Monitorear rendimiento GitHub Actions: CLI local
GitHub Actions te muestra un run a la vez: tilde verde, cruz roja, verde, verde, roja. Lo que no te dice es si tu CI viene mejorando o empeorando. Un desarrollador publicó el 3 de julio de 2026 una CLI sin dependencias que tira el historial de ejecuciones a un archivo local y te arma la tendencia semanal.
Monitorear el rendimiento de GitHub Actions es medir la tasa de éxito, el compute consumido y el desperdicio de tus pipelines de CI/CD a lo largo del tiempo, no run por run. La herramienta que motivó esta nota es una CLI de línea de comandos, sin dependencias externas, que consulta la API REST de GitHub, cachea el historial de ejecuciones en local y calcula la tendencia semanal de éxito y de compute desperdiciado.
En 30 segundos
- Tasa de éxito del 87.4%: el repo de ejemplo (acme/widgets) tiene 812 runs y 699 de 800 terminaron bien.
- 14h 6m de compute tirado: 101 runs desperdiciados (12.6%) sobre 118h 42m totales.
- Un pozo que la UI esconde: la tendencia cayó de 91.2% (5-jun) a 79.4% (19-jun), algo que GitHub Actions no te grafica.
- Zero-dep y local: la CLI corre en tu máquina y no necesita una plataforma de observabilidad paga.
¿Por qué GitHub Actions no te avisa que tu CI está empeorando?
Porque la interfaz está pensada para el run de hoy, no para la serie de las últimas ocho semanas. Vos entrás, ves la cruz roja, apretás “re-run”, pasa a verde y seguís laburando. El problema queda enterrado.
Ponele que hace un mes tus builds tardaban dos minutos y ahora tardan cinco. ¿Cuándo te diste cuenta? Casi nunca por un número: te diste cuenta porque “se puso molesto trabajar acá”. Esa es una señal lenta y poco precisa. El propio autor lo plantea así en su nota del 3 de julio de 2026: nadie está haciendo la pregunta que importa, ¿esto va mejor o peor?
¿Qué es la tasa de éxito y por qué importa en CI/CD?
La tasa de éxito (success rate) es el porcentaje de ejecuciones que terminan bien sobre el total de las que terminaron. En el ejemplo del artículo son 699 sobre 800 runs cerrados, un 87.4%. Los 12 runs “skipped” no cuentan y hay 2 en progreso. En comparativa de plataformas CI/CD profundizamos sobre esto.
El número por sí solo dice poco. Lo que importa es hacia dónde se mueve. Un 87% estable es una cosa; un 87% que el 5 de junio era 91.2% y en el medio tocó 79% es otra muy distinta, porque te está avisando que algo se rompió y todavía no lo arreglaste del todo. Los puntos que bajan son desarrolladores apretando “re-run” a mano, ramas que no mergean, y tiempo de máquina que pagás igual.
¿Cómo calcular el costo real de los pipelines fallidos?
Acá aparece la distinción clave del artículo: “wasted runs” no es lo mismo que “wasted compute”. Un run desperdiciado es una ejecución que no sirvió (falló o hubo que repetirla). El compute desperdiciado es el número de minutos de máquina que esa ejecución quemó igual.
En el ejemplo, sobre 118h 42m de compute total, 14h 6m se fueron a la basura. Eso es un 12% del gasto de máquina que no produjo nada. Los runners hospedados de GitHub se facturan por minuto, así que 14 horas de humo son 846 minutos que aparecen en la factura sin haber movido la aguja. Según la documentación de la API de Actions, cada run trae su duración, y de ahí sale el cálculo: minutos desperdiciados por el precio por minuto de tu tipo de runner.
Si tus deploys o tests corren en un VPS o en la nube (por ejemplo en donweb.com), ese compute desperdiciado también se paga en tu factura de infraestructura, no solo en la de GitHub. La cuenta escala rápido cuando hablás de un equipo con decenas de commits por día.
¿Cómo detectar la degradación con la tendencia semanal?
La columna semanal es el corazón de la herramienta. Agrupa los runs por semana y te muestra cómo evolucionó el éxito y el desperdicio. Mirá los datos del propio reporte:
| Semana | Tasa de éxito | Runs desperdiciados | Compute tirado |
|---|---|---|---|
| 2026-06-05 | 91.2% | 8 | 58m |
| 2026-06-12 | 88.0% | 11 | 1h 22m |
| 2026-06-19 | 79.4% | 22 | 3h 8m |
| 2026-06-26 | 84.1% | 15 | 2h 1m |
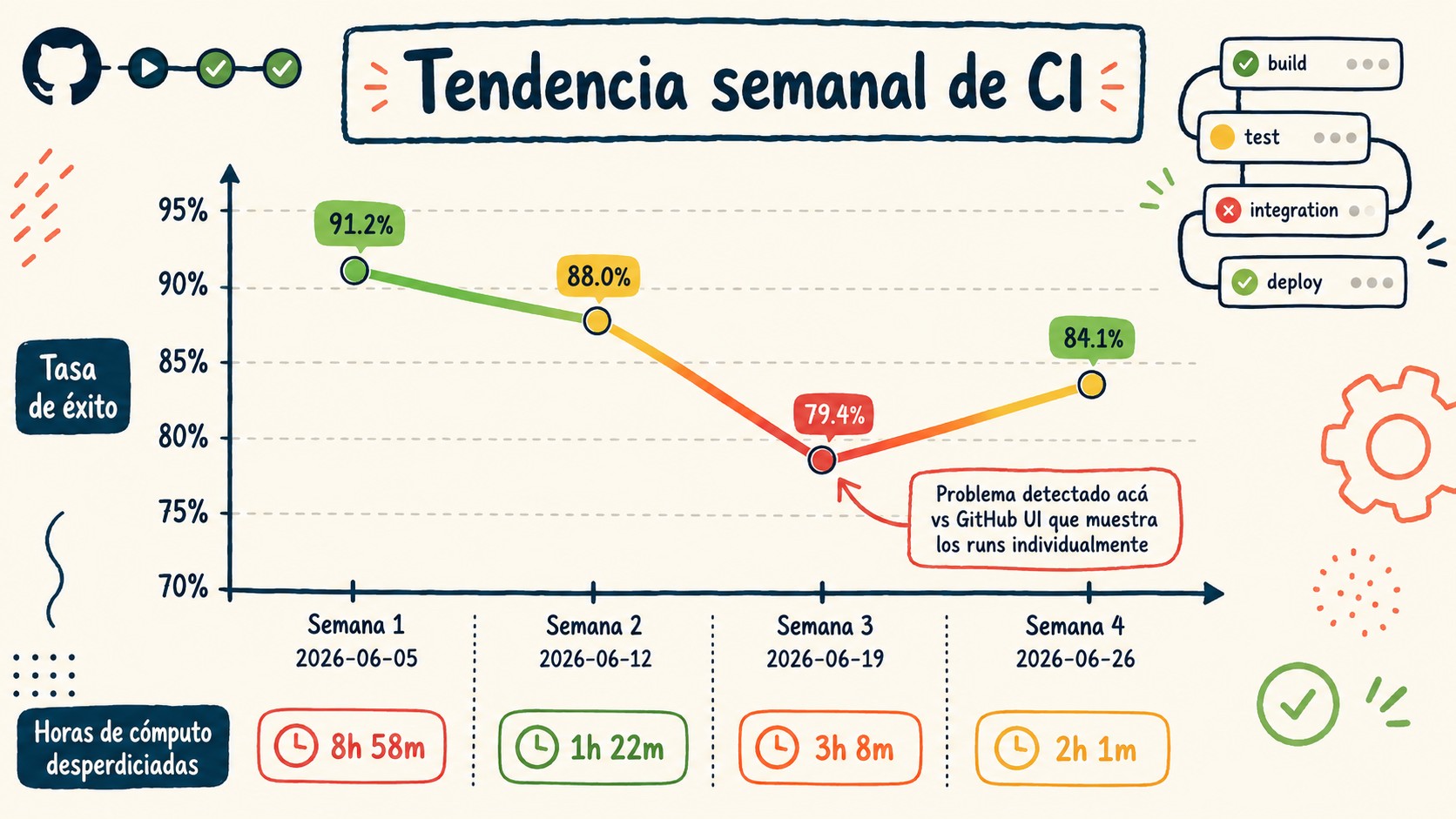
¿Ves lo que pasó en la semana del 19 de junio? El éxito se cayó a 79.4% y el compute tirado casi se triplicó respecto de la semana anterior. Ese es el pozo. Con la vista de un run a la vez es invisible: tendrías que acordarte, run por run, de que “esta semana falló más”. Con el número al lado, lo ves en dos segundos. Mirá el debate GitHub Actions vs Jenkins para profundizar.
La semana siguiente rebota a 84.1%, señal de que alguien lo empezó a corregir. Eso es lo que te da la serie: no solo el problema, también si el arreglo funcionó.
¿Cómo monitorear el rendimiento de GitHub Actions localmente sin dependencias?
La respuesta corta: con una CLI zero-dep. La herramienta del artículo tira tu historial de workflow runs desde la API REST de GitHub, lo cachea en un archivo local y genera el reporte que venís viendo. Nada de agentes, ni dashboards remotos, ni una suscripción mensual.
El output completo se ve así, con el total de runs, los que están en progreso, la tasa de éxito, el desperdicio y la tabla semanal:
- 812 runs en el repo, 2 todavía en progreso.
- 87.4% de éxito sobre 800 runs cerrados (699 buenos, 12 skipped).
- 101 runs desperdiciados (12.6%), 14h 6m de compute quemado.
- Tendencia semanal del más viejo al más nuevo, para ver el patrón de un vistazo.
El caso de uso es claro: equipos chicos que no tienen presupuesto (ni ganas) de montar una plataforma de observabilidad pesada solo para saber si su CI se está pudriendo. Para eso alcanza con un archivo local y un comando. Te puede servir nuestra cobertura de pipelines CI/CD internacionales.
¿Cómo obtiene los datos desde la API de GitHub?
Consultando el endpoint de workflow runs con un token de autenticación. La API de GitHub Actions devuelve cada ejecución con su estado, conclusión y tiempos, y de ahí se arma todo el cálculo.
El caché local no es un detalle menor. La API de GitHub tiene rate limits, así que repetir la llamada completa cada vez es caro y lento. Guardando el historial en un archivo, la CLI solo pide lo nuevo y recalcula sobre lo que ya tiene. Eso mismo lo podés reutilizar para un dashboard propio, para meter los datos en tu base o para engancharlo con otra herramienta.
Errores comunes al monitorear GitHub Actions
- Mirar solo el último run: el estado de hoy no te dice si venís en caída. Sin la serie semanal, un deterioro del 91% al 79% te pasa por al lado. Corrección: agrupá siempre por período, no por ejecución.
- Confundir runs con compute: diez runs que fallan en 20 segundos cuestan menos que dos que fallan a los 15 minutos. Corrección: medí minutos desperdiciados, no solo cantidad de fallos.
- Re-runear a ciegas los flaky: apretar “re-run” hasta que quede verde esconde el problema real y quema compute. Corrección: si un test es inestable, arreglalo o aislalo, no lo repitas.
- No contar los “skipped” aparte: meter los runs saltados en la tasa de éxito te ensucia el número. Corrección: calculá el porcentaje sobre los runs que efectivamente terminaron, como hace la herramienta (699/800).
Preguntas Frecuentes
¿Cómo monitorear el rendimiento de GitHub Actions en el tiempo?
Necesitás una herramienta que agrupe tus workflow runs por período y calcule la tasa de éxito y el compute por semana. La CLI del artículo tira el historial desde la API REST de GitHub, lo cachea local y muestra la tendencia semanal, algo que la interfaz nativa no ofrece.
¿Por qué mi pipeline CI/CD está más lento que antes?
Casi siempre por degradación acumulada: tests que se volvieron inestables, dependencias más pesadas o pasos que se agregaron sin medir su costo. La forma de confirmarlo es ver la serie: si tu tasa de éxito cayó de 91% a 79% en dos semanas, ahí tenés el punto donde algo se rompió.
¿Qué herramientas puedo usar para detectar degradación en GitHub Actions?
Las plataformas de CI pesadas traen sus propios dashboards de tendencias, pero para un equipo chico alcanza con una CLI zero-dep como la que se publicó el 3 de julio de 2026, que corre local y no tiene costo de suscripción. También podés armar tu propio análisis consumiendo la API de workflow runs. Para más detalles técnicos, mirá herramientas CLI sin dependencias externas.
¿Cómo calcular el costo real de fallos en CI?
Multiplicá los minutos de compute desperdiciado por el precio por minuto de tu tipo de runner. En el ejemplo del artículo, 14h 6m tiradas (846 minutos) sobre 118h 42m totales representan un 12% del gasto de máquina que no produjo nada útil.
¿Cuánto tiempo pierdo en compilaciones fallidas?
Depende de tu tasa de desperdicio. En el repo de ejemplo fueron 101 runs desperdiciados de 800 (12.6%), equivalentes a 14h 6m de compute. Ese número por semana es lo que te permite ver si el desperdicio crece o se controla.
Conclusión
Lo que cambió no es la tecnología, es la pregunta. GitHub Actions responde “¿este run pasó?” y esa es la pregunta fácil. La que importa (¿mi CI mejora o empeora?) no tenía una respuesta liviana hasta que alguien se puso a medir el desperdicio a mano y terminó escribiendo una CLI sin dependencias.
Si manejás pipelines, la acción concreta es simple: dejá de mirar el último run y empezá a mirar la serie. Agrupá por semana, separá runs de compute, y ponele un número al desperdicio. Un deterioro del 91% al 79% cuesta plata todos los días que no lo ves. Con la tendencia semanal a la vista, lo agarrás cuando todavía es un problema chico.