Arquitectura multi-tenant SaaS: la decisión de la semana 1
La decisión que más errores genera al construir un SaaS no es qué lenguaje usás ni en qué nube lo desplegás: es cómo separás los datos de cada cliente. La arquitectura multi-tenant saas se define en la semana 1 y, si la elegís mal, te perseguís hasta que el producto escala. Después es carísimo de cambiar.
Arquitectura multi-tenant es un modelo donde una sola instancia de la aplicación y su código atienden a varios clientes (los “tenants”) al mismo tiempo, manteniendo los datos de cada uno aislados. El SaaS es el modelo de negocio; la multi-tenancy es la decisión técnica que lo hace rentable. Pensá un edificio: todos comparten estructura y servicios, pero nadie entra al departamento del otro.
En 30 segundos
- Tres modelos: base compartida con tenant ID, base separada por cliente, o híbrido con schemas de PostgreSQL.
- Para arrancar: base compartida con tenant ID en cada tabla. Más barata y suficiente hasta que tengas clientes enterprise.
- El riesgo número uno: olvidar un filtro de tenant en una sola query. Eso es un data leak, y para un SaaS con datos sensibles es game over.
- La solución estructural: middleware que inyecta el tenant en cada request, para que olvidar el filtro sea difícil por diseño.
- Error clásico: diseñar para el tráfico de Amazon cuando todavía no tenés product-market fit.
¿Por qué un SaaS es distinto a un software a medida?
Un software custom se construye una vez para un cliente. Listo.
Un SaaS se construye una vez y se vende a muchos. Esa diferencia, que parece de negocio, te condiciona casi todas las decisiones técnicas: la misma base de código tiene que servir a decenas o miles de organizaciones sin que sus datos se mezclen nunca. Según el análisis publicado en dev.to el 19 de junio de 2026, este único requisito moldea el resto de la arquitectura.
¿Y qué pasa si lo ignorás al principio? Que cada cliente nuevo te cuesta horas de trabajo manual en vez de una incorporación automática de clientes. El SaaS deja de escalar y se convierte en una consultora disfrazada.
¿Base de datos compartida o separada? Cómo elegir según tu etapa
Acá viene la decisión de fondo. Hay tres enfoques, y cada uno tiene su momento.
Base compartida con tenant ID (para early-stage)
Una sola base, y cada tabla lleva una columna tenant_id. Toda query filtra por ese campo. Es lo más barato de operar y, para la mayoría de los SaaS que recién arrancan, es la opción correcta. El costo de sumar el cliente 10 o el cliente 1000 es casi el mismo: una fila más en una tabla de tenants.
Base separada por tenant (para enterprise)
Cada cliente tiene su propia base. El aislamiento es máximo (un cliente no puede ver datos del otro ni por accidente), pero operarlo a escala es caro y complejo: migraciones multiplicadas por la cantidad de clientes, backups por separado, monitoreo por separado. Guardá esto para clientes enterprise que exigen infraestructura dedicada por contrato o por compliance.
Híbrido con schemas de PostgreSQL (punto medio)
Una base, varios schemas, uno por tenant. Te da más aislamiento que la columna compartida sin el costo de administrar mil bases. El punto débil: arriba de cierta cantidad de schemas, las migraciones y el connection pooling empiezan a doler.
| Modelo | Costo de operar | Aislamiento | Escalabilidad | Cuándo usarlo |
|---|---|---|---|---|
| Compartida + tenant ID | Bajo | Lógico (depende del código) | Alta y barata | Early-stage, la mayoría |
| Separada por tenant | Alto | Físico (máximo) | Cara y compleja | Enterprise, compliance |
| Híbrido (schemas) | Medio | Medio-alto | Buena hasta cierto techo | Transición, datos sensibles |
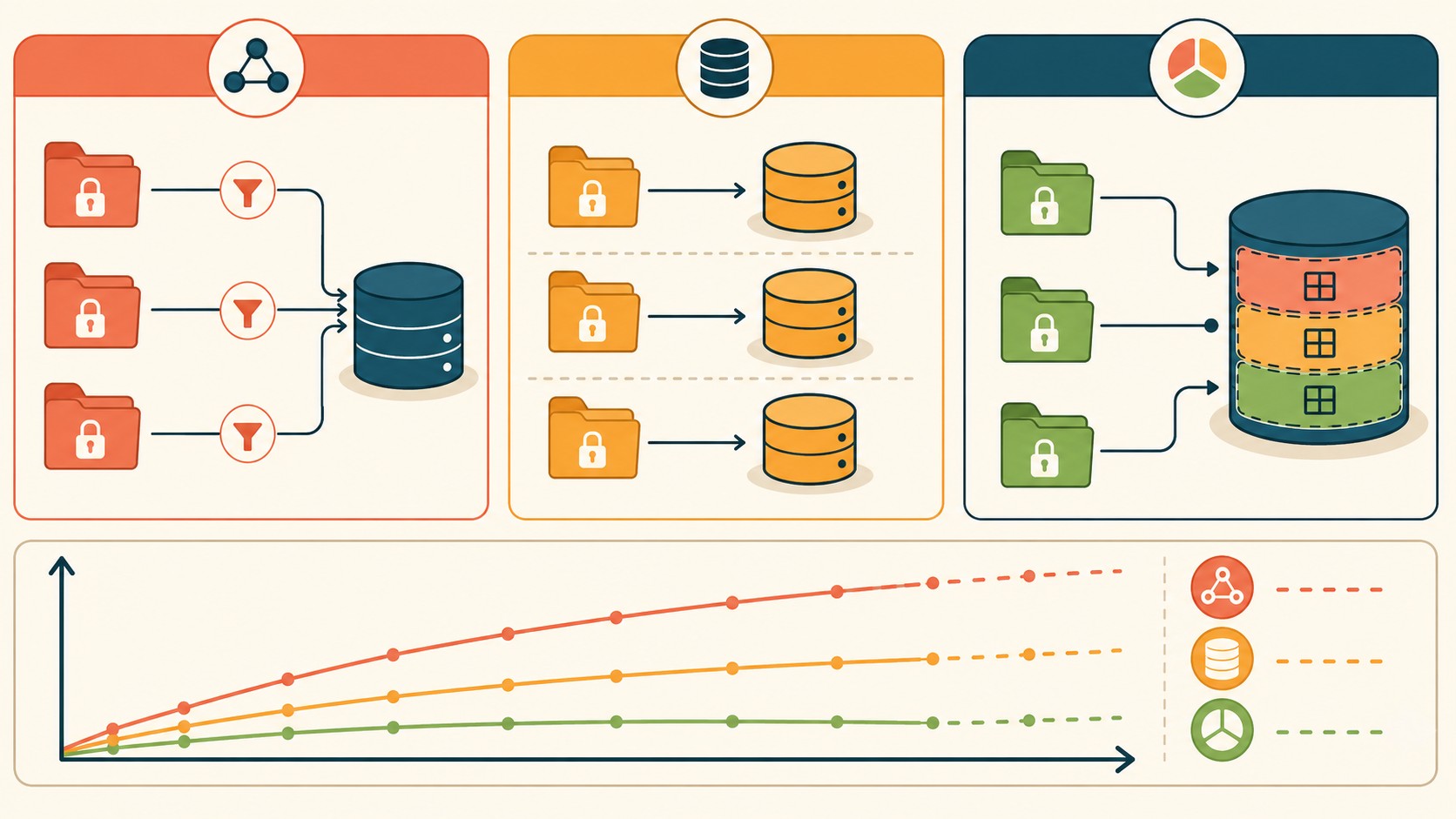
Lo interesante: los fundamentos de arquitectura SaaS de AWS y los principios de diseño de Azure coinciden en que no existe el modelo perfecto. Existe el modelo correcto para tu etapa.
¿Cómo evito un data leak en un sistema multi-tenant?
Ponele que tenés una pantalla de facturas. Escribís la query “traeme todas las facturas” y te olvidás del filtro por tenant. En desarrollo funciona bárbaro porque solo cargaste un cliente. En producción, el cliente A ve las facturas del cliente B.
Eso es un data leak. Y para un SaaS que maneja datos sensibles es un evento que termina con el negocio. El problema es que basta un filtro faltante en una sola consulta. No alcanza con “tener cuidado”. La defensa real es estructural:
- Middleware de tenant context: cada request entrante resuelve a qué tenant pertenece (por subdominio, header o token) y guarda ese ID en el contexto. En Node lo hacés con
AsyncLocalStorage; en Python con el scope del request. - Filtro automático en la capa de datos: que el ORM o el repositorio inyecte el
tenant_idsolo, para que el desarrollador no pueda olvidarlo. Si tenés que acordarte vos, tarde o temprano se escapa. - Tests de aislamiento: escribí tests que creen el tenant A y el tenant B, y verifiquen que una consulta logueada como A nunca devuelve un registro de B. Que el pipeline frene si eso falla.
La regla de oro: hacé que cometer el error sea difícil por diseño, no que dependa de la memoria del que escribe la query a las 11 de la noche.
Billing recurrente: lo que casi nadie planea bien
El cobro recurrente parece un detalle hasta que las tarjetas empiezan a rebotar. En mercados como Nigeria o Latinoamérica, las tarjetas locales rechazan más seguido que las internacionales, así que tu sistema de billing tiene que asumir el fallo como algo normal, no como excepción.
Lo mínimo que necesitás:
- API de suscripciones del proveedor de pago: el reporte original cita Paystack y Flutterwave para cobros en NGN. En Latinoamérica el equivalente lo arma cada quien con su pasarela local para cobros en pesos.
- Retry logic con criterio: reintentos espaciados ante un rechazo, no diez intentos seguidos que solo molestan al banco.
- Comunicación clara en el fallo: avisarle al cliente que el pago falló, con un link directo para actualizar la tarjeta.
- Período de gracia: no suspender la cuenta al primer rebote. Dale unos días antes de cortar el servicio.
¿Qué errores arquitectónicos cometen los founders al arrancar?
El patrón se repite. Founders que diseñan como si ya tuvieran el tráfico de Amazon, sin un solo usuario pago.
- Olvidar el filtro de tenant: el más caro de todos, porque termina en data leak. Se previene con middleware, no con disciplina.
- Overengineering desde el día 1: microservicios, colas distribuidas y Kubernetes para servir a 30 usuarios. Un monolito ordenado te lleva mucho más lejos de lo que creés.
- No medir nada: arrancar sin analytics ni monitoreo. Cuando algo se rompe, no tenés idea de dónde ni por qué.
- Elegir el modelo de DB de la etapa equivocada: montar base separada por tenant (aislamiento enterprise) cuando todavía buscás product-market fit. Pagás complejidad que no necesitás.
¿Cómo escalar sin tener que rehacer todo después?
Hay decisiones que se “cementan” temprano. El modelo de aislamiento de datos es una de ellas: cambiar de base compartida a separada con clientes en producción es una migración fea y riesgosa.
La estrategia sana es simplicidad ahora, con puntos de extensión claros para después. Mantené el tenant_id presente en todo desde el día 1 (aunque uses base compartida), porque eso te deja la puerta abierta para migrar a schemas o a bases separadas más adelante sin reescribir el modelo entero.
Y sobre dónde corre todo: la infraestructura también pesa en el margen. Si necesitás hosting o servidores para tu SaaS en Argentina, donweb.com te resuelve la parte de alojamiento mientras vos te concentrás en la arquitectura de la aplicación. El connection pooling, el cache y el storage se escalan por separado, cada uno cuando el cuello de botella aparece, no antes.
Qué está confirmado y qué no
- Confirmado: el reporte de dev.to del 19 de junio de 2026 plantea dos enfoques de aislamiento y recomienda base compartida con tenant ID para el SaaS early-stage.
- Confirmado: un filtro de tenant faltante en una query equivale a un data leak; la mitigación es middleware que lo haga estructuralmente difícil.
- Pendiente: las cifras de adopción de multi-tenancy en el mercado varían según la fuente y no hay un número único auditado de forma independiente.
- Pendiente: qué pasarela conviene en cada país de Latinoamérica depende de tu base de clientes; el reporte original habla del contexto nigeriano con Paystack y Flutterwave.
Errores comunes al implementar multi-tenancy
- Confiar en el filtro manual: poner el
WHERE tenant_id = ?a mano en cada query. Funciona hasta que alguien se lo olvida. Correcto: que la capa de datos lo inyecte sola. - Probar con un solo tenant: en desarrollo casi nunca ves el leak porque tenés un cliente cargado. Correcto: tests con al menos dos tenants verificando que A no ve a B.
- Empezar con base separada por tenant: elegís el aislamiento más caro antes de validar el producto. Correcto: base compartida con tenant ID, y migrás cuando un cliente enterprise lo pida.
- No guardar el tenant context en el request: pasarlo a mano entre funciones. Correcto:
AsyncLocalStorageen Node o el scope del request en Python.
Preguntas Frecuentes
¿Qué es la arquitectura multi-tenant en SaaS?
Es un modelo en el que una sola instancia de la aplicación atiende a varios clientes a la vez, manteniendo sus datos aislados. Reduce costos porque todos comparten infraestructura y código, mientras cada tenant solo accede a lo suyo.
¿Base de datos compartida o separada conviene para un SaaS?
Para un SaaS early-stage conviene base compartida con un tenant_id en cada tabla: es más barata y suficiente. La base separada por tenant se reserva para clientes enterprise que exigen aislamiento físico o compliance específico.
¿Cómo evito un data leak entre tenants?
Usá un middleware que resuelva el tenant en cada request y un ORM o capa de datos que inyecte el filtro de forma automática. Sumá tests de aislamiento que verifiquen que un tenant nunca ve datos de otro y frená el deploy si fallan.
¿Cuál es el error más común al diseñar un SaaS?
El overengineering temprano: montar microservicios y arquitectura distribuida para un volumen que todavía no existe. Mientras buscás product-market fit, un monolito ordenado con base compartida te lleva más lejos y más rápido.
¿Con qué frameworks implemento multi-tenancy?
En Node funcionan NestJS o LoopBack con AsyncLocalStorage para mantener el tenant context; en Python, Django o FastAPI con el scope del request. Lo importante no es el framework, es que el filtro de tenant se aplique en la capa de datos, no a mano.
Conclusión
La arquitectura multi-tenant no es un detalle que arreglás después: es la decisión de la semana 1 que determina si tu SaaS sobrevive al crecimiento. Si recién arrancás, andá por base compartida con tenant ID, blindá el aislamiento con middleware y tests, y dejá el tenant_id presente en todo el modelo para poder migrar el día que un cliente enterprise lo pida. Lo caro no es elegir simple. Lo caro es elegir complejo antes de tiempo, o descubrir un data leak con clientes reales adentro.