40 CVEs en infraestructura IA: lo que tenés que saber
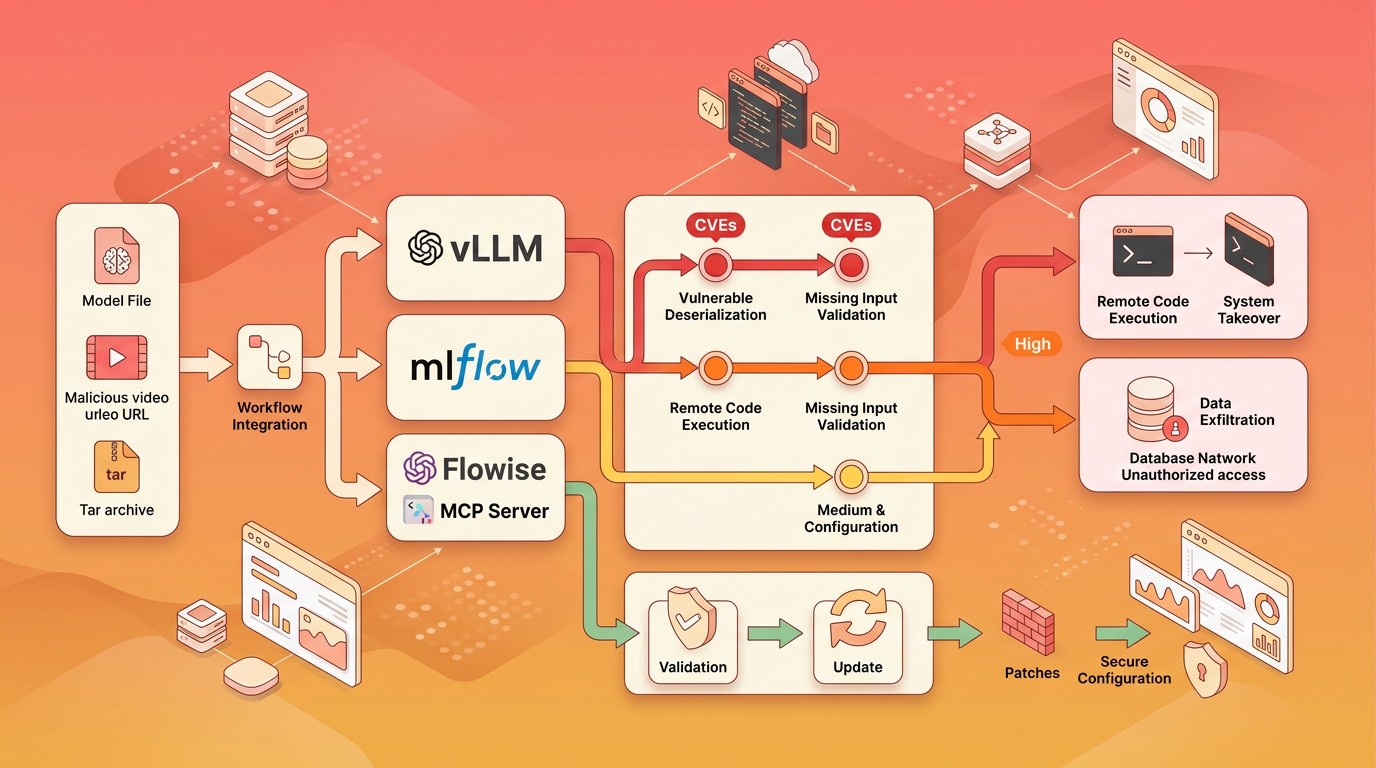
En marzo de 2026, un conjunto de 22 advisories de seguridad expuso 40 CVEs críticos en la infraestructura de IA/ML más usada del mundo: MLflow, vLLM, PyTorch, Flowise, servidores MCP y herramientas de Hugging Face. Estas vulnerabilidades en infraestructura de IA afectan a organizaciones que entrenan, despliegan y sirven modelos de machine learning en producción, con exploits que van desde ejecución remota de código (RCE) sin autenticación hasta envenenamiento de la cadena de suministro de modelos. Se publicaron 94 reglas Sigma para detección, pero solo el 14% de las organizaciones tiene capacidad real para gestionar estos riesgos.
En 30 segundos
- Se reportaron 40 CVEs en 22 advisories que afectan a vLLM, MLflow, Flowise, PyTorch, servidores MCP y Hugging Face, con 94 reglas Sigma publicadas para detección en SIEM
- vLLM tiene una vulnerabilidad crítica (CVE-2026-22778, CVSS 9.8) que permite ejecución remota de código sin autenticación a través de una URL de video maliciosa — la versión parcheada es 0.14.1
- Los servidores MCP acumularon 30 CVEs en apenas 60 días entre enero y febrero de 2026, con el 43% causados por inyección de comandos shell
- Hugging Face detectó 352.000 modelos sospechosos de 4.47 millones escaneados, incluyendo técnicas de evasión que bypassean los scanners actuales
- PyTorch propagó vulnerabilidades RCE a vLLM, SGLang y otros frameworks a través de reutilización de código inseguro con ZeroMQ y pickle (efecto “ShadowMQ”)
La infraestructura de inteligencia artificial y machine learning (IA/ML) es el conjunto de herramientas, frameworks y plataformas que las organizaciones usan para entrenar, desplegar y servir modelos. Incluye desde trackers de experimentos como MLflow hasta motores de inferencia como vLLM y plataformas de distribución como Hugging Face. Durante el primer trimestre de 2026, esta infraestructura quedó expuesta como uno de los eslabones más débiles de la cadena de seguridad corporativa. No se trata de vulnerabilidades teóricas: hay exploits funcionales, ataques documentados y un ecosistema que creció más rápido de lo que sus prácticas de seguridad pueden sostener.
El estado de la seguridad en infraestructura de IA/ML en 2026
El panorama es concreto: 22 advisories de seguridad publicados, 40 CVEs catalogados y 94 reglas Sigma de detección disponibles. Los frameworks afectados no son proyectos de nicho — MLflow tiene más de 20.000 estrellas en GitHub, vLLM es el motor de inferencia preferido para LLMs en producción, y Flowise se posicionó como la plataforma low-code de referencia para automatizaciones con IA. Cuando hablamos de vulnerabilidades en infraestructura de IA, estamos hablando de herramientas que corren en los servidores de bancos, healthtech y startups por igual.
El problema de fondo es estructural. La infraestructura de ML se construyó para investigación, no para producción. Frameworks como PyTorch priorizaron flexibilidad y velocidad de prototipado, y cuando las empresas los adoptaron masivamente para deployments en producción, arrastraron prácticas de seguridad que no estaban pensadas para entornos expuestos a internet. Según distintos reportes de la industria, solo el 14% de las organizaciones que usan infraestructura de ML tiene procesos maduros para gestionar vulnerabilidades en estos componentes. El resto confía en que “es código open source, alguien lo revisa”. Nadie lo revisaba.
Eso sí: la publicación de 94 reglas Sigma es una señal positiva. Significa que la comunidad de seguridad está empezando a tratar la infra de IA como lo que es — superficie de ataque crítica. Pero entre publicar reglas y que los SOC las implementen hay un trecho largo, sobre todo en Latinoamérica donde muchos equipos todavía no tienen SIEM configurado para este tipo de detección. Si te interesa, podés leer más sobre el reciente ataque a Trivy en GitHub Actions.
vLLM: ejecución remota de código con un enlace de video
La vulnerabilidad más grave del lote es CVE-2026-22778, con un CVSS de 9.8 sobre 10. Permite ejecutar código arbitrario en un servidor vLLM sin necesidad de autenticación. El vector de ataque es casi absurdo por lo simple: un atacante envía una URL que apunta a un supuesto archivo de video, y el parser de medios de vLLM lo procesa sin validación, ejecutando código embebido en el payload. No hace falta credenciales, no hace falta acceso previo. Si tu instancia de vLLM está expuesta a internet (y muchas lo están), sos vulnerable.
Pero CVE-2026-22778 no es la única. CVE-2025-62164 permite corrupción de memoria a través de tensores sparse malformados — un ataque más sofisticado pero igual de peligroso en entornos de inferencia que aceptan inputs de usuarios. Y CVE-2025-66448 es particularmente preocupante: permite RCE a través del parámetro auto_map en la configuración de modelos, incluso cuando el servidor tiene trust_remote_code=False. Es decir, la flag de seguridad que supuestamente te protege no te protege.
La versión parcheada es vLLM 0.14.1. Si estás corriendo cualquier versión anterior en producción, la recomendación es directa: actualizá ya. No mañana, no la semana que viene. Un ejemplo concreto: una fintech en Brasil reportó que detectó intentos de explotación de CVE-2026-22778 en sus endpoints de inferencia apenas 72 horas después de la publicación del advisory. Los atacantes leen los CVEs tan rápido como los defensores.
MLflow: del directory traversal al RCE completo
MLflow es el hub central de modelos para miles de organizaciones. Lo usan para trackear experimentos, versionar modelos y servir artefactos. CVE-2025-11201 es un directory traversal en el Tracking Server que permite a un atacante leer archivos arbitrarios del sistema. El investigador de ZeroPath que lo descubrió demostró que se puede escalar desde la lectura de archivos hasta ejecución remota de código completa en configuraciones estándar.
CVE-2025-15031 va un paso más allá: permite escritura arbitraria de archivos a través de tar traversal. Un atacante sube un archivo tar malicioso como artefacto de modelo, y cuando MLflow lo procesa, extrae archivos fuera del directorio esperado. Podés terminar con un webshell en el servidor o con credenciales sobrescritas. CVE-2025-0453 es un DoS por consumo de recursos — menos glamoroso pero igual de efectivo para tirar abajo una plataforma de ML en plena inferencia.
Lo que me parece más preocupante son CVE-2025-1474 y CVE-2025-11200, que exponen problemas de contraseñas débiles en la autenticación de MLflow. El tema es que muchas organizaciones despliegan MLflow en redes internas y asumen que “no necesita seguridad porque está atrás del firewall”. Esa mentalidad es exactamente lo que los atacantes explotan con movimiento lateral. Una vez que un atacante tiene un pie en la red (phishing, VPN comprometida, cualquier cosa), MLflow es un target jugoso: tiene acceso a modelos, datos de entrenamiento y frecuentemente a credenciales de cloud.
Flowise: 7 vulnerabilidades críticas en una plataforma low-code
Flowise ganó popularidad como la forma fácil de construir flujos de IA sin escribir código. El problema es que “fácil” y “seguro” rara vez van de la mano. CVE-2025-8943 y CVE-2025-55346 permiten RCE a través de Custom MCPs, ambos con CVSS 9.8. Un atacante puede crear un conector MCP malicioso que ejecuta código arbitrario en el servidor cuando un usuario lo activa.
CVE-2025-58434 permite resetear la contraseña de cualquier usuario sin autorización. Leíste bien: no necesitás la contraseña actual, no necesitás un token de recuperación, simplemente mandás el request y cambiás la password de quien quieras. CVE-2025-57164 permite RCE a través del Supabase RPC Filter — si tu instancia de Flowise está conectada a Supabase (como muchas lo están), un atacante puede ejecutar código a través de queries RPC malformadas. CVE-2025-26319 completa el cuadro con upload arbitrario de archivos.
El factor común en todas estas vulnerabilidades es la falta de RBAC (Role-Based Access Control). Flowise no tenía un sistema de permisos granular, así que o tenías acceso a todo o no tenías acceso a nada. El advisory de marzo de 2026 sumó otro hallazgo: bypass de autorización vía header spoofing. Un atacante podía falsificar headers HTTP para hacerse pasar por un usuario autenticado. Para una plataforma que se usa para automatizar flujos con acceso a APIs, bases de datos y servicios externos, estas fallas son particularmente graves. Si usás Flowise en producción, la recomendación es ponerlo atrás de un proxy con autenticación propia y no confiar en los mecanismos internos de la plataforma hasta que los parchen. Si te interesa, podés leer más sobre repos de Python infectados con malware.
Servidores MCP: 30 CVEs en 60 días
Los servidores MCP (Model Context Protocol) tuvieron su propia crisis de seguridad entre enero y febrero de 2026. En apenas 60 días se reportaron 30 CVEs, un volumen que deja claro que el ecosistema MCP creció sin que nadie se detuviera a pensar en seguridad. El desglose es revelador: el 43% de los CVEs fueron por inyección de comandos shell, el 20% por fallos en tooling, y el 13% por bypass de autenticación.
Según un análisis detallado de la situación MCP en 2026, CVE-2026-23744 permite RCE en MCPJam Inspector, una herramienta que muchos desarrolladores usan para debuggear sus integraciones MCP. CVE-2026-26118 es un SSRF (Server-Side Request Forgery) en Azure MCP Server Tools — permite a un atacante hacer que el servidor MCP haga requests a servicios internos de Azure que no deberían ser accesibles desde afuera. El dato más alarmante: el 36.7% de los servidores MCP expuestos a internet son vulnerables a SSRF.
Incluso el Git MCP Server desarrollado por Anthropic (la empresa detrás de Claude) tuvo una cadena de vulnerabilidades que permitía encadenar ataques. El tema es que MCP es un protocolo relativamente nuevo que conecta LLMs con herramientas externas, y la velocidad con la que la comunidad creó servidores MCP superó ampliamente la capacidad de auditarlos. Muchos servidores MCP se escribieron como proyectos de fin de semana, se publicaron en GitHub, y terminaron en producción sin que nadie revisara si sanitizan inputs. La inyección de comandos shell — el vector más frecuente — es un error de seguridad que se conoce desde los años 90, pero aparentemente se redescubre cada vez que aparece un paradigma nuevo.
Hugging Face y la cadena de suministro de modelos
Hugging Face publicó los resultados de su partnership de 6 meses con Protect AI, y los números son contundentes. De 4.47 millones de versiones de modelos escaneados, 352.000 resultaron sospechosos. Eso es casi el 8% del total. No todos son maliciosos — muchos tienen vulnerabilidades no intencionales — pero la escala del problema es enorme.
Una técnica de evasión particularmente ingeniosa usa formato 7z en lugar de ZIP para empaquetar modelos maliciosos. Los scanners como Picklescan están optimizados para detectar payloads en archivos pickle dentro de ZIPs, pero cuando el mismo payload se comprime con 7z, pasa desapercibido. Es el equivalente en ML de meter malware en un formato de archivo que el antivirus no escanea.
La vulnerabilidad conocida como “Hydra” afecta a Meta y se propagó a frameworks de terceros: NeMo de NVIDIA, Uni2TS de Salesforce y FlexTok de Apple. El patrón es siempre el mismo: un modelo que parece legítimo contiene código que se ejecuta al cargarlo. La diferencia con malware tradicional es que acá el “ejecutable malicioso” es un modelo de ML que todo el mundo descarga y corre sin pensarlo dos veces. También se detectaron modelos con pickle roto intencionalmente — archivos que fallan la deserialización estándar pero ejecutan código durante el intento fallido, evadiendo scanners que solo buscan deserializaciones exitosas.
Hugging Face implementó módulos de detección nuevos como PAIT-ARV-100 (archive slip), PAIT-JOBLIB-101 (ejecución sospechosa en Joblib) y PAIT-TF-200 (backdoors arquitecturales en TensorFlow SavedModel). Pero me parece que el problema de fondo es cultural: la comunidad de ML trata los modelos como datos, no como código ejecutable. Y eso tiene que cambiar. Si te interesa, podés leer más sobre integrar APIs de IA en tus proyectos.
PyTorch y el efecto dominó en el ecosistema de IA
Oligo Security acuñó el término “ShadowMQ” para describir un patrón que encontraron: el uso inseguro de ZeroMQ y pickle en PyTorch se propagó como vulnerabilidad RCE a vLLM, SGLang y otros frameworks que reutilizaron ese código. El mecanismo es simple — PyTorch usa ZeroMQ para comunicación entre procesos y pickle para serializar objetos. Pickle es inherentemente inseguro para deserializar datos no confiables (puede ejecutar código arbitrario), pero PyTorch lo usa internamente y lo documenta como “seguro para uso local”.
El problema aparece cuando proyectos como vLLM y SGLang copian o importan ese patrón de comunicación para sus propios workers distribuidos. Lo que era “seguro para uso local” en el contexto de PyTorch termina expuesto a la red en el contexto de un motor de inferencia que acepta conexiones remotas. Un atacante que puede alcanzar el puerto ZeroMQ de un worker puede enviar un objeto pickle malicioso y obtener RCE. Meta, NVIDIA y Microsoft tienen deployments afectados por esta cadena de reutilización.
El concepto de ShadowMQ es más amplio que un bug puntual: es un vector sistémico. Cuando un framework fundacional tiene un patrón de código inseguro y cientos de proyectos lo copian, una sola vulnerabilidad se multiplica por toda la cadena de dependencias. No basta con parchear PyTorch — hay que auditar cada proyecto que copió ese patrón. Y acá entra un caveat honesto: no está claro cuántos proyectos hicieron esa copia. Oligo identificó los más grandes, pero el long tail de proyectos más chicos que reutilizan código de PyTorch sin auditoría es potencialmente enorme.
94 reglas Sigma y cómo implementar detección
Las reglas Sigma son un estándar abierto para escribir detecciones de seguridad que se pueden convertir a cualquier SIEM (Splunk, Elastic, Microsoft Sentinel, etc.). Las 94 reglas publicadas cubren los 40 CVEs reportados y se enfocan en tres patrones principales: inyección de comandos en servidores MCP, deserialización insegura de pickle en frameworks de ML, y acceso no autenticado a APIs de gestión de modelos.
Para un equipo de SOC que quiera implementar estas detecciones, el flujo es: descargar las reglas Sigma, convertirlas al formato de tu SIEM usando Uncoder.io (herramienta gratuita de SOC Prime), y desplegarlas. Un ejemplo concreto: la regla para detectar explotación de CVE-2026-22778 en vLLM busca requests HTTP con payloads de video que contengan patrones de serialización sospechosos en los headers. Otra regla detecta intentos de directory traversal contra endpoints de MLflow buscando secuencias ../ en paths de artefactos.
Ahora bien, implementar 94 reglas de golpe sin tunear va a generar falsos positivos. La recomendación práctica es priorizar: primero las reglas de RCE (las de CVSS 9.0+), después las de acceso no autenticado, y por último las de DoS y escalación de privilegios. Si tu equipo es chico o no tiene experiencia con Sigma, empezá por las 10 reglas que cubren los CVEs con CVSS mayor a 9.0 y sumá el resto gradualmente. También es buena práctica correr las reglas en modo “solo alertar” durante una semana antes de activar respuestas automáticas, para calibrar los umbrales. Si te interesa, podés leer más sobre herramientas de integración y automatización.
| Plataforma | CVEs principales | CVSS máximo | Vector principal | Versión parcheada | Riesgo en producción |
|---|---|---|---|---|---|
| vLLM | CVE-2026-22778, CVE-2025-62164, CVE-2025-66448 | 9.8 | RCE sin auth vía URL de video | 0.14.1 | Crítico |
| MLflow | CVE-2025-11201, CVE-2025-15031, CVE-2025-0453 | 8.8 | Directory traversal → RCE | 2.21+ | Alto |
| Flowise | CVE-2025-8943, CVE-2025-55346, CVE-2025-58434 | 9.8 | RCE vía Custom MCPs | 2.2.8+ | Crítico |
| Servidores MCP | CVE-2026-23744, CVE-2026-26118 (+28 más) | 9.1 | Inyección shell (43% de CVEs) | Varía por servidor | Alto |
| PyTorch/ShadowMQ | Múltiples (propagados a vLLM, SGLang) | 8.5 | Deserialización pickle vía ZeroMQ | Sin parche unificado | Alto |
| Hugging Face Hub | 352K modelos sospechosos detectados | Variable | Modelos maliciosos con evasión de scanners | Nuevos módulos de detección activos | Medio-Alto |
Qué significa para empresas y equipos en Latinoamérica
En la región, la adopción de infraestructura de ML viene creciendo fuerte, especialmente en fintechs, healthtech y equipos de datos en empresas medianas. El problema es que la mayoría de estos deployments se hicieron sin un equipo de seguridad dedicado a infra de IA. Si sos un equipo de datos en Argentina, Colombia o México que levantó un vLLM para servir un modelo fine-tuneado, probablemente no tenés un WAF configurado para ese endpoint ni reglas de detección específicas.
La recomendación más práctica: hacé un inventario de qué frameworks de ML tenés expuestos a la red (aunque sea red interna). Verificá las versiones contra los CVEs listados arriba. Y si necesitás infraestructura para correr modelos en producción con aislamiento de red adecuado, Donweb ofrece VPS y servidores dedicados donde podés configurar reglas de firewall y segmentar la red para que tu infra de ML no quede expuesta directamente.
Errores comunes
Confiar en trust_remote_code=False como medida de seguridad suficiente
Muchos equipos configuran trust_remote_code=False en vLLM y asumen que están protegidos contra código malicioso en modelos. CVE-2025-66448 demostró que un atacante puede bypassear esa flag usando auto_map en la configuración del modelo. La flag reduce la superficie de ataque pero no la elimina. Necesitás complementarla con validación de modelos antes de cargarlos y monitoreo de comportamiento post-carga.
Tratar MLflow como una herramienta interna que no necesita hardening
MLflow se despliega frecuentemente en redes internas sin autenticación, con la lógica de que “solo lo usa el equipo de datos”. Pero un atacante con acceso a la red interna (post-phishing, VPN comprometida, o lateral movement) encuentra en MLflow un target ideal: tiene modelos, datos de entrenamiento y frecuentemente tokens de acceso a cloud. Activá siempre autenticación, usá contraseñas fuertes (CVE-2025-1474 demostró que las default son débiles) y restringí acceso por IP.
Descargar modelos de Hugging Face sin escanearlos
El 8% de los modelos escaneados por Hugging Face resultó sospechoso. Sin embargo, la mayoría de los equipos hace from_pretrained("nombre/modelo") sin ningún paso de validación previo. Antes de cargar un modelo en producción, pasalo por Picklescan o por las herramientas de escaneo de Hugging Face. Y tené en cuenta que los atacantes ya conocen las limitaciones de Picklescan (evasión con 7z, pickle roto intencional), así que el escaneo es necesario pero no suficiente — combinalo con sandboxing en la carga.
Esto se conecta con AI/ML infrastructure, donde cubrimos cómo la IA impacta la infraestructura moderna.
Preguntas Frecuentes
¿Qué vulnerabilidades críticas tienen vLLM, MLflow y PyTorch en 2026?
vLLM tiene CVE-2026-22778 (CVSS 9.8), que permite ejecución remota de código sin autenticación a través de URLs de video maliciosas. MLflow tiene CVE-2025-11201, un directory traversal que escala a RCE completo en el Tracking Server. PyTorch no tiene un CVE puntual nuevo, pero su uso inseguro de ZeroMQ y pickle propagó vulnerabilidades RCE a vLLM, SGLang y otros frameworks a través de reutilización de código (efecto ShadowMQ documentado por Oligo Security). Si te interesa, podés leer más sobre la competencia entre gigantes de la IA.
¿Es seguro usar servidores MCP en producción?
En su estado actual, la mayoría de los servidores MCP no están listos para producción sin hardening adicional. Entre enero y febrero de 2026 se reportaron 30 CVEs, el 43% por inyección de comandos shell y el 36.7% de los servidores expuestos son vulnerables a SSRF. Si vas a usar MCP en producción, poné los servidores atrás de un proxy autenticado, sanitizá todos los inputs, y monitoreá con las reglas Sigma publicadas.
¿Cómo se detectan ataques a infraestructura de machine learning?
Las 94 reglas Sigma publicadas cubren los principales vectores: inyección de comandos en MCP, deserialización pickle maliciosa, y acceso no autenticado a APIs de ML. Se importan a cualquier SIEM (Splunk, Elastic, Sentinel) usando Uncoder.io para la conversión de formato. La prioridad es implementar primero las reglas de RCE (CVEs con CVSS 9.0+) y después sumar detecciones de menor severidad.
¿Qué riesgos tiene descargar modelos de Hugging Face?
De 4.47 millones de modelos escaneados, 352.000 resultaron sospechosos. Los atacantes usan técnicas como empaquetar payloads en formato 7z para evadir Picklescan, o crear archivos pickle intencionalmente rotos que ejecutan código durante el intento fallido de deserialización. Antes de cargar un modelo en producción, escanealo con las herramientas de Hugging Face y cargalo en un sandbox aislado.
Conclusión
Lo que muestran estos 40 CVEs es que la infraestructura de IA tiene un problema de seguridad sistémico, no puntual. No es un framework con un bug — son todos los frameworks con bugs similares, propagados por reutilización de código, falta de RBAC, y una cultura que trata la seguridad como un problema de “después”. La cadena de suministro de modelos (Hugging Face con 352.000 modelos sospechosos) agrega una capa de riesgo que no existía hace dos años.
Para los equipos que usan estas herramientas, las acciones concretas son: actualizar vLLM a 0.14.1, auditar la configuración de MLflow (autenticación y acceso de red), evaluar si Flowise necesita un proxy con auth propia, y no confiar ciegamente en modelos descargados de repositorios públicos. Las 94 reglas Sigma son un buen punto de partida para detección, pero requieren un SIEM funcional y un equipo que sepa interpretarlas. Lo que conviene seguir de cerca es la evolución de los servidores MCP — con 30 CVEs en 60 días, ese ecosistema todavía no tocó fondo.
Fuentes
- Orca Security – Análisis técnico de CVE-2026-22778 en vLLM
- Hugging Face – Reporte de 6 meses de partnership con Protect AI sobre seguridad de modelos
- Oligo Security – ShadowMQ: cómo la reutilización de código propagó vulnerabilidades en el ecosistema de IA
- ZeroPath – CVE-2025-11201: directory traversal a RCE en MLflow
- SecurityOnline – Vulnerabilidades críticas de RCE en Flowise AI





