12 patrones de arquitectura AWS que tenés que saber
Cuando entrevistás para un rol de Solutions Architect en AWS, no te preguntan qué servicio hace tal cosa. Te tiran un escenario: “diseñá un e-commerce multi-región con 99,99% de uptime”. Los patrones de arquitectura AWS son las respuestas probadas a esos escenarios, y saberlos de memoria es la diferencia entre zafar y quedar afuera. Acá van los 12 que aparecen sí o sí.
En 30 segundos
- 12 patrones canónicos: desde DR multi-región hasta SaaS multi-tenant, son los que AWS espera que conozcas en una entrevista de arquitecto (fuente: dev.to, publicado el 2/7/2026).
- Multi-AZ vs multi-región: multi-AZ te cubre la caída de un datacenter dentro de una región; multi-región te salva de una caída regional completa, pero sale más caro.
- 99,99% de uptime: se logra con Aurora Global Database (replicación sub-segundo) más Route 53 con health checks, sin humanos en el loop.
- Regla de oro: testeá el failover cada trimestre con AWS Fault Injection Simulator. El que no lo prueba, lo descubre en producción (spoiler: mal momento).
¿Qué es un patrón de arquitectura en AWS?
Un patrón de arquitectura AWS es una solución reutilizable y probada a un problema recurrente de infraestructura en la nube (resiliencia, escalabilidad, redundancia o desacople), armada combinando servicios de AWS de una forma específica. No es un servicio en sí: es la receta que dice qué servicios usar, cómo conectarlos y por qué. Vienen de la experiencia de AWS operando infraestructura a escala masiva.
¿Por qué en las entrevistas serias te tiran escenarios en vez de preguntas de manual? Porque saber que existe Aurora no sirve de nada si no sabés cuándo poner un read-replica en otra región. El escenario mide criterio, no memoria.
Y ojo con esto: los patrones no son dogma. Elegir el patrón equivocado (por ejemplo, diseñar para 99,99% cuando 99,9% alcanzaba) te puede salir carísimo. Vamos uno por uno. Sobre eso hablamos en estrategias de deployment automatizado.
Patrón 1: Recuperación ante desastres multi-región
El escenario clásico: tu app de e-commerce tiene que sobrevivir la caída de una región entera, con un SLA de 99,99% de uptime. Ponele que se cae us-east-1 un martes cualquiera (no sería la primera vez). ¿Qué hacés?
El patrón, según el artículo original de dev.to, arma dos regiones activas:
- Región primaria (us-east-1): VPC activo-activo con peering cross-región, Aurora Global Database como writer primario y CloudFront multi-origin con health checks.
- Región DR (us-west-2): warm standby con failover de DNS vía Route 53, un read-replica de Aurora que promociona a writer cuando hace falta, y replicación cross-región de S3 para los assets estáticos.
¿Por qué funciona? La replicación sub-segundo de Aurora Global Database te da un RPO casi nulo, y los health checks de Route 53 automatizan el failover sin que nadie tenga que apretar un botón a las 3 de la mañana.
El gotcha: tenés que testear el failover cada trimestre. En la entrevista, mencioná Chaos Engineering con AWS Fault Injection Simulator y ganás puntos. Y no confundas esto con multi-AZ, que es intra-región (más sobre eso abajo).
Patrón 2: Microservicios orientados a eventos
Escenario: una plataforma de supply chain donde cada orden dispara un chequeo de inventario, una notificación de envío y una verificación de fraude. Todo tiene que estar desacoplado, porque si el servicio de inventario se pone lento no querés que se caiga el de envíos. Lo explicamos a fondo en herramientas de CI/CD modernas.
El patrón arranca en Amazon API Gateway y de ahí abre a Lambda:
- Order Service (Lambda): recibe la orden desde API Gateway y la reparte.
- Inventory Service (Lambda → DynamoDB): chequea stock de forma independiente.
- Shipping Service (Lambda → SQS → Step Functions): encola el envío y orquesta los pasos.
- Fraud Service (Lambda → DynamoDB): corre la detección en paralelo.
Cada servicio escala solo. Si Inventory se satura, Shipping ni se entera, porque SQS actúa de amortiguador entre ellos. Ese es el corazón del patrón event-driven: desacople real vía colas y máquinas de estado.
Patrones 3 al 7: cinco más que tenés que conocer
La fuente lista doce patrones en total. Estos son cinco de los que siguen, con el caso de uso y el gotcha a tener en cuenta:
- Serverless Batch Processing: procesar millones de transacciones diarias, reconciliarlas con feeds bancarios y generar reportes. DynamoDB Streams → Lambda (enriquecimiento) → S3 en Parquet, orquestado con Step Functions y reportes en QuickSight. El gotcha: Lambda tiene timeout de 15 minutos; para ETL largo, usá AWS Batch o Fargate.
- Hybrid Cloud: mantenés data centers on-prem por compliance pero querés AWS para analytics y ML. Direct Connect hacia la VPC, data lake en S3 con VPC Endpoint, y Athena + Glue + SageMaker. El gotcha: Direct Connect factura por hora de conexión, más los cargos de transferencia de datos; para cargas chicas, una VPN puede salir más barata.
- Real-Time Analytics: procesar clickstream en tiempo real para decisiones de bidding. Kinesis Data Streams → Lambda, Firehose → S3 y Redshift Spectrum + QuickSight para dashboards. El gotcha: los cold starts de Lambda (100-500ms); para latencia sub-100ms, usá Fargate o EC2.
- Multi-Tenant SaaS: una herramienta para empresas donde cada tenant quiere aislamiento de datos y DNS propio. Route 53 por tenant, ALB → WAF → target groups, Fargate → DynamoDB con partition key = tenant_id, y KMS por tenant. El gotcha: para tenants de alto tráfico, usá DynamoDB on-demand.
- CDN + Edge Computing: distribución de contenido a escala global, acercando los datos al usuario final para bajar latencia.
¿Cuál es la diferencia entre multi-región, multi-AZ y single-region?
Esta es la pregunta que separa a los que entienden de los que memorizaron. La clave está en dos métricas: RPO (cuántos datos podés perder) y RTO (cuánto downtime tolerás). Acá la comparación directa:
| Arquitectura | Alcance | RTO típico | Costo relativo | Cuándo usarla |
|---|---|---|---|---|
| Single-region (una AZ) | Una sola zona de disponibilidad | Horas | Mínimo | Dev, pruebas, cargas no críticas |
| Multi-AZ | Varias AZs en una región | Minutos | Medio | Producción con alta disponibilidad estándar |
| Multi-región | Varias regiones independientes | Segundos a minutos | Alto | Compliance regional y tolerancia a caída de región |
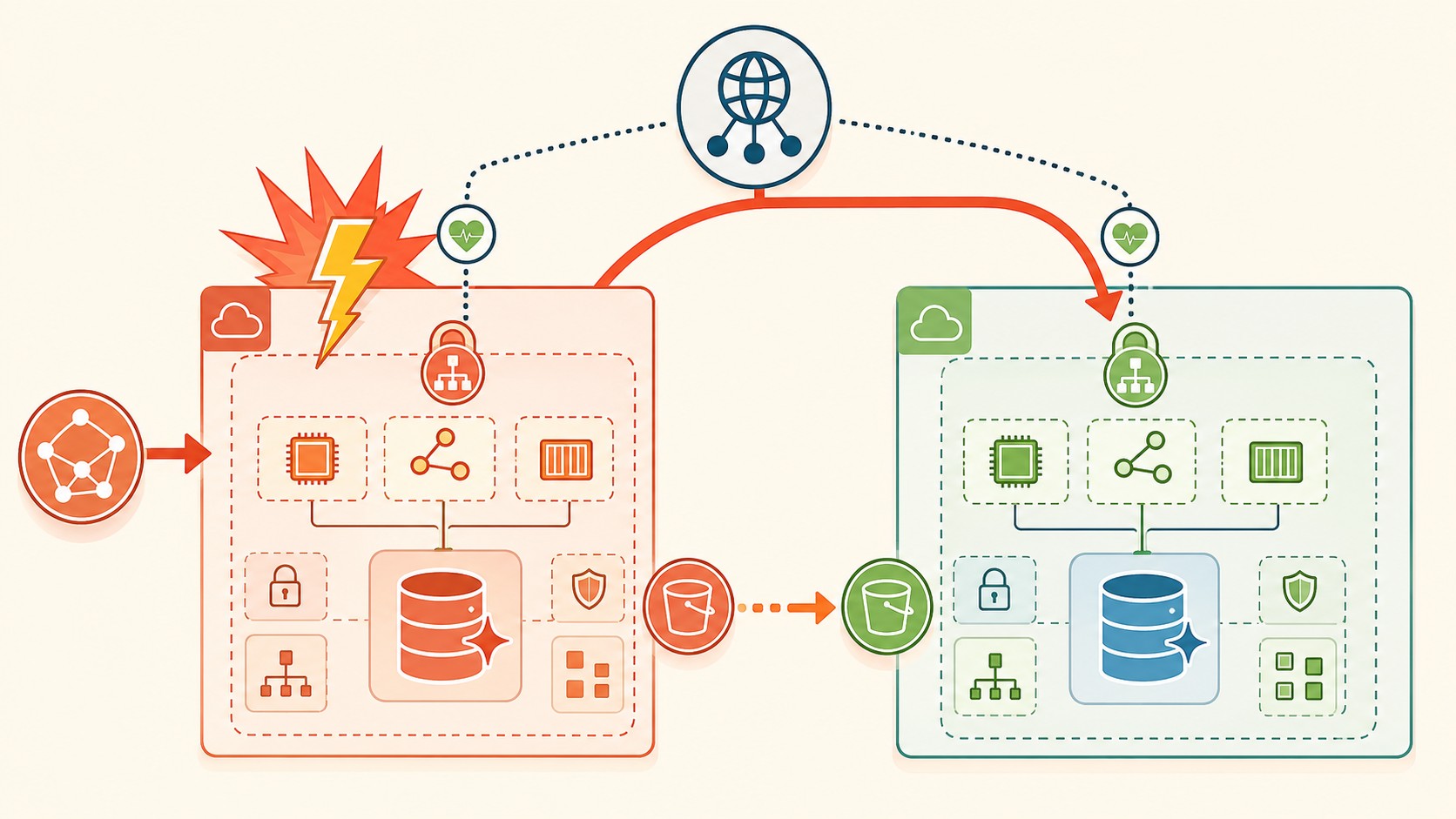
Multi-AZ te cubre la caída de un datacenter dentro de una región, con baja latencia y recovery rápido. Multi-región te cubre que se caiga toda la región, algo raro pero real, y encima te ayuda con requisitos de residencia de datos. Single-region es lo más barato y lo más riesgoso. Complementá con servir contenido en múltiples regiones.
¿Cómo elegir el patrón correcto para tu caso?
Antes de tirar servicios a lo loco, respondé cinco preguntas. Este es el framework de decisión:
- ¿Qué SLA de uptime necesitás? 99% te lo da multi-AZ; 99,9% pide multi-región con failover automático; 99,99% exige activo-activo.
- ¿Cuánto dato podés perder (RPO)? Si la respuesta es “nada”, vas sí o sí a Aurora Global Database con replicación sub-segundo.
- ¿Cuánto downtime aguantás (RTO)? Si son segundos, olvidate del warm standby manual.
- ¿Cuál es el presupuesto? Pasar de 99,9% a 99,99% puede disparar el costo. No siempre vale la pena.
- ¿Hay compliance regional? Si los datos tienen que quedarse en un país, multi-región deja de ser opcional.
La matriz rápida: uptime 99% igual a multi-AZ, 99,9% igual a multi-región con failover, 99,99% igual a activo-activo. Simple, pero define todo el resto del diseño.
Un detalle sobre infraestructura: si estás armando algo más chico o corriendo WordPress y cargas de hosting tradicional en Latinoamérica, no todo tiene que vivir en AWS. Para dominios y hosting AR, donweb.com te resuelve sin que tengas que orquestar cinco servicios cloud para un proyecto que no lo pide.
Errores comunes al implementar patrones de arquitectura AWS
La teoría es linda. Después venís a producción y aparecen los clásicos. Estos son los que más se repiten:
- Sobre-diseñar por las dudas. Montar activo-activo multi-región para una app que con 99,9% andaba bien. El resultado es una factura mucho más alta sin que nadie note la diferencia.
- No testear el failover hasta que pasa uno real. El día que se cae la región descubrís que el read-replica no promocionaba bien. Testealo cada trimestre con Fault Injection Simulator, no cuando ya es tarde.
- Olvidar que la replicación tiene latencia. Aurora Global Database es sub-segundo, pero la replicación cross-región de S3 es eventual. Si asumís consistencia inmediata, te comés bugs raros.
- Usar colas y eventos sin dead-letter queues. ¿Qué pasa con el mensaje que falla tres veces? Si no tenés DLQ, se pierde y nadie se entera. Exacto: descubrís el problema cuando un cliente reclama.
- Ignorar los cold starts de Lambda en el failover. Cuando la región DR se activa de golpe, las funciones frías tardan. En un pico de failover eso se siente.
- No documentar el patrón elegido ni su criticidad. Seis meses después nadie sabe por qué está ese Step Functions ahí, y tocan lo que no había que tocar.
Preguntas Frecuentes
¿Cuáles son los principales patrones de arquitectura en AWS?
Entre los doce que AWS espera en una entrevista de Solutions Architect están: DR multi-región, microservicios event-driven, serverless batch processing, hybrid cloud, real-time analytics, multi-tenant SaaS y CDN + edge computing. Cubren resiliencia, escalabilidad y desacople. Te puede servir nuestra cobertura de ejecutar agentes sin APIs externas.
¿Cuál es la diferencia entre multi-región y multi-AZ?
Multi-AZ distribuye tu app entre varias zonas de disponibilidad dentro de una misma región y se recupera rápido ante la caída de un datacenter. Multi-región usa regiones geográficamente separadas para sobrevivir la caída de una región entera, pero sale más caro.
¿Cómo se logra un 99,99% de uptime en AWS?
Con una arquitectura activo-activo multi-región: Aurora Global Database para replicación sub-segundo (RPO casi cero) y Route 53 con health checks para failover automático de DNS. Sumá S3 cross-region replication para los assets y testeá el failover cada trimestre.
¿Qué patrón conviene para una aplicación event-driven?
El patrón de microservicios orientados a eventos: API Gateway al frente, Lambda por servicio y SQS más Step Functions para desacoplar. Cada servicio escala solo y una falla en uno no arrastra a los demás. Agregá siempre dead-letter queues para los mensajes fallidos.
¿Cómo prepararse para entrevistas de Solutions Architect?
Practicá respondiendo escenarios de diseño, no preguntas teóricas. Aprendé a justificar cada patrón con RPO, RTO, SLA y costo. Mencionar Chaos Engineering con AWS Fault Injection Simulator y saber cuándo NO usar un patrón te distingue del resto.
Conclusión
Estos doce patrones no cambiaron porque salió un servicio nuevo. Cambiaron porque hoy la entrevista de arquitecto mide criterio: saber cuándo un warm standby alcanza y cuándo necesitás activo-activo, y sobre todo cuándo estás gastando de más. Si te llevás una sola idea, que sea esta: el patrón correcto es el más barato que cumple tu SLA, no el más impresionante.
¿Qué hacer ahora? Agarrá tu app actual, calculale el RPO y el RTO reales, y fijate si el patrón que tenés encima coincide con lo que el negocio necesita. Muchas veces vas a descubrir que estás pagando por resiliencia que nadie pidió. Y si vas a una entrevista, prepará dos o tres escenarios contados de punta a punta, con los gotchas incluidos. Eso es lo que buscan.
Fuentes
- AWS Prescriptive Guidance – Cloud Design Patterns (documentación oficial)
- AWS Well-Architected Framework (guía oficial en español)
- Blog de AWS en español – Patrones de resiliencia en la nube
- AWS Architecture Blog – Estrategia de failover multi-región
- dev.to – 12 AWS Architecture Patterns Every Solutions Architect Should Know