IA SRE Self-Hosted 2026: guía completa
La IA SRE Self-Hosted 2026 ya no es un experimento de nicho: es la arquitectura que eligen organizaciones con datos sensibles, regulaciones duras o simplemente hartas de que el vendor tenga más control sobre su infraestructura de lo que les gustaría admitir. El agente corre en tu perímetro, la inferencia también, y ningún paquete de telemetría sale hacia servidores de terceros.
En 30 segundos
- Solo 3 de las 15 herramientas AI SRE más citadas en 2026 alcanzan T4 (on-prem) o T5 (air-gapped); las otras 12 se quedan en T1 o T2, según el Sovereignty Spectrum propuesto en el análisis de referencia.
- Un stack self-hosted real requiere tres componentes independientes sin llamadas salientes: orquestación (LangGraph, ReAct), memoria (Memgraph, Weaviate) e inferencia (LLaMA 3.3, Mistral, Qwen).
- LLaMA 3.3 70B ofrece performance comparable a LLaMA 3.1 405B con costos de inferencia menores, según el propio anuncio de Meta de diciembre de 2024.
- El EU Data Boundary de Microsoft Cloud se completó el 26 de febrero de 2025, y el EU AI Act sigue su cronograma de implementación por fases hasta 2027.
- Un servidor con RTX 4060 (aprox. USD 1.200 up-front) amortiza su costo versus APIs cloud en 6 a 12 meses dependiendo del volumen de inferencias.
Llama 3 es un modelo de lenguaje grande de código abierto desarrollado por Meta, disponible en versiones de 8B y 70B de parámetros. Diseñado para generación de texto, razonamiento y seguimiento de instrucciones, fue lanzado en abril de 2024.
Soberanía de datos en IA: por qué el self-hosting importa en 2026
Un agente AI SRE self-hosted es un sistema donde el runtime del agente, su capa de memoria y el LLM que usa corren dentro del perímetro del cliente. Cada llamada de inferencia, cada lectura de telemetría y cada escritura de postmortem ocurre en infraestructura propia. Si el vendor manda datos a sus servidores para hacer inferencia, no es self-hosted bajo esta definición, sin importar cuánto diga el brochure que es “privado”.
El contexto regulatorio empujó esto. El EU Data Boundary para la nube de Microsoft se completó el 26 de febrero de 2025. El EU AI Act avanza por fases hasta 2027. La SEC adoptó reglas de disclosure de ciberseguridad el 26 de julio de 2023, con el Form 8-K Item 1.05 efectivo desde el 18 de diciembre de 2023. Para organizaciones en sectores financieros, de salud o defensa, estas fechas no son trivia: son deadlines con consecuencias legales.
Para equipos en Argentina y Latinoamérica, el driver no siempre es regulatorio. A veces es más simple: no querés que los logs de producción de tu cliente bancario pasen por servidores en Irlanda. O tenés datos cubiertos por contratos que prohíben procesamiento en terceros. O simplemente preferís pagar una vez y no cada vez que el modelo procesa un millón de tokens.
El Sovereignty Spectrum: los 5 tiers de deployment
El framework más claro para entender dónde cae tu stack es el Sovereignty Spectrum, con cinco tiers:
| Tier | Nombre | Qué significa | ¿Datos salen? |
|---|---|---|---|
| T1 | Public SaaS | Todo en servidores del vendor | Sí, siempre |
| T2 | Private SaaS | Tenant aislado, pero infraestructura del vendor | Sí, al vendor |
| T3 | VPC-Isolated | Corre en tu VPC (AWS, Azure, GCP), vendor gestiona el plano de control | Parcialmente |
| T4 | On-Prem Hosted | Hardware propio, red propia, sin control externo | No (si configurado bien) |
| T5 | Air-Gapped | Sin conectividad externa, completamente aislado | Imposible por diseño |
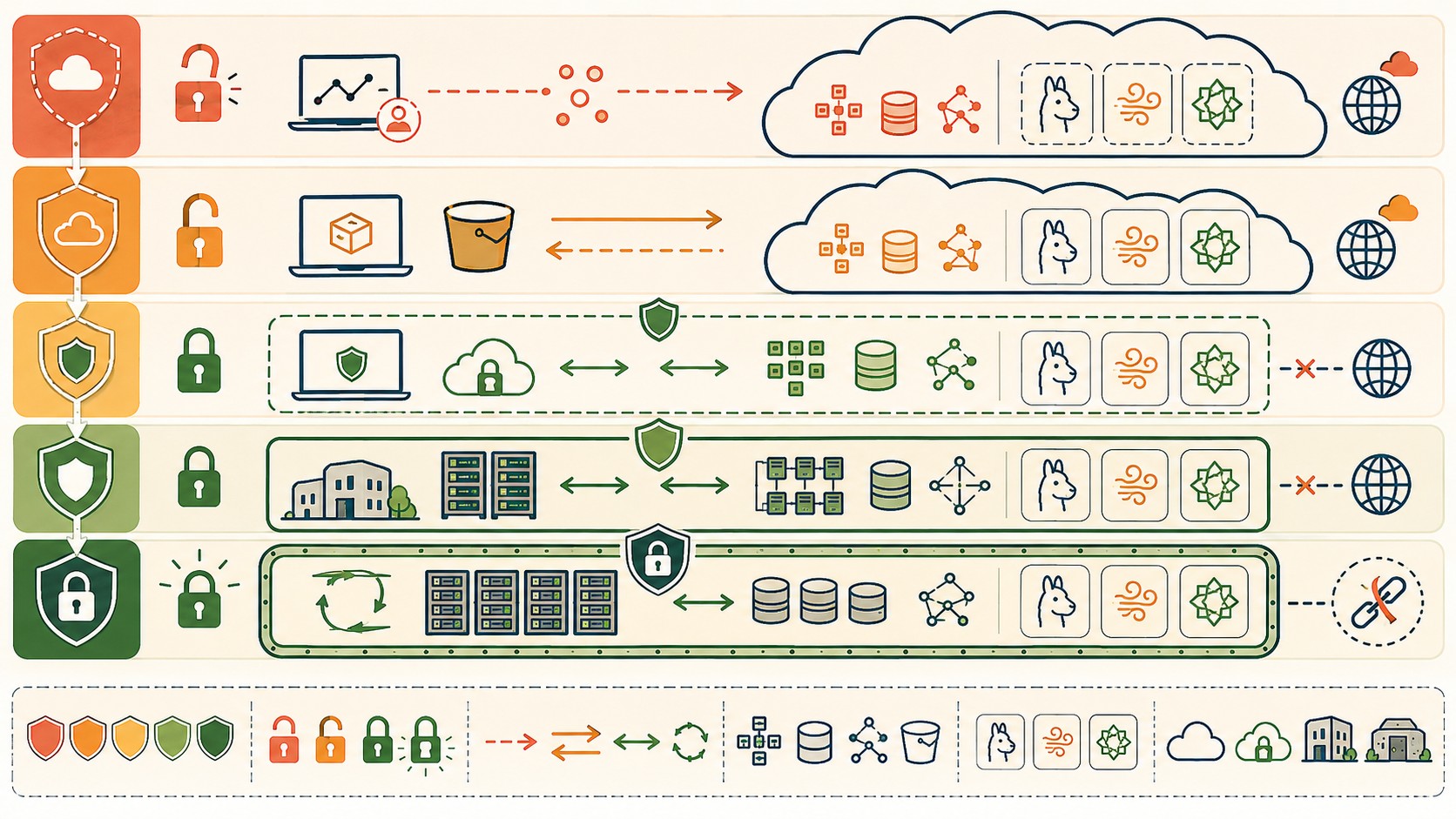
El dato que importa: de las 15 herramientas AI SRE más citadas en 2026, solo 3 alcanzan T4 o T5 de forma creíble. Las otras 12 toman at most T1 o T2. Esto significa que la mayoría de los vendors que te venden “IA para operaciones” en realidad te están vendiendo un SaaS con un SDK. No es lo mismo. Más contexto en herramientas de CI/CD para tu infraestructura.
¿Y cuál elegir? Depende de tu modelo de riesgo. T3 alcanza para muchas PyMEs con contratos estándar. T4 es el mínimo para fintech o salud con datos sensibles. T5 es para defensa, inteligencia o cualquier sector donde el concepto de “llamada saliente” directamente no existe en el diseño de red.
Los 3 stacks independientes del AI SRE self-hosted
Un deployment air-gapped real requiere tres stacks que funcionen sin ninguna llamada de red saliente. No dos. Los tres.
Orquestación: el loop del agente
Acá vive la lógica de decisión: el agente planifica qué acciones tomar, las ejecuta y revisa los resultados. Las opciones más usadas en 2026 son LangGraph (buena para flujos con estado complejo) y ReAct (más simple, más predecible en producción). OpenSRE es un framework open-source específico para agentes SRE que merece atención si querés algo ya pensado para incidentes.
Memoria: el grafo de dependencias y el corpus RAG
El estado del agente no puede vivir en memoria volátil si querés que sobreviva reinicios o que múltiples instancias compartan contexto. Memgraph y Weaviate son las opciones más mencionadas para 2026. Memgraph maneja bien grafos de dependencias entre servicios; Weaviate sirve para RAG sobre runbooks, postmortems y documentación interna. Los dos corren on-prem sin drama.
Inferencia: el LLM que corre local
Este es el componente que más genera dudas. La pregunta de si un modelo open-weight puede hacer el trabajo de un GPT-4 en tareas de SRE tiene una respuesta más afirmativa en 2026 de lo que tenía hace 18 meses.
LLaMA 3.3, Mistral y Qwen: modelos open-weight para inferencia local
Ponele que tenés que decidir qué modelo meter en tu stack de inferencia local. El candidato más sólido ahora mismo es LLaMA 3.3 70B, que Meta anunció en diciembre de 2024. Según el propio anuncio de Meta, el 3.3 70B entrega performance comparable al 3.1 405B con costos de inferencia menores. Eso es relevante: el 405B requería hardware que estaba fuera del alcance de la mayoría.
Las alternativas:
- Mistral: buena performance en razonamiento, contexto largo, bien documentado para deployment local.
- DeepSeek: competitivo en benchmarks de código, relevante si el agente SRE va a generar o ejecutar scripts.
- Qwen: el mejor soporte multilingüe de los tres, lo que importa si tenés documentación y runbooks en español.
Para el stack de inferencia local, las herramientas más usadas son Ollama (fácil de montar, ideal para empezar), vLLM (pensado para producción con batching y throughput alto) y llama.cpp (máximo control, corre en CPU si necesitás, aunque más lento).
El tema del hardware: una RTX 4060 cuesta aproximadamente USD 1.200. Con ese setup corrés LLaMA 3.3 70B cuantizado sin problema. Si lo comparás contra pagar OpenAI GPT-4o, que dependiendo del volumen puede salir entre USD 50 y USD 150 por mes para 10 millones de tokens, el break-even está en 6 a 12 meses. (Y después de eso, $0/mes por inferencia. Que no es un detalle menor.) Complementá con entrenar tu propio modelo de lenguaje.
La arquitectura completa: de la alerta al postmortem sin salir del perímetro
El flujo en un stack self-hosted real va así: una alerta llega al agente vía orquestador. El agente consulta la capa de memoria para recuperar contexto relevante (runbooks, incidentes similares, topología de servicios). Con ese contexto, hace inferencia local para decidir el siguiente paso. Ejecuta la acción (reiniciar un pod, escalar un servicio, generar un ticket). Escribe el resultado de vuelta a la memoria persistente. Todo sin salir de la red.
Lo que no puede pasar es que el estado del agente viva en memoria del proceso. Si el agente se reinicia durante un incidente, tenés que poder retomar desde donde estaba. Por eso la memoria persistente y compartida es el componente más crítico del stack, no el más glamoroso.
Subís el modelo, lo probás en local, funciona bien con los runbooks de staging, lo mandás a producción y de repente las consultas del agente devuelven contexto viejo porque el corpus RAG no se actualizó con los cambios de la semana pasada, los nombres de los servicios cambiaron con el último refactor y nadie actualizó la documentación. El stack técnico estaba perfecto; la operación falló igual.
Herramientas que realmente alcanzan T4 o T5
El problema con el mercado de AI SRE en 2026 es que casi todos los vendors hablan de privacidad y soberanía, pero al leer la arquitectura resulta que la inferencia igual pasa por sus servidores. De las 15 herramientas más citadas, según el análisis de referencia, solo 3 alcanzan T4 o T5 de forma creíble.
OpenSRE es el caso más interesante: framework open-source disponible en GitHub, diseñado específicamente para agentes SRE, sin vendor lock-in por definición. Si necesitás algo auditable y modificable, es el punto de partida más honesto.
¿Alguien verificó de forma independiente cuáles son las otras dos herramientas que llegan a T4/T5? Esa información todavía no está completamente documentada en fuentes abiertas, lo que en sí mismo dice algo sobre el estado de madurez del ecosistema.
El cálculo de costos en 2026: hardware vs API
El cambio de mentalidad que requiere el self-hosting es pasar de gasto operativo a inversión de capital. Muchos equipos traban ahí. Para más detalles técnicos, mirá ejecutar agentes IA sin dependencias externas.
Los números concretos para un setup de uso moderado:
- OpenAI GPT-4o: entre USD 50 y USD 150/mes para 10 millones de tokens (dependiendo del mix de input/output).
- Servidor con RTX 4060: aprox. USD 1.200 up-front, cero costo de inferencia después.
- Break-even: entre 8 y 24 meses dependiendo del volumen.
- Para volúmenes altos (50M+ tokens/mes): el self-hosting ahorra desde el primer mes.
La soberanía de datos es el bonus, no el argumento principal. El argumento principal es que a escala, las APIs cloud son caras. Si además necesitás cumplir con regulaciones europeas, el self-hosting deja de ser una opción y pasa a ser el único camino.
Para equipos que quieren explorar hosting de infraestructura local o VPS para este tipo de setups en Argentina, donweb.com tiene opciones de servidores dedicados y VPS que pueden servir como base para el stack de orquestación y memoria.
Casos donde el self-hosting es obligatorio, no opcional
Fintech, healthcare y defensa son los casos más obvios. Pero el EU AI Act está empujando esto a sectores que antes no lo consideraban. El cronograma de implementación por fases llega hasta 2027, y cada fase agrega requisitos nuevos sobre trazabilidad, auditabilidad y control de los sistemas de IA.
El dato de contexto: McKinsey reportó que el 44% de los gobiernos que evalúan IA agéntica en 2026 exigen garantías explícitas de soberanía de datos como condición para el deployment. No como preferencia. Como requisito.
Para ese segmento, T3 (VPC-Isolated) no alcanza porque el plano de control sigue siendo del vendor. T4 o T5 es el mínimo, y eso descarta a 12 de las 15 herramientas AI SRE más populares del mercado.
Errores comunes al montar un stack self-hosted
Confundir VPC con air-gapped
Un deployment en tu VPC de AWS con el modelo corriendo en una instancia que vos controlás sigue siendo T3, no T4. El plano de control de AWS, incluyendo IAM, CloudTrail y los endpoints de gestión, sigue siendo externo. Si tu modelo de amenaza incluye a AWS como vector, T3 no te cubre.
Usar el modelo más grande disponible
LLaMA 3.3 70B cuantizado a 4-bit corre en una RTX 4060 y tiene performance suficiente para la mayoría de los casos de SRE. El 405B requiere múltiples GPUs de alta gama y latencias de inferencia que lo hacen impráctico para respuestas en tiempo real. El modelo más grande no siempre es el correcto para el caso de uso. En soluciones privadas para control de versiones profundizamos sobre esto.
Ignorar la capa de memoria hasta que todo falla
El stack de inferencia es el que tiene el marketing, pero la capa de memoria es lo que hace que el agente sea útil en producción. Si los runbooks no están en el corpus RAG o si el grafo de dependencias de servicios está desactualizado, el modelo va a tomar decisiones con contexto viejo. La arquitectura de memoria es el componente más crítico y el que más frecuentemente se subestima en los primeros deployments.
Si querés ver cómo montar todo esto, tenemos detalles en Self-Hosted AI SRE in 2026: Air-Gapped, Multi-Cloud, BYO-LLM.
Che, esto engancha con Self-Hosted AI SRE in 2026: Air-Gapped, Multi-Cloud, BYO-LLM, donde lo explicamos a fondo.
Si te interesa hacer esto vos mismo, mirá nuestro artículo sobre Infraestructura IA self-hosted.
Para conocer más sobre cómo armar tu propio stack, mirá nuestro análisis de arquitectura IA self-hosted.
Lo que está confirmado / Lo que todavía no está claro
Confirmado
- El EU Data Boundary de Microsoft Cloud se completó el 26 de febrero de 2025 (anuncio oficial de Microsoft).
- LLaMA 3.3 70B tiene performance comparable a LLaMA 3.1 405B con menor costo de inferencia, según el anuncio de Meta de diciembre de 2024.
- Solo 3 de 15 herramientas AI SRE citadas en 2026 alcanzan T4/T5, según el análisis publicado en dev.to.
- El EU AI Act continúa su implementación por fases hasta 2027.
Todavía no está claro
- Cuáles son exactamente las 3 herramientas que alcanzan T4/T5 (la fuente primaria menciona el número pero no los nombra todos explícitamente).
- Si LLaMA 3.3 70B cuantizado mantiene la performance en benchmarks específicos de SRE (análisis de logs, generación de queries de diagnóstico, síntesis de postmortems).
- El impacto real del EU AI Act en empresas latinas que operan en mercados europeos: los abogados todavía están interpretando el alcance extraterritorial.
Preguntas Frecuentes
¿Qué significa que un agente de IA sea self-hosted y air-gapped?
Self-hosted significa que el agente, su memoria y el LLM que usa corren en infraestructura que vos controlás, sin que ningún dato salga hacia servidores del vendor. Air-gapped va un paso más: la red está físicamente aislada, sin conectividad externa posible. Un agente que usa la API de OpenAI desde tu VPC no es self-hosted bajo esta definición, aunque corra en tus servidores.
¿Cuál es la diferencia entre T4 on-prem y T5 air-gapped en el Sovereignty Spectrum?
T4 (on-prem hosted) significa que el hardware es tuyo, la red es tuya, y no hay control externo, pero técnicamente podría haber conectividad a internet. T5 (air-gapped) elimina esa conectividad por diseño: el sistema no puede hacer llamadas salientes aunque quisiera. T5 es el único nivel que cumple con los requisitos de sectores como defensa o inteligencia, donde cualquier posibilidad de filtración de datos es inaceptable.
¿Qué herramientas de IA SRE permiten BYO-LLM realmente self-hosted?
De las 15 herramientas más citadas en 2026, solo 3 alcanzan T4 o T5. OpenSRE es el caso más documentado: framework open-source disponible en GitHub, sin vendor lock-in. Para el stack de inferencia, Ollama, vLLM y llama.cpp permiten correr LLaMA 3.3, Mistral o Qwen completamente local. La combinación OpenSRE + Weaviate/Memgraph + vLLM con LLaMA 3.3 70B es el stack self-hosted más completo y auditable disponible en este momento.
¿Cuánto cuesta montar un stack de IA local vs usar SaaS?
Un servidor con RTX 4060 cuesta alrededor de USD 1.200 up-front y permite correr LLaMA 3.3 70B cuantizado sin costo de inferencia adicional. Comparado con OpenAI GPT-4o (entre USD 50 y USD 150/mes para 10 millones de tokens), el break-even está entre 8 y 24 meses según el volumen. A partir de ese punto, el costo de inferencia es prácticamente cero.
¿Qué regulaciones europeas hacen necesario el self-hosting?
El EU AI Act, con implementación por fases hasta 2027, y el EU Data Boundary de Microsoft Cloud (completado el 26 de febrero de 2025) son los drivers principales. Para organizaciones que procesan datos de ciudadanos europeos, estos marcos pueden requerir que los datos, incluidos los usados para inferencia de IA, permanezcan dentro de infraestructura controlada. El SEC también tiene sus propias reglas (Form 8-K Item 1.05, efectivo diciembre 2023) relevantes para empresas cotizadas.
Conclusión
La IA SRE Self-Hosted en 2026 dejó de ser un experimento académico. Los modelos open-weight llegaron a un nivel donde la pregunta ya no es “¿puede un LLM local hacer esto?” sino “¿tengo los tres stacks bien configurados y sin llamadas salientes?”. LLaMA 3.3 70B, Mistral y Qwen son opciones reales, no workarounds.
El problema del mercado es que la mayoría de los vendors todavía venden privacidad como marketing sin que la arquitectura lo respalde. Que 12 de 15 herramientas se queden en T1 o T2 es un dato que debería estar en la primera página de cualquier evaluación de herramientas.
Si tu organización maneja datos regulados, opera en sectores financieros o de salud, o simplemente no quiere que su telemetría de producción viva en servidores de un tercero, el camino es claro: auditá dónde cae cada herramienta en el Sovereignty Spectrum, construí los tres stacks con componentes que corran local, y calculá el break-even con hardware propio. Los números, en la mayoría de los casos, van a sorprender.
Fuentes
- Self-Hosted AI SRE in 2026: Air-Gapped, Multi-Cloud, BYO-LLM — análisis completo del Sovereignty Spectrum
- OpenSRE en GitHub — framework open-source para agentes SRE
- TrueFoundry — Desplegando LLMs enterprise en industrias altamente reguladas
- Self-hosting LLaMA 70B de forma asequible — guía de hardware y costos
- Microsoft Learn — Patrones de diseño para agentes de IA