Caching en BD: bajá costos un 94% con Redis
Vivek, desarrollador de Pune, recibió una pregunta inesperada de un cliente: ¿por qué la factura de base de datos sube si el menú del café no cambia? La respuesta, que parece obvia, revela un error que cometen la mayoría de los backends: cada visita al sitio dispara una consulta nueva para traer los mismos datos de siempre. Con caching en base de datos, bajas costos y eso se resuelve en horas.
En 30 segundos
- JSL Café tenía 200 visitas diarias al menú: 200 consultas a la base de datos para traer los mismos precios, sin ningún cambio de datos
- Caching es guardar en memoria el resultado de una consulta cara para no volver a ejecutarla; reduce latencia, carga y factura cloud
- Las tres estrategias principales son TTL (expiración automática), Write-Through (sincronización inmediata) y Cache-Aside (la app gestiona la invalidación)
- Redis soporta estructuras de datos complejas y persistencia; Memcached es más simple y rápido para strings y objetos pequeños
- Un hit ratio por debajo del 70% es señal de que tu configuración de caché tiene algo roto
El problema: consultas redundantes y costos de base de datos fuera de control
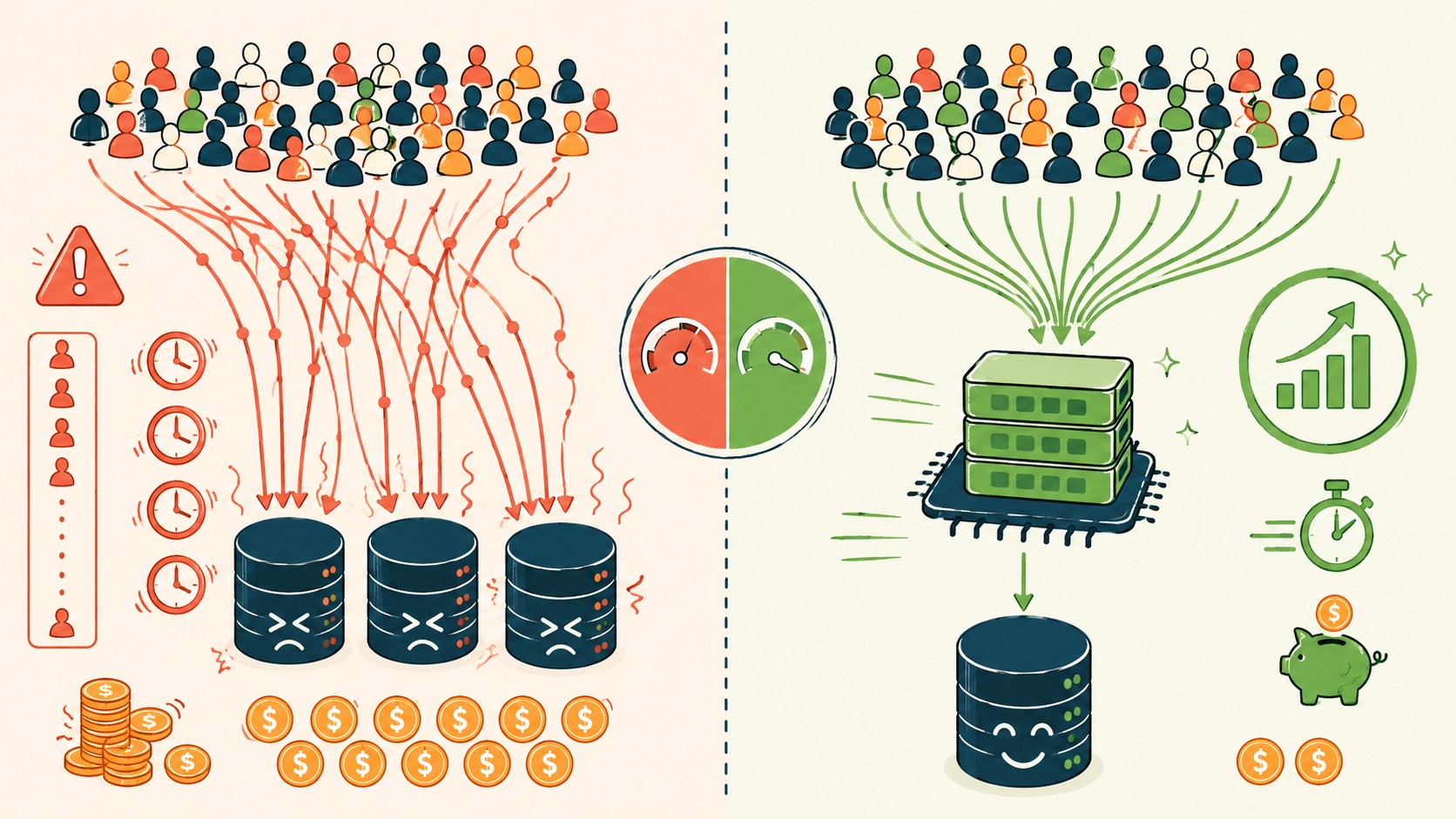
Ponele que tenés una cafetería con un sitio web y tu menú se actualiza una vez por día, a la mañana. Durante todo el día, cada cliente que abre la página desde su celular genera una consulta a la base de datos para traer el mismo listado de platos y precios. 200 clientes: 200 queries idénticas. La base de datos ejecutó 200 veces la misma operación y devolvió exactamente la misma respuesta.
Eso es lo que le pasó a JSL Café and Games en Pune, según cuenta el desarrollador Vivek en su artículo del 24 de mayo de 2026. El dueño del local no es desarrollador, pero entendió algo que muchos juniors pasan por alto: si la respuesta no cambió, ¿para qué ir a buscarla de nuevo?
El escenario no es exclusivo de cafeterías. Una tienda online que consulta disponibilidad de stock, un blog que renderiza el listado de artículos más leídos, una app de reservas que muestra horarios disponibles: todos caen en el mismo patrón. Los servicios cloud cobran por operación de lectura, por transferencia, por tiempo de cómputo. Cada consulta innecesaria se convierte en dinero tirado.
Qué es caching y por qué reduce costos
Caching es guardar el resultado de una operación cara (una consulta a base de datos, una llamada a una API externa, un cálculo pesado) en un almacenamiento rápido y temporal para servir esa respuesta directamente la próxima vez que alguien la pida, sin ejecutar la operación de nuevo.
La analogía de Vivek es precisa: en lugar de mandar a alguien a la cocina cada vez que un cliente pregunta por el menú, ponés una copia impresa en cada mesa. La cocina (tu base de datos) existe y funciona, pero no recibe visitas innecesarias. La copia impresa es el caché.
En términos concretos, los beneficios son:
- Latencia reducida: leer desde memoria RAM es entre 100 y 1000 veces más rápido que una query a PostgreSQL o MySQL en disco
- Carga de base de datos menor: menos conexiones simultáneas, menor consumo de CPU en el servidor de BD
- Factura cloud más predecible: servicios como AWS RDS, Google Cloud SQL o PlanetScale cobran por operaciones de lectura; menos operaciones = menos costo
- Mejor experiencia de usuario: tiempos de respuesta de 1-5 ms desde caché vs. 50-300 ms desde BD
Estrategias principales: TTL, Write-Through, Cache-Aside
No existe un único patrón de caching. Dependiendo de la naturaleza de tus datos, necesitás una estrategia distinta. Usarlas mal genera el efecto contrario al que buscás.
TTL (Time-To-Live)
Cada entrada en el caché tiene un tiempo de vida. Pasado ese tiempo, expira automáticamente y la próxima solicitud va directo a la base de datos para refrescar el valor. Es la estrategia más simple y la más usada para datos que cambian lentamente.
Cuándo usarla: datos que cambian con baja frecuencia y donde mostrarlos levemente desactualizados no genera problemas críticos. El menú de JSL Café con TTL de 1 hora es el caso ideal. Si el dato es precio de cotización en tiempo real, TTL no es suficiente.
Write-Through
Cada vez que tu aplicación escribe en la base de datos, escribe simultáneamente en el caché. El caché siempre está sincronizado con la BD. Nunca hay datos stale (desactualizados) porque la actualización ocurre en ambos lados al mismo tiempo.
El costo: latencia en escritura (escribís dos veces). Y si un dato se escribe frecuentemente pero se lee poco, estás manteniendo en caché información que casi nadie consulta. Para datos con mucha escritura y poca lectura, es overkill.
Cache-Aside (Lazy Loading)
La aplicación gestiona todo manualmente. Cuando llega una solicitud, primero mira si el dato está en caché (cache hit). Si no está (cache miss), va a la BD, trae el dato, lo guarda en caché con su TTL, y lo devuelve. La próxima solicitud ya lo encuentra en caché.
¿Y qué pasa cuando actualizás un dato en la BD? La aplicación debe invalidar el caché manualmente o dejar que el TTL lo expire solo. Acá está el punto débil: si olvidás invalidar, tus usuarios ven datos viejos durante el tiempo que dure el TTL.
Redis vs Memcached: comparativa técnica para tu backend
Las dos herramientas más usadas para caching en producción son Redis y Memcached. La comparación no tiene un ganador universal: depende exactamente de lo que necesite tu sistema.
| Característica | Redis | Memcached |
|---|---|---|
| Tipos de datos | Strings, hashes, listas, sets, sorted sets, bitmaps, streams | Solo strings y objetos binarios |
| Persistencia | Sí (RDB snapshots + AOF logs) | No (solo en memoria, volátil) |
| Clustering | Nativo desde Redis 3.0 | Con librerías externas (consistent hashing) |
| Rendimiento simple | Muy alto (~100k ops/seg en hardware común) | Alto, marginalmente más rápido en operaciones simples |
| Operaciones atómicas | Sí (INCR, LPUSH, ZADD, etc.) | Solo CAS (Check-And-Set) |
| Pub/Sub | Sí | No |
| Licencia | RSALv2 / SSPLv1 desde 2024; versiones < 7.4 bajo BSD | Revised BSD |
| Curva de aprendizaje | Media | Baja |
La regla práctica: si lo único que necesitás es caché de strings o objetos serializados y velocidad máxima, Memcached zafa perfectamente. Si vas a necesitar estructuras más complejas (leaderboards con sorted sets, colas con listas, contadores), pub/sub, o si tu caso requiere persistencia ante reinicios del servidor, Redis es la opción.
AWS documenta esta misma distinción en ElastiCache: recomiendan Memcached para objetos simples y múltiples núcleos de CPU, y Redis para operaciones complejas, replicación, y casos donde la persistencia importa.
Cómo implementar caching en 5 pasos
Ningún framework mágico lo hace por vos (bueno, algunos middleware se acercan, pero siempre hay que configurar). El proceso real tiene estos pasos:
Paso 1: identificar qué datos merece cachear
No todo va al caché. Los candidatos ideales son datos que se leen frecuentemente, cambian con poca frecuencia, y donde mostrarlos desactualizados por minutos u horas no genera problemas. El menú de un restaurante: perfecto. El saldo de una cuenta bancaria: jamás.
Paso 2: elegir la herramienta
Redis o Memcached para caché distribuido en producción. Para desarrollo local o proyectos pequeños, incluso un caché en memoria del proceso (dictionary en Python, Map en Node.js) puede servir, aunque no sobrevive reinicios ni escala horizontalmente.
Paso 3: definir TTL según el tipo de dato
No hay un número mágico. Guía rápida orientativa: datos de configuración del sistema (1 hora a 24 horas), listados de productos o menús (15 min a 2 horas), resultados de búsqueda (5 a 15 min), perfil de usuario (5 a 30 min), datos en tiempo real (0 a 60 seg, si acaso). Ajustá según lo que tu negocio tolera en términos de desactualización.
Paso 4: implementar invalidación manual para datos críticos
Cuando el precio de un producto cambia, no podés esperar que el TTL expire. Necesitás código que, al actualizar el dato en la BD, también borre o actualice la entrada correspondiente en caché. En pseudocódigo: cache.delete("menu:cafe_jsl") inmediatamente después del UPDATE en la base de datos.
Paso 5: monitorear hits y misses
Si no medís, no sabés si tu caché está funcionando. Redis tiene el comando INFO stats que devuelve keyspace_hits y keyspace_misses. El hit ratio es hits / (hits + misses). Por debajo del 70%, algo está mal configurado.
Casos reales: del menú del café a e-commerce
El caso de JSL Café es el punto de partida. Con un TTL de 60 minutos en el listado del menú, las 200 consultas diarias se reducen a 1 por hora durante el horario de operación (digamos 12 horas): de 200 queries a 12 queries. Una reducción del 94%.
Para una tienda online con 10.000 visitas diarias a páginas de producto, los datos de stock y precio son consultados constantemente. Si el precio cambia una vez al día y el stock se actualiza cada 30 min, un TTL de 20 minutos con invalidación manual ante actualizaciones de precio logra reducir las consultas de disponibilidad en más del 95% sin mostrar datos críticos desactualizados. (Sí, el “95%” depende del patrón de visitas, pero para e-commerce con tráfico distribuido en el tiempo, es un número razonable.)
Para un blog como donweb.news, los listados de artículos por categoría, las tags más populares y los widgets del sidebar son datos que cambian cada vez que se publica un artículo, no cada minuto. Un TTL de 5 a 10 minutos en esos endpoints reduce la carga de la BD sustancialmente durante los picos de tráfico, sin que el usuario note nada.
Errores comunes que sabotean tu caché
Cachear datos que cambian constantemente. Si tu dato se actualiza cada 30 segundos, un TTL de 1 minuto no te da ningún beneficio real y agrega complejidad. Primero medí la frecuencia de cambio, después decidí si vale la pena cachear.
TTL demasiado corto (cache thrashing). Si el TTL es más corto que el tiempo entre dos solicitudes del mismo dato, el caché expira antes de que lo use nadie. Tu sistema va a la BD igual, pero encima tiene el overhead de escribir al caché en cada miss. Peor que sin caché.
No invalidar ante actualizaciones críticas. Subís el precio de un producto en el panel de administración. El caché todavía tiene el precio viejo. Un cliente compra al precio anterior. Este error tiene consecuencia directa en ingresos. La invalidación manual no es opcional para datos transaccionales.
Ignorar el fallback. ¿Qué pasa si Redis se cae? Tu aplicación tiene que saber ir directamente a la BD cuando el caché no responde. Si no implementás ese fallback, un reinicio del servidor de caché te tira abajo toda la app. El caché es una optimización, no una dependencia crítica.
No monitorear el hit ratio. Instalás Redis, conectás tu app, y asumís que funciona. Sin métricas, podés tener un hit ratio del 30% (casi todo sigue yendo a la BD) y no saberlo. Configurá alertas desde el día uno.
Monitoreo y métricas: saber si tu caché funciona de verdad
Lo que tenés que medir:
- Hit ratio: porcentaje de solicitudes que el caché responde sin tocar la BD. El objetivo mínimo es 70%; para sistemas bien optimizados, 90%+
- Miss rate: inverso del hit ratio. Un miss alto con TTL largo indica keys mal diseñadas o datos que cambian más de lo esperado
- Latencia promedio: tiempo de respuesta del caché. Si supera los 10 ms constantemente, hay problemas de red o el servidor de caché está saturado
- Evictions: cuántas keys expulsa Redis por falta de memoria. Muchas evictions indican que tu
maxmemoryestá configurado demasiado bajo
En Redis: redis-cli INFO stats y redis-cli INFO memory te dan todo esto. Para producción, herramientas de APM como DataDog o New Relic tienen integraciones nativas con Redis que grafican estas métricas en tiempo real.
Señal de alarma: si tu hit ratio cae de golpe un día determinado, alguien probablemente hizo un deploy que cambió el patrón de keys del caché o que introdujo invalidaciones masivas no planeadas.
Si tu app corre en infraestructura propia o en un servidor VPS, donweb.com tiene planes que permiten instalar Redis directamente en el servidor sin depender de servicios managed externos, lo cual tiene sentido cuando el costo de ElastiCache o Redis Cloud empieza a superar los beneficios para proyectos medianos.
Preguntas Frecuentes
¿Cómo implementar caching en mi base de datos sin experiencia previa?
Instalá Redis localmente (docker run -d -p 6379:6379 redis), conectalo a tu app con la librería cliente del lenguaje que usés (ioredis para Node.js, redis-py para Python, Predis para PHP), e implementá el patrón Cache-Aside: antes de consultar la BD, preguntale al caché; si no está, consultá la BD, guardá el resultado en caché con un TTL, y devolvé la respuesta. Tres días de implementación para un caso básico es realista.
¿Por qué aumentan los costos de mi base de datos en cloud?
Los servicios managed de BD (AWS RDS, Google Cloud SQL, PlanetScale, Supabase) cobran por número de operaciones de lectura/escritura, por tiempo de cómputo del servidor, y por transferencia de datos. Si cada visita a tu sitio genera 5 queries y recibís 10.000 visitas al día, eso es 50.000 operaciones diarias para datos que quizás cambiaron una sola vez. El caching corta esas operaciones en un 80-95% para datos semi-estáticos.
¿Redis o Memcached? ¿Cuál usar para caching?
Para la mayoría de los casos nuevos en 2026, Redis. Soporta más tipos de datos, tiene persistencia opcional, y su ecosistema es más maduro. Memcached tiene sentido si tenés una arquitectura ya existente basada en él, o si específicamente necesitás escalar horizontalmente en múltiples hilos de CPU con objetos simples y querés la menor complejidad posible. Redis cubre los casos de uso de Memcached y los supera en la mayoría de los escenarios modernos.
¿Cómo evitar consultas innecesarias a la base de datos?
Primero, identificá cuáles son las queries más frecuentes con un profiler (EXPLAIN ANALYZE en PostgreSQL, slow query log en MySQL). Segundo, clasificalas por frecuencia de cambio del dato: lo que cambia poco es candidato a caché. Tercero, implementá Cache-Aside con TTL apropiado para cada tipo de dato. Cuarto, revisá si tenés N+1 queries (problema diferente al caching, pero igualmente costoso): consultas que generan una query por cada ítem de una lista en lugar de una sola query con JOIN.
Esto se conecta con optimización de base de datos, donde cubrimos el tema en detalle.
Para seguir el tema, acá tenemos My client asked why his database bill was increasing. The an, donde ampliamos la discusión.
Abundamos sobre esto en My client asked why his database bill was increasing. The an.
Esto que mencionás se conecta con nuestro análisis en My client asked why his database bill was increasing. The an.
¿Qué estrategia de cache-invalidation usar?
Para datos que toleran cierta desactualización (menús, listados, configuraciones): TTL pasivo. Para datos que deben estar actualizados inmediatamente ante un cambio (precios en e-commerce, permisos de usuario, inventario crítico): invalidación activa manual, borrando o actualizando la clave del caché en el mismo código que escribe en la BD. Para sistemas de alta consistencia con muchas escrituras: Write-Through, aunque implica mayor latencia en operaciones de escritura. Combinar TTL con invalidación manual cubre el 90% de los casos reales.
Conclusión
La historia del café de Pune no es una anécdota simpática. Es el patrón exacto que se repite en miles de apps: datos que no cambian, consultados una y otra vez como si fueran volátiles. La factura sube, el sistema se carga, y nadie revisa el código porque “funciona”.
Implementar caching no requiere una arquitectura nueva. Requiere entender qué datos cambian cuándo, elegir la herramienta correcta (Redis en la mayoría de los casos), definir TTLs razonables, y agregar invalidación manual donde los datos son críticos. Con eso cubierto, el hit ratio sube por encima del 80% y las consultas a la BD bajan drásticamente. La factura también.
El dueño del café preguntó la pregunta correcta. La pregunta que deberías hacerte sobre tu propio sistema es: ¿cuántas de mis consultas de hoy devolvieron exactamente el mismo resultado que las de ayer?