Kubernetes: por qué nadie quiere automatizar CPU y memoria
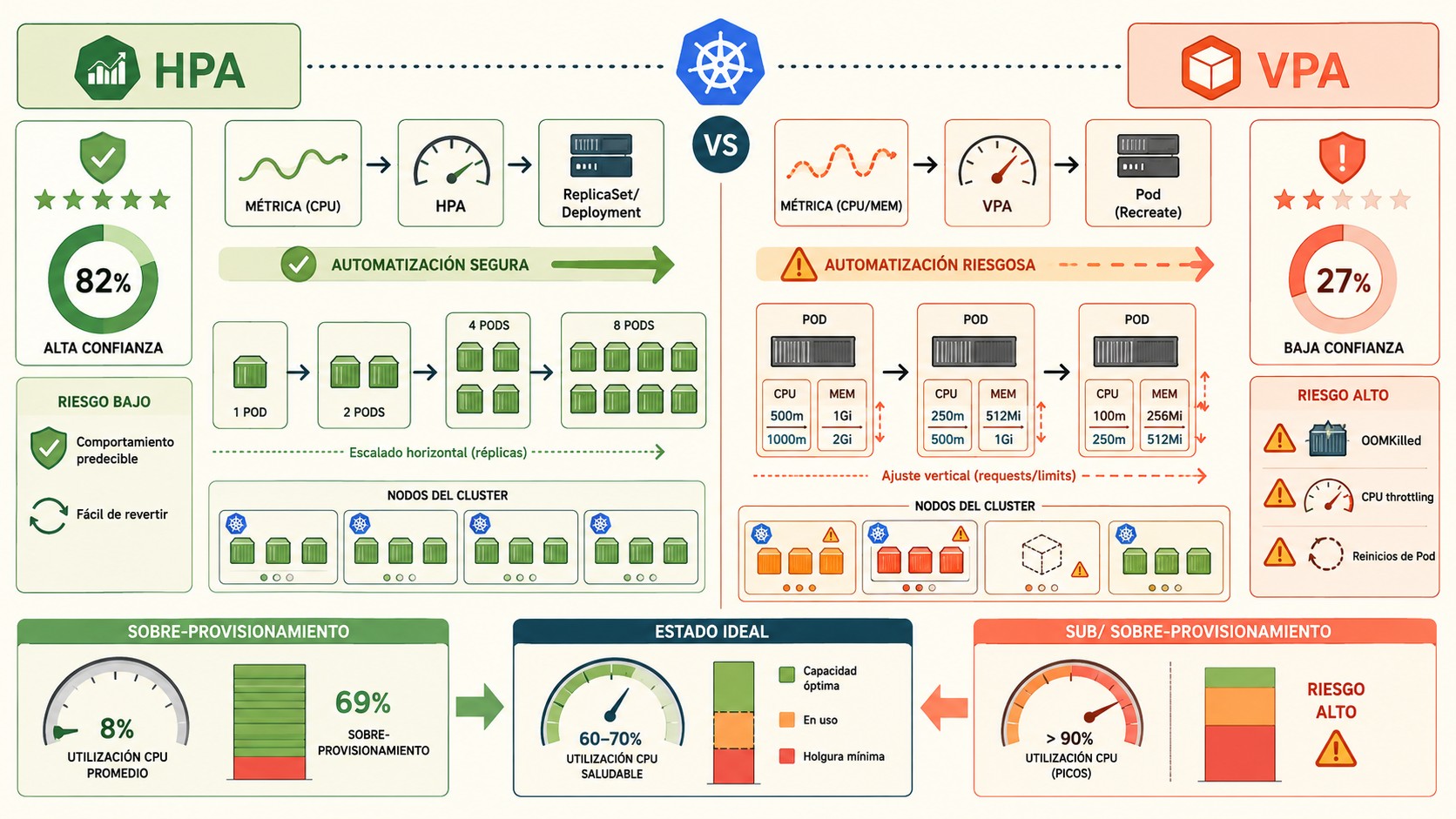
Los equipos de Kubernetes automatizan deploys todo el día sin pestañear, pero cuando se trata de tocar CPU y memoria de un workload corriendo, frenan en seco. Según la encuesta 2026 de CloudBolt sobre 321 practicantes enterprise, el 82% confía en la entrega automatizada, pero solo el 27% deja que un sistema cambie recursos sin un humano revisando. Esa brecha entre la confianza en la automatización de deployments y la automatización de recursos de CPU y memoria se está volviendo cara con la IA encima.
En 30 segundos
- 82% confía en automatizar deploys, pero solo el 27% permite que un sistema cambie CPU o memoria sin revisión humana (CloudBolt, 2026).
- 71% exige aprobación manual antes de aplicar recomendaciones de rightsizing: agregar código se siente aditivo, sacar margen de seguridad se siente sustractivo.
- El desperdicio es real: por miedo a recortar, los equipos sobre-aprovisionan y pagan por capacidad que sus contenedores casi nunca usan.
- La IA acelera la presión: la inferencia de LLMs trae demandas de GPU y VRAM impredecibles que rompen el provisioning estático.
- Qué subiría la confianza: visibilidad del impacto, guardrails y rollback instantáneo.
La automatización de recursos en Kubernetes es el proceso de ajustar automáticamente los requests y limits de CPU y memoria de un pod según su consumo real, en lugar de fijarlos a mano. Lo hacen herramientas como el Vertical Pod Autoscaler (VPA), que recomienda o aplica valores nuevos. La diferencia con el autoscaling horizontal es que acá no se agregan réplicas: se redimensiona el contenedor que ya está corriendo.
¿Por qué el 82% confía en automatizar deploys pero solo el 27% permite cambios de CPU?
La respuesta está en cómo se siente cada acción. Lo resumió bien un practicante citado en el reporte de The New Stack: “Deployar código se siente aditivo. El rightsizing se siente sustractivo, porque estás sacando margen de seguridad de un servicio que está corriendo, y el modo de falla es fundamentalmente distinto”.
Pensalo así. Cuando un pipeline de CI/CD dispara un deploy, agrega algo nuevo. Si sale mal, hacés rollback y listo (eso ya es memoria muscular). Pero cuando un sistema te baja el límite de memoria de 4GB a 2GB porque “viste que nunca pasás de 1.8GB”, está apostando a que el próximo pico no exista. Y los picos existen.
Los números de la encuesta de CloudBolt de enero de 2026 lo dejan claro: 82% reporta confianza alta o total en los controles de entrega automatizada, pero el 71% sigue exigiendo revisión humana antes de aplicar recomendaciones de optimización de recursos. La brecha no es técnica. Es de confianza operativa. Lo explicamos a fondo en flujos de CI/CD en entornos Kubernetes.
Diferencia entre automatizar deployments y automatizar recursos en Kubernetes
Acá viene lo bueno: los modos de falla son opuestos.
- El autoscaling horizontal (HPA) falla ruidoso. Si calcula mal, levanta más pods de los necesarios. Gastás de más, sí, pero lo ves en la factura y en el dashboard. Nadie se queda sin servicio.
- El autoscaling vertical (VPA) falla silencioso. Si baja un límite de memoria por debajo de lo que el pico real necesita, el kernel mata el contenedor con un OOMKilled. Si recorta CPU, llega el throttling y la latencia se dispara sin un error obvio.
Esa asimetría explica todo. Agregar réplicas es reversible y visible. Recortar recursos de un proceso vivo es la clase de cambio que se nota cuando ya rompió algo. Por eso el VPA, según la documentación oficial de Kubernetes, en su modo de aplicación automática necesita reiniciar el pod para aplicar valores nuevos, y eso solo ya genera resistencia en cualquiera que corra cargas con estado.
¿Qué riesgos tiene automatizar requests y limits sin validación?
Ponele que tenés un contenedor con un límite de 2GB de memoria. Venís midiendo un consumo promedio de 1.4GB, así que un sistema “inteligente” decide ajustarlo a 2GB justos para no desperdiciar. Llega un pico de tráfico, el proceso pide 2.5GB y el kernel lo mata. Reinicio. Usuarios afectados. Y todo por optimizar 600MB que en el papel sobraban.
Los riesgos concretos de tocar requests y limits de CPU y memoria sin una validación previa son tres:
- OOMKilled. Bajás el límite de memoria por debajo del pico real y el contenedor muere sin aviso. El log dice “exit code 137” y a buscar.
- CPU throttling. Recortás CPU y el scheduler empieza a frenar el proceso. No se cae, pero la latencia sube y los timeouts aparecen donde antes no había.
- Comportamiento impredecible. Una app puede aguantar un consumo bajo durante días y después, en un batch nocturno o un reprocesamiento, pegar un salto que el promedio nunca vio.
¿Por qué el 71% pide ojos humanos antes de aplicar? Porque el costo de equivocarse no es plata de más, es un incidente. Y un incidente a las 3 de la mañana vale mucho más que el margen que ahorrás.
¿Cómo está acelerando la IA la presión sobre el manejo de recursos en Kubernetes?
El provisioning estático funcionaba más o menos mientras las cargas eran predecibles. La inferencia de LLMs rompió ese supuesto. Tema relacionado: herramientas de automatización de despliegue.
Servir un modelo grande tiene un patrón de consumo que ni el promedio ni el pico histórico capturan bien: la VRAM varía según el largo del prompt y del contexto, la demanda de GPU es errática, y el tráfico puede escalar de cero a miles de requests en segundos cuando una feature se vuelve popular. Quien haya intentado correr inferencia en un cluster sabe de qué hablo. En un análisis técnico sobre qué se rompe primero al correr inferencia en Kubernetes queda claro que el provisioning fijo es lo primero que cruje.
El problema de fondo: si ya sobre-aprovisionás “por las dudas” en cargas normales, con IA ese colchón se multiplica. Y la GPU no es CPU barata. La hesitación de dejar todo en manos de un humano deja de ser prudencia y empieza a ser un costo que no podés sostener. Y a escala, revisar cada recomendación a mano se vuelve inviable. No hay equipo que dé abasto.
¿Qué aumentaría la confianza en automatizar? Visibilidad, guardrails y rollback
La encuesta también preguntó qué haría falta para soltar el control. Las respuestas marcan el camino:
- Visibilidad. Observabilidad real del consumo antes y después del cambio. Si no podés ver el impacto, no vas a confiar. Punto.
- Guardrails. Umbrales y límites duros que la automatización no puede cruzar. Que ajuste, pero dentro de una caja que vos definís.
- Rollback instantáneo. Si el cambio rompe algo, volver atrás en segundos, no en un deploy completo.
Lo interesante es que el debate se corrió. Antes la discusión era de “matemática de costos”: cuánto ahorrás. Ahora es de confianza operativa: bajo qué condiciones dejás que un sistema toque producción. Es un cambio de pregunta, y cambia las herramientas que necesitás.
Herramientas y estrategias para automatizar recursos de Kubernetes con seguridad
La salida no es “automatizar todo” ni “no automatizar nada”. Es subir la confianza por pasos. Primero medís, después recomendás, validás y recién ahí, si el riesgo lo permite, auto-aplicás. Más contexto en ejecutar agentes sin depender de APIs externas.
Para empezar sin riesgo: VPA en modo recomendación
El Vertical Pod Autoscaler tiene un modo “Off” que no aplica nada: solo te dice qué valores sugiere según el histórico. Es el punto de entrada obvio. Mirás las recomendaciones unas semanas, comparás con tu intuición y construís confianza antes de darle permiso para tocar nada.
Para rightsizing sin reinicios: redimensionado in-place
Uno de los frenos del VPA clásico es que, en su modo de aplicación automática, reiniciar el pod para aplicar valores nuevos asusta. Por eso están surgiendo enfoques de right-sizing que buscan ajustar los recursos sin reiniciar el workload, justo el punto que más resistencia genera. Si el reinicio era tu excusa para no automatizar, ese freno empieza a caer.
Para escalado de nodos y eventos: Karpenter y KEDA
Karpenter aprovisiona nodos según lo que los pods necesitan, sin sobre-dimensionar el cluster entero. KEDA escala según eventos (una cola que crece, un tópico de mensajería), no solo según CPU. Para cargas con picos puntuales, escalar por evento le pega más que esperar a que el promedio reaccione.
Eso sí: nada de esto funciona sin el Metrics Server instalado y reportando bien. Es el prerequisito. Sin métricas confiables, automatizar recursos es manejar con los ojos cerrados. Si estás armando la infra cloud donde corre todo esto, conviene apoyarse en un proveedor con soporte real en la región, como donweb.com, antes de pelearte con la latencia de un datacenter del otro lado del mundo.
El desperdicio real: el costo de sobre-aprovisionar por las dudas
Acá está el otro lado de la moneda. Por miedo a recortar, los equipos sobre-aprovisionan. Es el precio que muchos aceptan pagar a cambio de estabilidad: dejar margen de sobra para no quedarse cortos. El problema es que ese colchón se paga en la factura todos los meses. Esto se conecta con lo que analizamos en riesgos de seguridad en la automatización.
Traducido: estás pagando por capacidad que tus contenedores nunca tocan. El costo del “no hacer nada” no es cero. Es la factura mensual inflada que se acepta como normal porque recortar da miedo.
| Aspecto | Automatizar deploys (HPA / CI-CD) | Automatizar recursos (VPA / rightsizing) |
|---|---|---|
| Confianza del equipo | 82% confía | 27% deja auto-aplicar |
| Tipo de acción | Aditiva (agrega código/réplicas) | Sustractiva (saca margen de seguridad) |
| Modo de falla | Ruidoso (más pods, más costo visible) | Silencioso (OOMKilled, throttling) |
| Reversibilidad | Rollback en segundos | Reinicio del pod (salvo herramientas nuevas) |
| Revisión humana | Poco frecuente | 71% la exige |
Errores comunes al automatizar recursos en Kubernetes
- Dimensionar por el promedio en vez del pico. El promedio esconde los saltos. Una carga puede consumir poco días enteros y disparar en un batch nocturno. Configurar el límite según el promedio garantiza un OOMKilled tarde o temprano. Mirá los percentiles altos (p95, p99), no la media.
- Activar VPA en modo auto sin guardrails. Soltar el modo de aplicación automática sin umbrales mínimos es pedir un incidente. Definí pisos de memoria y CPU que el sistema no pueda cruzar, aunque las métricas digan que sobra.
- Automatizar sin observabilidad previa. Si no tenés el Metrics Server y un dashboard que muestre el antes y el después, no vas a saber si el cambio ayudó o rompió. La visibilidad va primero, la automatización después.
- Tratar cargas con estado igual que las sin estado. Una API stateless aguanta un reinicio sin drama. Una base de datos o una cola con estado, no. El nivel de automatización tiene que depender del tipo de workload.
Preguntas Frecuentes
¿Por qué los equipos de Kubernetes no confían en automatizar CPU y memoria?
Porque recortar recursos de un servicio corriendo saca margen de seguridad y falla en silencio. Según CloudBolt 2026, solo el 27% deja que un sistema cambie CPU o memoria sin revisión, contra el 82% que confía en automatizar deploys. La diferencia es que un deploy mal sale se revierte rápido, y un límite mal recortado mata el contenedor con OOMKilled.
¿Cuál es la diferencia entre automatizar deployments y automatizar recursos?
Automatizar deployments agrega código o réplicas y es reversible al instante. Automatizar recursos cambia los requests y limits de un pod vivo, una acción sustractiva con modo de falla silencioso. El HPA falla ruidoso (más pods, costo visible); el VPA falla callado (throttling, contenedor muerto sin error obvio).
¿Cómo usar el Vertical Pod Autoscaler de forma segura?
Arrancá con el VPA en modo “Off” o recomendación, que sugiere valores sin aplicarlos. Mirá las recomendaciones unas semanas, definí guardrails con pisos mínimos de CPU y memoria, y recién después habilitá la aplicación automática en cargas sin estado. Necesitás el Metrics Server funcionando para que las métricas sean confiables.
¿Cuánto se puede ahorrar haciendo rightsizing en Kubernetes?
El margen es grande porque el desperdicio es grande: por miedo a recortar, los equipos sobre-aprovisionan y dejan buena parte de los recursos sin usar. El ahorro depende de tu cluster, pero estás pagando por capacidad que tus contenedores casi nunca tocan.
¿Por qué la IA aumenta la presión sobre el manejo de recursos?
Porque la inferencia de LLMs tiene un consumo impredecible: la VRAM varía según el prompt, la demanda de GPU es errática y el tráfico escala de cero a miles de requests en segundos. El provisioning estático no aguanta ese patrón, y como la GPU es cara, el sobre-aprovisionamiento “por las dudas” se vuelve un costo difícil de sostener.
Conclusión
La foto de 2026 es clara: los equipos de Kubernetes ya confían en automatizar lo que agrega, pero todavía no en automatizar lo que saca. Y mientras esa duda persiste, se sigue sobre-aprovisionando y la factura paga capacidad fantasma. La IA no inventó el problema, pero lo hizo imposible de ignorar.
¿Qué hacer? No soltar todo de golpe ni quedarse paralizado. Empezá con VPA en recomendación, instalá observabilidad real, definí guardrails con pisos duros y dejá la auto-aplicación para las cargas sin estado donde un reinicio no duele. La confianza se construye por pasos, midiendo el antes y el después. El que automatice con red de seguridad va a ahorrar plata real sin comerse el incidente de las 3 de la mañana.
Fuentes
- The New Stack – Kubernetes teams trust automation to ship code but not to touch CPU
- CloudBolt – Investigación sobre la brecha de confianza en automatización de Kubernetes
- CAST.AI – Estado de la optimización de recursos en Kubernetes 2026
- Kubernetes – Documentación oficial del Vertical Pod Autoscaler
- dasRoot – Qué se rompe primero al correr inferencia de LLMs en Kubernetes