, incluyendo las SCPs de la cuenta destino.
¿Qué herramientas usan para validar políticas IAM automáticamente?
Las más usadas en 2026 son IAM Access Analyzer para validación de políticas en pipeline, el Policy Simulator para testing manual de acciones específicas, y CloudTrail Last Accessed para auditorías retrospectivas de least privilege. AWS también tiene un patrón de referencia documentado con CodePipeline y CloudFormation macros en su repositorio de ejemplos.
¿Cómo implementar least privilege con testing automatizado?
Arrancá con los permisos mínimos documentados por cada servicio, validalos con el Policy Simulator antes de deployar, y usá CloudTrail Last Accessed durante las primeras semanas para identificar qué permisos se usan realmente. Cada ajuste posterior tiene que pasar por Access Analyzer en el pipeline antes de aplicarse a producción.
¿Por qué falla mi rol IAM en Athena o EMR después de desplegar?
Los casos más frecuentes son: falta la condition de KMS decrypt para el service principal de Athena (el error aparece como falla de query, no como error de KMS), o falta un permiso en el execution role boundary de EMR Serverless (distinto del rol que hace el job submission). Ambos son problemas de permisos cross-service que no aparecen en los ejemplos básicos de la documentación oficial.
¿IAM Access Analyzer es suficiente para prevenir todos los errores de permisos?
No. Access Analyzer valida la lógica y estructura de las políticas, detecta accesos externos inesperados y violaciones de mejores prácticas conocidas. No simula el flujo de ejecución real de un servicio como Athena o EMR con todas sus dependencias cross-service. Para eso necesitás complementarlo con el Policy Simulator y, en setups multi-cuenta, con validación explícita contra las SCPs de la cuenta destino.
Conclusión
El caso documentado en mayo de 2026 no es una historia de IAM siendo difícil. Es una historia de ausencia de infraestructura de testing: cinco deploys que podrían haber sido uno si hubiera un pipeline que valide permisos cross-service antes de que lleguen a la cuenta de producción.
La inversión en testing automatizado de permisos IAM se amortiza rápido: el primer permission set que sale bien a la primera, sin tickets ni esperas, justifica el tiempo de setup. Y si tenés equipos de datos usando Athena, EMR y Glue, los casos de falla del artículo son exactamente lo que vas a enfrentar si no lo hacés.
La combinación que tiene sentido ahora: IAM Access Analyzer en el pipeline, Policy Simulator para casos cross-service críticos, y CloudTrail Last Accessed para las auditorías periódicas. Si además operás multi-cuenta, asegurate de que el testing incluya las SCPs de la cuenta destino, no solo la política en aislamiento.
Fuentes
- Building Automated AWS Permission Testing Infrastructure for CI/CD – caso completo con los 5 deploys documentados
- AWS Prescriptive Guidance – patrón de referencia con CodePipeline, IAM Access Analyzer y CloudFormation macros
- IAM Access Analyzer – página oficial del servicio
- iam-policy-tester-pipeline – repositorio de ejemplo de AWS en GitHub