Feature flags en tiempo real con Rust y WebAssembly
Un equipo de producto quiere activar una función nueva para el 5% de los usuarios, medir cómo se comporta y, si algo explota, apagarla en segundos sin tocar un deploy. Eso es lo que resuelve un sistema de feature flags en tiempo real basado en event sourcing: en vez de guardar un booleano suelto, guardás cada cambio como un evento inmutable. Append-only, auditable, reversible.
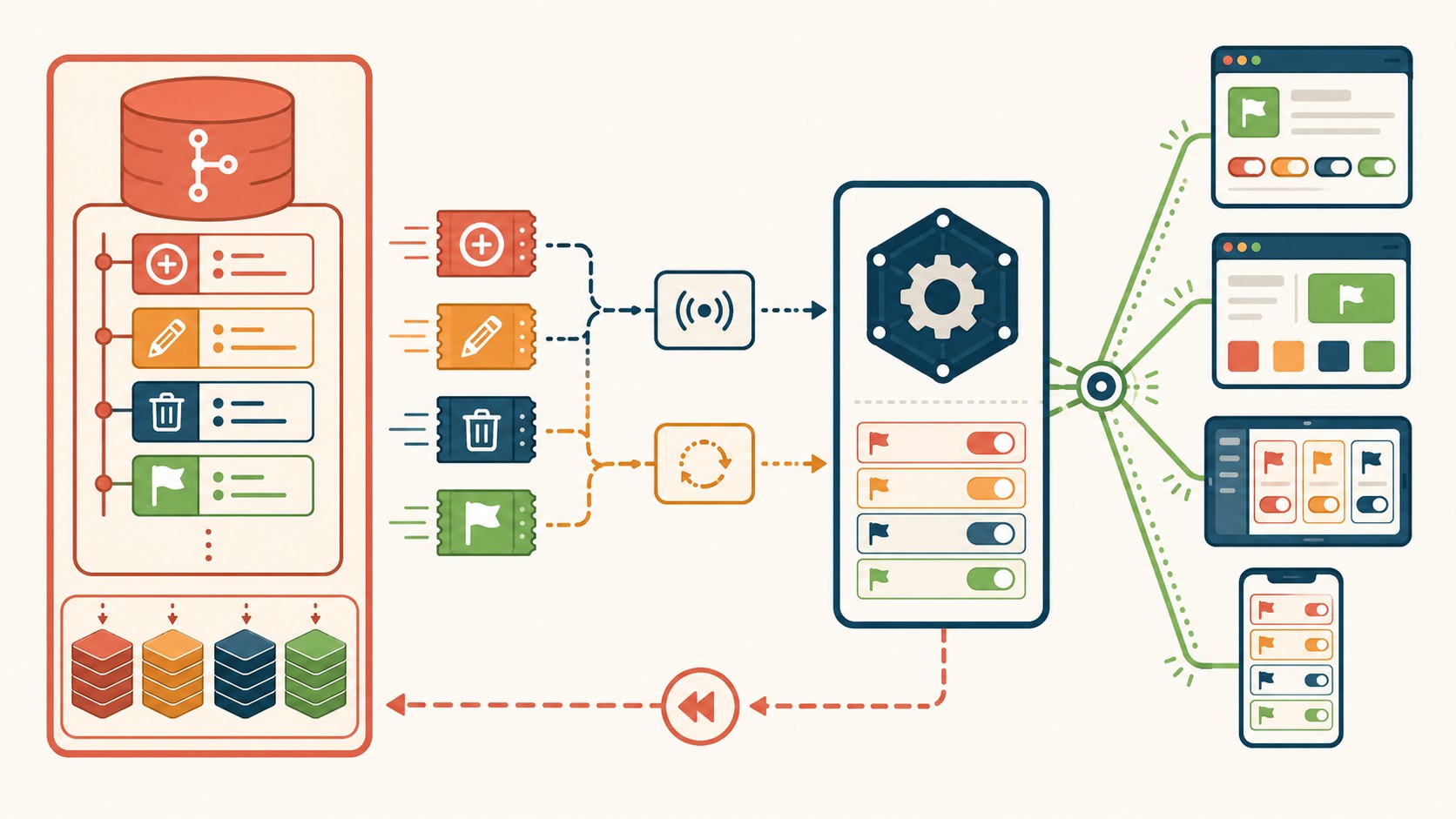
Un sistema de feature flags basado en event sourcing es una arquitectura donde cada acción sobre una bandera (crearla, actualizarla, borrarla, evaluarla) se persiste como un evento ordenado en un log que solo crece. El estado actual de cada flag se reconstruye reproduciendo esos eventos. Sirve para auditar quién cambió qué, revertir al instante y hacer despliegues graduales con bajo riesgo en aplicaciones web modernas.
En 30 segundos
- Qué es: un servicio de feature flags donde cada cambio se guarda como evento (FlagCreated, FlagUpdated, FlagDeleted, FlagEval) en un log append-only.
- Stack del tutorial: event store en Rust, cliente compilado a WebAssembly y un servidor Node.js de orquestación, publicado el 3 de junio de 2026 en dev.to.
- Tiempo real: los cambios se propagan a los clientes vía Server-Sent Events (SSE), con polling como fallback.
- Por qué importa: el WASM evalúa las flags en el navegador, sin round-trip al servidor, con latencia mínima.
- El riesgo real: reutilizar el nombre de una flag ya retirada puede reactivar código viejo y salir caro. La gestión descuidada cuesta plata.
¿Por qué guardar cada cambio como un evento y no un simple booleano?
La forma fácil es tener una tabla con feature_x = true. Funciona hasta que alguien pregunta: ¿quién la activó? ¿cuándo? ¿por qué estaba apagada el martes? Con un booleano no tenés respuesta. El valor anterior se perdió en el momento en que lo pisaste.
El event sourcing le da vuelta el problema. Según el tutorial publicado en dev.to, en lugar de almacenar el estado, almacenás la secuencia de eventos que llevaron a ese estado. Cada evento es inmutable. Nunca se borra, solo se agrega uno nuevo arriba.
- Auditabilidad completa: tenés el historial exacto de cada flag, con autor y momento de cada cambio.
- Rollbacks seguros: para revertir no borrás nada, agregás un evento que devuelve la flag a su estado anterior.
- Reconstrucción del pasado: podés reproducir el log hasta cualquier punto y ver cómo estaba el sistema ese día a esa hora.
El tema es que reproducir miles de eventos cada vez que arranca el servidor sería lento. Por eso se usan snapshots: cada tanto guardás una foto del estado y desde ahí solo reproducís los eventos nuevos. El log sigue siendo la fuente de verdad, el snapshot es un atajo. Te puede servir nuestra cobertura de como verás en nuestra comparativa de pipelines.
¿Qué ventaja real dan Rust y WebAssembly acá?
Rust corre sin runtime ni garbage collector. Para un event store que evalúa flags miles de veces por segundo, esa ausencia de pausas importa. No hay un GC que se despierte en el peor momento y te meta latencia justo cuando el tráfico pega un pico.
WebAssembly es la otra mitad. ¿Por qué compilar el evaluador a WASM en vez de pegarle al servidor cada vez? Porque el round-trip te cuesta milisegundos que el usuario siente. Con el evaluador corriendo dentro del navegador, la decisión “¿le muestro esta función o no?” se resuelve local, sin red de por medio.
- Latencia mínima: la evaluación pasa en el cliente, sin llamada al servidor por cada flag.
- Seguridad de memoria: Rust garantiza en tiempo de compilación que no haya accesos inválidos, algo crítico en código que corre en cada sesión.
- Portabilidad: el módulo WASM funciona en cualquier navegador moderno y también offline, porque la lógica ya está del lado del cliente.
Ojo: esto no significa tirar Node.js a la basura. En el diseño del tutorial, Node sigue ahí como capa de orquestación. Rust hace el trabajo pesado del store, WASM evalúa rápido en el cliente, y Node coordina. Cada pieza en lo que es buena.
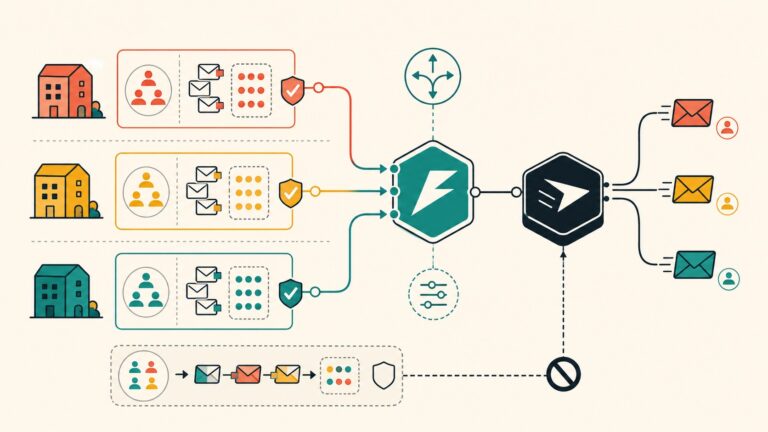
¿Cómo se conectan el Event Store, el cliente WASM y la sincronización?
Son tres componentes. El Event Store en Rust es un log append-only respaldado por una base de datos simple basada en archivos, con soporte de snapshots. Guarda los eventos del ciclo de vida de cada flag. Complementá con implementación típica en sistemas de integración continua.
El cliente WASM es una biblioteca chica compilada a WebAssembly que se embebe en la app de frontend y evalúa las flags ahí mismo. Y la sincronización en tiempo real usa SSE para empujar los cambios a los clientes apenas pasan, con un poller de respaldo por si la conexión SSE se cae.
El flujo es así: cambiás una flag, el servidor escribe el evento en el store, lo emite por SSE, y cada cliente WASM actualiza su estado local sin pedir permiso ni esperar. Si querés montar esto sobre infraestructura propia con buena latencia en la región, conviene alojarlo cerca de tus usuarios; para hosting y servidores en Argentina podés ver donweb.com.
¿Cómo implementar el event store en Rust paso a paso?
Primero definís el schema de eventos. Algo compacto: un tipo de evento, un identificador de flag, un timestamp y los datos del cambio. Los cuatro eventos del ciclo de vida son FlagCreated, FlagUpdated, FlagDeleted y FlagEval (este último registra cada evaluación, útil para observabilidad).
Después elegís la persistencia. El tutorial arranca con una base de datos basada en archivos, lo más simple para empezar. Si necesitás algo más robusto, podés mover el store a PostgreSQL. Para el patrón CQRS y event sourcing en Rust, la documentación de cqrs-es es un buen punto de partida.
- Capturá los eventos de ciclo de vida: cada operación sobre una flag genera un evento que se agrega al log.
- Implementá snapshotting: guardá el estado consolidado cada N eventos para no reproducir todo el log al arrancar.
- Mantené el append-only: nunca edites un evento viejo. Si algo cambió, va un evento nuevo.
Si venís de Node y querés integrar feature flags sin armar el store desde cero, la guía de Unleash para Rust muestra el lado cliente del problema.
¿Cómo hacer un rollout gradual y canario sin downtime?
Ponele que tenés una función nueva de checkout. No la prendés para todos de golpe. La activás para el 1%, mirás los errores, subís al 5%, al 20%. Si los números vienen flojos, un evento de rollback y volvés a cero. Sin redeploy, sin esperar.
Las estrategias clásicas son tres: por porcentaje de usuarios, por segmento (ponele, solo cuentas premium) y canary deployment, donde un grupo chico prueba antes que el resto. La guía de buenas prácticas de ConfigCat insiste en algo: el rollout sin monitoreo es tirar a ciegas. Tenés que mirar mientras subís el porcentaje.
Acá es donde el SSE brilla. Cuando bajás una flag del 20% al 0% por una emergencia, ese cambio llega a todos los clientes en tiempo real. No hay que esperar a que el navegador del usuario decida refrescar. La propagación es inmediata. Relacionado: estrategias análogas para entornos multirregión.
¿Qué herramientas comparar antes de armar lo tuyo?
| Opción | Tipo | Evaluación | Cuándo conviene |
|---|---|---|---|
| Sistema event-sourced propio (Rust + WASM) | Self-hosted | Cliente (WASM), latencia mínima | Control total, auditoría estricta, equipo con Rust |
| Unleash | Open source / SaaS | SDK servidor y cliente | Querés estándar maduro sin construir el store |
| ConfigCat | SaaS | SDK con cache local | Buenas prácticas listas, sin mantener infra |
| GrowthBook | Open source / SaaS | SDK con A/B testing integrado | Experimentación y feature flags en un solo lugar |
La “regla de oro” no existe acá. Si tu equipo no sabe Rust, armar un event store a mano probablemente sea más costo que beneficio. Si en cambio la auditoría es un requisito duro (fintech, salud), tener el log inmutable bajo tu control vale el esfuerzo.
Errores comunes al implementar feature flags
El análisis de GrowthBook sobre los errores más comunes recopila los sospechosos de siempre. Estos son los que más duelen.
- Flags zombis: dejás una flag prendida “temporalmente” y ahí queda dos años. Cada flag viva es deuda técnica. Ponele fecha de expiración y dueño desde el día uno.
- Reutilizar nombres de flags: reusar un nombre de bandera ya retirado puede disparar código viejo y provocar incidentes caros. No recicles nombres. Nunca.
- Flags que dependen entre sí: cuando flag A solo tiene sentido si flag B está activa, creás una combinatoria que nadie entiende. Mantené las flags independientes.
- Activación masiva sin etapas: prender una función para el 100% de una es el opuesto de un canary. Si falla, falla para todos al mismo tiempo.
- Gestión manual descentralizada: cada dev cambiando flags por su lado, sin registro central. Sin un log de eventos, perdés la trazabilidad. (Justo lo que el event sourcing resuelve.)
¿Cómo monitorear las flags una vez en producción?
Una flag sin observabilidad es una caja negra. Lo mínimo es conectar el estado de cada bandera a las métricas del producto: conversión, latencia, tasa de error. Si activás una función y la conversión cae, querés verlo en un dashboard, no por un cliente enojado.
El evento FlagEval del que hablábamos sirve justo para esto. Cada evaluación queda registrada, así que podés graficar cuántos usuarios cayeron de cada lado del rollout en tiempo real. Sumale alertas para cuando una flag temporal lleva más tiempo activo del esperado, y logging centralizado de quién cambió qué. Con eso, la próxima vez que algo se rompa, el historial te dice exactamente en qué evento empezó el problema.
Preguntas Frecuentes
¿Qué ventaja tiene un sistema de feature flags en tiempo real?
Los cambios se propagan a todos los clientes al instante vía SSE, sin redeploy ni espera. Si una función falla en producción, la apagás en segundos para todos los usuarios. Eso reduce el blast radius de un incidente y permite experimentar sin riesgo de quedar atado a un release. Sobre eso hablamos en como ocurre en sistemas distribuidos y descentralizados.
¿Cómo se implementan feature flags con Rust y WebAssembly?
Se arma un event store en Rust con un log append-only y snapshots, y se compila el evaluador de flags a WebAssembly para embeberlo en el frontend. El cliente WASM evalúa las banderas en el navegador con latencia mínima, mientras un servidor orquesta y sincroniza vía SSE.
¿Cuál es la diferencia entre event sourcing y snapshots?
El event sourcing guarda cada cambio como un evento inmutable en un log que solo crece, y reconstruye el estado reproduciéndolos. El snapshot es una foto del estado consolidado en un momento dado. El log es la fuente de verdad; el snapshot es un atajo para no reproducir miles de eventos al arrancar.
¿Cómo hacer un rollout gradual seguro sin downtime?
Activá la función para un porcentaje chico de usuarios (1% a 5%), monitoreá errores y conversión, y subí el porcentaje de a poco. Si algo sale mal, un evento de rollback la devuelve a cero sin tocar un deploy. La clave es no prender nunca al 100% de una sola vez.
¿Cuál es el error más caro al usar feature flags?
Reutilizar el nombre de una flag ya retirada: un nombre reciclado puede disparar código viejo y provocar fallas costosas en producción. La regla es no reusar nombres nunca y eliminar las flags zombis con fecha de expiración y dueño asignado desde el inicio.
Conclusión
Un feature flag no tiene por qué ser un booleano suelto que nadie audita. El enfoque event-sourced que mostró el tutorial del 3 de junio de 2026 cambia eso: cada decisión queda registrada, cada rollback es seguro y la combinación Rust más WASM te da evaluación en el cliente sin pagar latencia de red.
¿Vale armarlo a mano? Depende. Si tu equipo no maneja Rust o no necesitás auditoría estricta, una herramienta como Unleash o ConfigCat te ahorra meses. Si en cambio el log inmutable es un requisito (fintech, salud, cualquier cosa regulada), construir el store propio te da un control que ningún SaaS te da. Empezá por definir tu schema de eventos y ponele fecha de muerte a cada flag desde el día uno. Las zombis son las que terminan costando millones.
Fuentes
- dev.to – Tutorial original: Building a Real-Time, Event-Sourced Feature Flag System with Rust and WebAssembly
- Unleash – Guía para implementar feature flags en Rust
- ConfigCat – Buenas prácticas de feature flags
- GrowthBook – Errores comunes al usar feature flags
- cqrs-es – Documentación de CQRS y event sourcing en Rust