Event-driven en DevOps: el error que nadie ve
Un equipo con millones de eventos diarios notó que su procesador tardaba hasta 30 segundos en manejar un solo evento. Agregaron máquinas. El problema siguió. La causa era la configuración por defecto, no la falta de poder computacional, y la solución implicó reescribir el processor desde cero con parámetros ajustados al caso de uso real.
En 30 segundos
- Un sistema de arquitectura event-driven DevOps procesaba 30 segundos por evento debido a configuraciones por defecto no optimizadas para alto tráfico.
- Escalar horizontalmente (más máquinas) no resolvió nada porque el problema era de configuración, no de recursos.
- La solución fue reescribir el event processor con configuración personalizada, sacrificando escalabilidad fácil por mejor mantenibilidad y control.
- Los errores más frecuentes: dual-write sin transacciones atómicas, eventos duplicados sin gestión, y ausencia de dead letter queues.
- El trade-off real no es velocidad vs costo: es escalabilidad automática vs control sobre el sistema.
El Problema Real: Latencia Masiva en Event Processing
La arquitectura event-driven es un patrón donde los componentes de un sistema se comunican mediante eventos asíncronos en vez de llamadas directas. En vez de que el servicio A le pregunte al servicio B “¿qué pasó?”, B emite un evento y A lo consume cuando puede. Limpio en papel, complicado en producción.
Ponele que tu sistema procesa órdenes de compra, logs de acceso, o notificaciones de usuario. Cada acción genera un evento. A escala, eso son millones de eventos por día. El sistema del caso que analiza este artículo técnico publicado el 23 de mayo de 2026 estaba en esa situación: millones de eventos diarios y un processor que tardaba hasta 30 segundos en manejar uno solo.
30 segundos. Por evento. En un sistema que procesa millones.
Las métricas mostraban degradación sostenida: primero fue latencia alta en momentos pico, después se volvió constante. Los usuarios empezaron a notar retrasos. El sistema tenía un cuello de botella clásico pero no donde el equipo miraba primero.
El Primer Intento (y Por Qué Falló)
La respuesta instintiva fue la de siempre: tirá más hierro al problema. Más máquinas en el cluster, más workers, más poder computacional. El equipo asumió que la latencia era un problema de capacidad.
No funcionó. El sistema siguió lento con el doble de nodos. ¿Por qué? Porque estaban escalando el problema, no resolviéndolo.
Las configuraciones por defecto de la mayoría de los brokers de eventos (Kafka, RabbitMQ, o cualquier implementación custom) están pensadas para casos generales, no para sistemas de alto tráfico con requerimientos específicos de latencia. Parámetros como el batch size, los timeouts de consumer, la profundidad de la cola, y el threading model estaban en sus valores default. Agregás más máquinas y cada una sigue usando esos mismos defaults ineficientes. Multiplicás el problema por N. Más contexto en elegir entre Jenkins y GitHub Actions.
El Verdadero Cuello de Botella: Configuración por Defecto
Acá viene lo bueno: los parámetros que más impactan la latencia en un event processor no son los más obvios.
Según la documentación de arquitecturas event-driven de Microsoft Azure, los puntos críticos de configuración incluyen:
- Batch size: qué cantidad de eventos procesa el consumer en una sola operación. Un batch muy pequeño genera overhead de I/O constante. Uno muy grande demora el procesamiento de eventos urgentes.
- Timeouts de consumer: cuánto espera el sistema antes de asumir que un consumer falló. Valores altos bloquean el rebalanceo; valores bajos generan rebalanceos innecesarios que interrumpen el procesamiento.
- Profundidad de la cola y backpressure: sin límites bien configurados, la cola crece sin control y la latencia sube exponencialmente.
- Threading model: si los workers son single-threaded por default y tu carga lo requiere, estás desperdiciando recursos incluso con muchas máquinas.
El problema del sistema del caso no era falta de CPU ni memoria. Era que estaban corriendo configuración de desarrollo en producción.
La Decisión Arquitectónica: Reescribir desde Cero
Después de meses de investigación y pruebas, el equipo tomó la decisión que nadie quiere tomar: reescribir el event processor desde cero con configuración a medida.
No es la solución más cómoda. Una reescritura completa requiere tiempo, testing exhaustivo, y conocimiento profundo de los patrones de carga del sistema. Pero les daba algo que el scaling horizontal nunca podía: control real sobre cada parámetro.
El trade-off explícito fue scalability vs maintainability. La configuración custom es más difícil de mantener que dejar los defaults o agregar nodos. Cada cambio de infraestructura o actualización del broker requiere revisar si los parámetros siguen siendo correctos. Pero el equipo calculó que ese costo de mantenimiento era menor que el costo operativo de un sistema lento y poco predecible.
(Esa decisión tiene sentido cuando el problema de latencia ya está afectando usuarios. Si el sistema zafa con defaults, no hay motivo para complicarlo.) Esto se conecta con lo que analizamos en sistemas distribuidos a múltiples regiones.
Errores Comunes que Prolongan la Latencia
Más allá del caso puntual, cualquiera que haya operado sistemas event-driven en producción se topó con alguno de estos:
Dual-write sin transacciones atómicas
Necesitás guardar en base de datos Y emitir un evento. Si el registro en la BD funciona pero el evento falla (o viceversa), tu sistema queda en estado inconsistente. Sin transacciones atómicas o el patrón outbox, esto pasa más seguido de lo que parece.
Eventos duplicados y desordenados sin handling
Los sistemas distribuidos no garantizan entrega de una sola vez. Tu consumer tiene que ser idempotente: procesar el mismo evento dos veces no debería romper nada. Si no lo implementaste desde el arranque, agregarlo después es un trabajo serio.
Monitoreo que llega después de la crisis
El equipo del caso notó el problema cuando ya tenía 30 segundos de latencia por evento. Para ese momento el daño ya estaba hecho. Sin alertas tempranas sobre latencia por evento, profundidad de la cola, y consumer lag, te enterás tarde siempre.
No tener dead letter queues
Un evento que falla repetidamente sin DLQ configurada puede bloquear el procesamiento de todos los eventos siguientes o perderse sin dejar rastro. Las dead letter queues son la red de seguridad básica de cualquier sistema event-driven serio.
Ignorar la consistencia eventual
Si tu frontend asume que después de emitir un evento el estado está actualizado de inmediato, vas a tener bugs raros y difíciles de reproducir. Los sistemas asíncronos requieren que la UI maneje estados intermedios explícitamente. Tema relacionado: ejecutar agentes sin APIs externas.
Patrones Técnicos para Reducir Latencia
Según análisis de arquitecturas event-driven en entornos DevOps, estas son las intervenciones que más impacto tienen:
| Técnica | Qué resuelve | Cuándo aplicar |
|---|---|---|
| Batch configuration tuning | Reduce overhead de I/O sin sacrificar throughput | Latencia alta con CPU baja |
| Timeout tuning (consumer + rebalance) | Evita rebalanceos innecesarios | Procesamiento interrumpido frecuente |
| Consumer scaling dinámico | Ajusta workers según queue depth real | Carga variable / picos impredecibles |
| Circuit breakers | Evita cascada de fallos downstream | Dependencias externas inestables |
| Retry con exponential backoff | Reduce presión en servicios degradados | Errores transitorios frecuentes |
| Monitoreo de latencia por evento | Detecta problemas antes de que escalen | Siempre, desde el día uno |
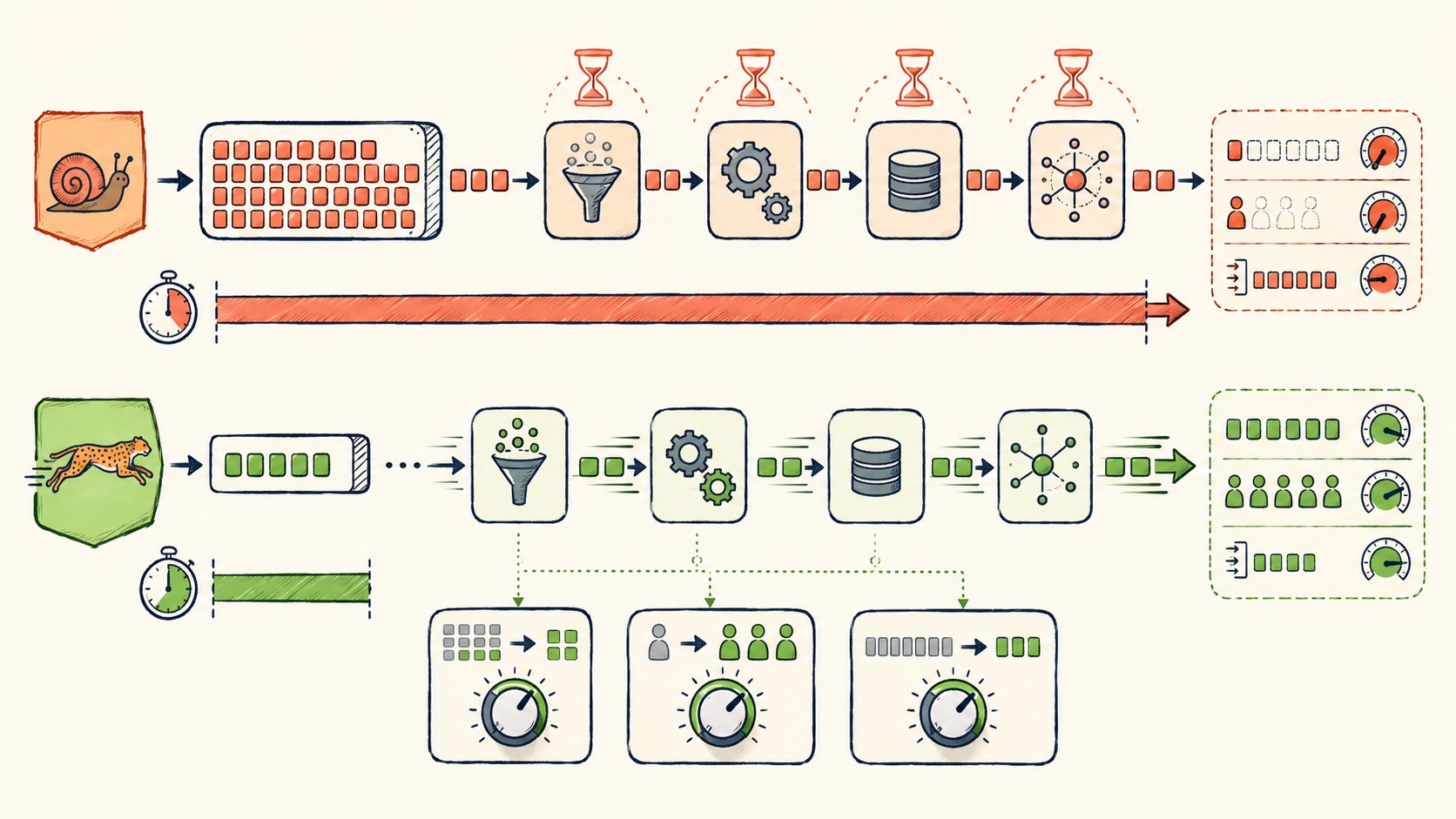
El consumer scaling dinámico merece atención especial: en vez de fijar la cantidad de workers, configurás el sistema para que escale según el consumer lag actual. Si la cola empieza a crecer, levanta más workers automáticamente. Si baja, los reduce. Esto es distinto a escalar la infraestructura horizontal sin más criterio.
El Trade-off Real: Escalabilidad vs Mantenibilidad
Hay una tensión genuina acá que vale la pena nombar con precisión: configuración custom vs defaults + más nodos no es solo una decisión técnica. Es una decisión sobre dónde querés invertir el esfuerzo de tu equipo.
Defaults + scaling horizontal es más fácil de operar en el día a día. Cualquier DevOps nuevo puede agregar nodos. No necesitás expertise específico del processor. Pero pagás en latencia, en inefficiencia de recursos, y en comportamientos impredecibles bajo carga extrema.
Configuración custom te da control total y mejor performance, pero cada cambio de broker o actualización de dependencias puede romper algo. Necesitás a alguien que entienda el sistema profundamente.
¿Cuándo tiene sentido la reescritura custom? Cuando el costo operativo de la latencia supera el costo de mantenimiento de la configuración especializada. Para millones de eventos diarios con SLA de latencia estricto, casi siempre vale la pena. Para un sistema interno con carga moderada, los defaults con buen tuning probablemente alcancen.
La infraestructura donde corre este tipo de sistemas también importa. Si usás cloud propio o VPS, la configuración de red y storage afecta directamente la latencia del broker. Para proyectos argentinos o latinoamericanos que buscan opciones de hosting confiable, donweb.com tiene infraestructura regional que puede hacer diferencia en latencia de red para sistemas distribuidos locales.
Acá hay una conexión clara con Event-driven en DevOps, donde lo explicamos a fondo.
Para ver cómo implementar esto con Socket.io y Railway, revisá nuestro artículo sobre event-driven architecture.
Preguntas Frecuentes
¿Cómo optimizar la latencia en un event processor?
El primer paso es medir latencia por evento, no promedio total. Configurá el batch size según tu perfil de carga real: batches pequeños para baja latencia, más grandes para alto throughput. Ajustá los timeouts de consumer para evitar rebalanceos innecesarios, y configurá consumer scaling dinámico basado en queue depth, no en métricas de CPU. Complementá con seguridad en plataformas de desarrollo.
¿Por qué mi arquitectura event-driven es lenta aunque escale?
Escalar horizontalmente con configuración por defecto multiplica el problema en vez de resolverlo. Los parámetros default no están optimizados para alto tráfico. Antes de agregar más nodos, revisá batch size, timeout de consumers, threading model y profundidad de cola. Si esos valores son los de fábrica, el problema es de configuración, no de capacidad.
¿Cuál es el trade-off entre escalabilidad y mantenibilidad en arquitectura event-driven?
Configuración custom mejora la performance y la predictibilidad, pero requiere expertise específico para mantener. Defaults más scaling horizontal es más fácil de operar pero menos eficiente. La decisión depende del volumen de eventos y el SLA de latencia: para sistemas de millones de eventos con latencia crítica, la inversión en configuración custom casi siempre se justifica.
¿Qué errores evitar en arquitectura event-driven DevOps?
Los cuatro más críticos: no implementar idempotencia en consumers (los duplicados son inevitables), omitir dead letter queues (los eventos que fallan desaparecen o bloquean el pipeline), no configurar monitoreo de consumer lag desde el inicio, y usar dual-write sin transacciones atómicas o patrón outbox. Cualquiera de estos puede generar inconsistencias difíciles de detectar y aun más difíciles de corregir en producción.
¿Cuándo conviene reescribir un event processor desde cero?
Cuando el tuning de parámetros del processor actual ya no da margen y la latencia sigue afectando usuarios. Si el sistema fue diseñado con defaults para bajo tráfico y ahora maneja millones de eventos, la arquitectura base puede ser el límite. Una reescritura con configuración a medida tiene sentido si el equipo tiene el conocimiento del dominio y el tiempo para hacerlo bien. Si no, mejor invertir primero en tuning incremental y monitoreo.
Conclusión
El caso documentado en mayo de 2026 confirma algo que muchos equipos aprenden tarde: en arquitectura event-driven DevOps, el problema de performance rara vez es falta de hardware. La configuración por defecto de los event processors no está pensada para producción de alto tráfico, y agregar nodos sin resolver eso solo escala el cuello de botella.
La lección concreta es esta: medí latencia por evento desde el inicio, configurá cada parámetro según tu perfil de carga real, y construí los mecanismos de resiliencia (DLQs, idempotencia, circuit breakers) antes de necesitarlos. La reescritura custom no siempre es la respuesta, pero cuando el sistema ya no responde a tuning incremental, es la decisión que da control real sobre el comportamiento del sistema.
Fuentes
- Global Creator Lab — Navigating the Pitfalls of Event-Driven Architecture in DevOps (2026)
- Microsoft Azure Architecture Center — Estilo de arquitectura orientado a eventos
- DevOps Freelance — Arquitecturas event-driven en entornos DevOps
- Chakray — Arquitecturas event-driven: ¿panacea o ciclo de sobreexplotación?
- Confluent — Designing Event-Driven Systems