Capa de análisis sobre tu base de datos sin data warehouse
Tu base de datos de producción aguanta las transacciones sin drama, hasta que alguien pide un dashboard. Ahí una query analítica escanea 2 millones de filas, tarda 14 segundos y clava el CPU al 90%. La salida no es un data warehouse: alcanza con armar una capa de análisis base de datos sobre lo que ya tenés.
Una capa de análisis es un conjunto de patrones de arquitectura y estructuras SQL que se ubica entre los datos crudos de tu aplicación y las queries de reporting. Su trabajo es aislar las consultas analíticas del tráfico de producción, pre-calcular agregaciones costosas y exponer superficies de consulta rápidas a los dashboards. No es un producto aparte: lo armás con réplicas de lectura, vistas y materialized views que ya vienen en tu motor.
En 30 segundos
- Las bases transaccionales se optimizan para escrituras rápidas y lookups puntuales; las queries analíticas hacen lo contrario (escaneos amplios, joins múltiples, agregaciones pesadas).
- Una query de churn por plan que toca 5 tablas y escanea 2 millones de filas puede tardar 14 segundos y clavar el CPU al 90% cada 5 minutos.
- El primer paso, y el más barato, es rutar el tráfico analítico a una réplica de lectura. Aislamiento inmediato.
- El segundo paso es pre-calcular con materialized views las agregaciones que pedís todo el tiempo.
- El data warehouse recién entra cuando ni la réplica ni las vistas alcanzan: muchas fuentes de datos, volumen creciente, queries que siguen lentas.
¿Por qué tus queries analíticas ralentizan la base de datos de producción?
Ponele que llevas seis meses adentro de tu producto SaaS. La app anda, los usuarios se registran, los datos fluyen. Alguien del equipo larga la frase fatídica: “¿Podemos tener un dashboard de churn por plan?”. Escribís la query. Toca cinco tablas, escanea 2 millones de filas, tarda 14 segundos. La pegás en un dashboard. Y ahora cada carga de página se arrastra y el CPU de tu base salta al 90% cada cinco minutos.
Acá viene el choque de fondo. Una base transaccional (Postgres, MySQL) está afinada para escribir rápido y buscar un registro puntual por su índice. La carga analítica es la otra cara: leer rangos enormes, cruzar varias tablas y sumar todo. Cuando corrés las dos cargas en el mismo motor, sin ninguna abstracción en el medio, las dos sufren. Las transacciones de tus usuarios compiten por el mismo buffer pool que tu reporte de 14 segundos. Esto se conecta con lo que analizamos en automatizar el despliegue de tu capa analítica.
El tema es que esto no se arregla con un índice más. Es un conflicto de propósito.
Qué es una capa de análisis y cómo funciona
Como adelantamos arriba, no es software que instalás. Es una decisión de arquitectura. Según el artículo de Vivek en dev.to que motiva esta nota, la capa persigue tres objetivos concretos:
- Aislar el tráfico analítico. Que tus reportes no toquen jamás la base que sirve a los usuarios.
- Pre-calcular lo caro. Si una agregación se pide mil veces por día, la calculás una vez y la guardás.
- Exponer superficies rápidas. Darle a los dashboards tablas y vistas pensadas para leer, no para escribir.
Lo logras con tres herramientas que ya tenés: réplicas de lectura, vistas materializadas y desnormalización. El flujo es simple: datos crudos en la primaria, una réplica que copia esos datos, vistas pre-calculadas sobre la réplica, y los dashboards consultando esas vistas. Nada de tu stack de reporting toca la primaria.
Patrón 1: rutar el tráfico de análisis a una réplica de lectura
Es el primer movimiento y el de mejor relación esfuerzo/resultado. Una réplica de lectura es una copia de tu base que recibe los cambios de la primaria y atiende solo SELECTs. Apuntás todas las queries de dashboards a esa copia y listo: tu reporte de 14 segundos ya no compite con el checkout de un cliente.
Postgres lo hace con replicación lógica o física; MySQL con su replicación binaria nativa. En los dos casos la primaria sigue liviana y la réplica absorbe el castigo.
Eso sí: la réplica tiene consistencia eventual. Hay un lag de replicación, normalmente por debajo de un segundo, en el que la copia va atrás de la primaria. Para un dashboard de churn no importa que los datos tengan ese atraso mínimo. Para mostrarle a un usuario el saldo exacto de su cuenta, sí importa, y ahí la réplica no zafa. Si manejás una réplica gestionada en un VPS o servidor cloud, conviene tenerla en infraestructura seria; para hosting y servidores en Argentina, donweb.com es una opción para no pelear con la latencia.
Pre-computar agregaciones para las queries más frecuentes
La réplica te saca el problema de encima, pero la query de 14 segundos sigue tardando 14 segundos. Solo que ahora molesta en otro lado. El patrón 2 ataca eso: pre-calcular. Tema relacionado: integrar tu orquestador de CI/CD con la recolección de datos.
Una materialized view guarda el resultado de una query pesada como si fuera una tabla. En vez de escanear 2 millones de filas cada vez que abrís el dashboard, escaneás el resultado ya cocinado, que ponele tiene 50 filas. La consulta pasa de segundos a milisegundos.
¿El trade-off? La frescura. La vista materializada es una foto del momento en que la refrescaste. Si la actualizás cada hora, los datos tienen hasta una hora de atraso. Para métricas de negocio (ingresos por plan, usuarios activos por semana, conversiones por canal) eso está perfecto. Definís un refresh cada 15 minutos, cada hora o cada noche según cuánto tolere el dato, y dormís tranquilo.
La pregunta es: ¿qué pre-calculás? Lo que se repite. Si el mismo GROUP BY corre en cinco dashboards distintos, esa es tu primera materialized view.
Crear superficies de query rápidas y consistentes
El tercer patrón es darle forma a lo que los dashboards consumen. Acá entran las tablas desnormalizadas y los data marts livianos: una tabla ancha, pensada para leer, que junta lo que está disperso en cinco tablas normalizadas. Lo explicamos a fondo en garantizar la privacidad de tus datos analíticos.
En vez de hacer que cada herramienta de BI repita el mismo join monstruoso, lo resolvés una vez y dejás una superficie limpia. Encima de esa superficie se sientan Metabase, Superset o cualquier tool que tu equipo prefiera, sin que ninguno toque la base de producción. Menos joins en tiempo real, queries más predecibles, y un analista que no tiene que entender tu esquema entero para sacar un número.
Herramientas que podés usar sin cambiar la infraestructura
Lo bueno de todo esto: probablemente ya tengas las tres piezas. Mirá la comparación:
| Patrón | Qué resuelve | Frescura del dato | Esfuerzo | Cuándo usarlo |
|---|---|---|---|---|
| Réplica de lectura | Aísla el tráfico analítico de producción | Lag por debajo de un segundo | Bajo | Primer paso, casi siempre |
| Materialized view | Elimina el costo de agregaciones repetidas | Minutos u horas (según refresh) | Medio | Queries que se repiten mucho |
| Tabla desnormalizada | Da superficies anchas y limpias para BI | Según el job que la llena | Medio/alto | Varios dashboards sobre el mismo join |
| Data warehouse | Centraliza múltiples fuentes a escala | Según pipeline ETL | Alto | Cuando lo anterior no alcanza |
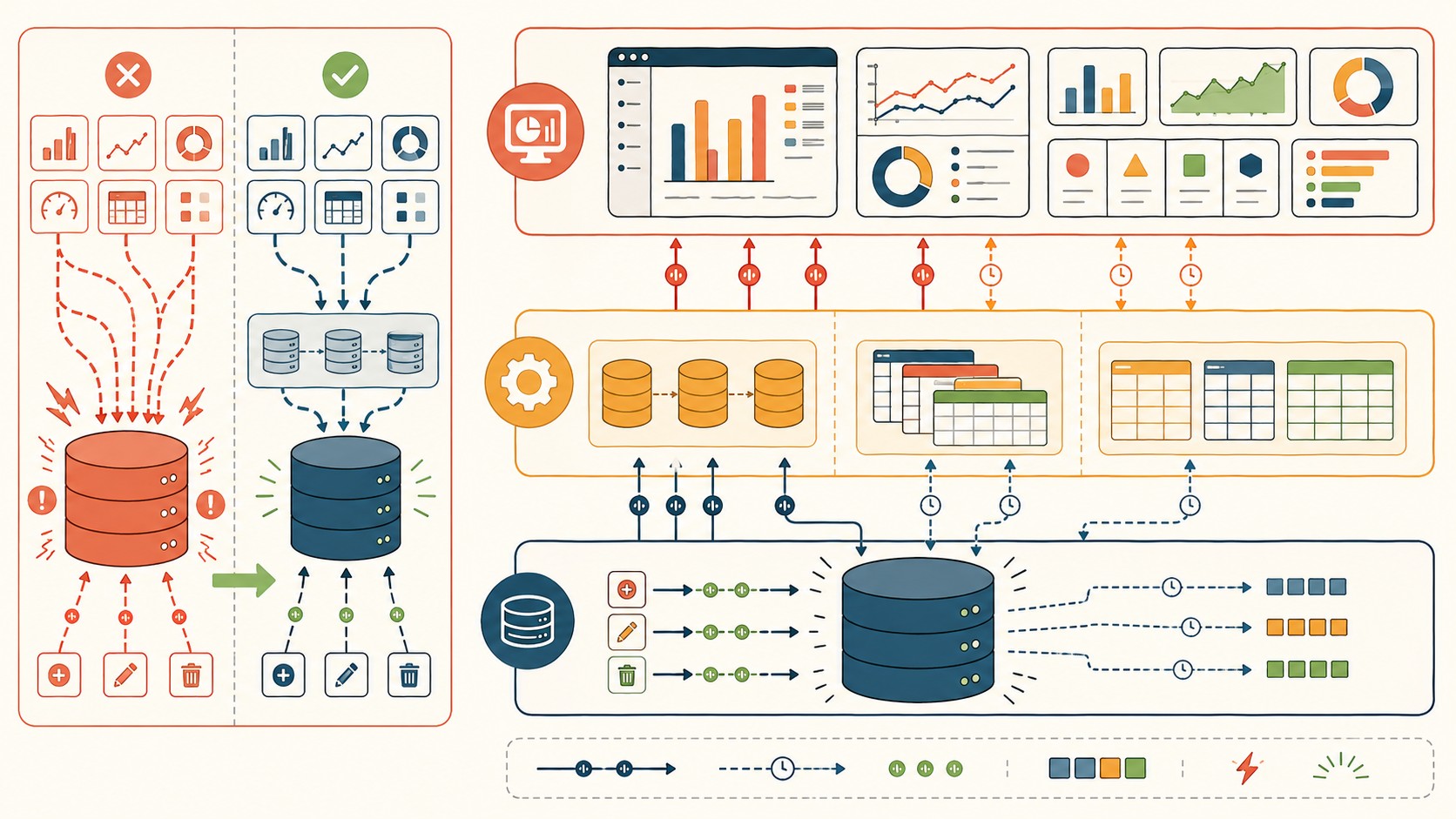
Las tres primeras filas son nativas de tu motor. Réplicas, vistas e índices agresivos sobre la réplica no te piden plata nueva ni un equipo de data. Las herramientas de BI se apoyan arriba sin tocar nada de la base primaria.
Cuándo pasar a un data warehouse real
Ahora bien, la capa liviana tiene techo. Hay señales claras de que te quedaste corto: En potenciar tus análisis con herramientas de IA profundizamos sobre esto.
- Las queries siguen lentas aun con réplica y vistas materializadas funcionando.
- El volumen crece sin parar y la réplica ya no copia a tiempo.
- Tenés varias fuentes de datos (la app, el CRM, el sistema de pagos) y necesitás cruzarlas en un solo lugar.
- Aparecen requisitos de retención y de histórico que la base operativa no fue pensada para guardar.
Recién ahí tiene sentido un BigQuery, un Snowflake o un Redshift. No antes. Saltar al warehouse cuando una materialized view resolvía el 90% del problema es pagar complejidad que no necesitás todavía.
Qué está confirmado y qué no
Confirmado (documentación oficial de los motores):
- Postgres y MySQL soportan réplicas de lectura nativas, según sus manuales oficiales de replicación.
- Las materialized views guardan el resultado físico de una query y se refrescan bajo demanda o por schedule.
- La eventual consistency de las réplicas es inherente al modelo: siempre hay lag, por chico que sea.
Pendiente o depende de tu caso:
- El número de “14 segundos” y “2 millones de filas” viene del ejemplo del artículo original; en tu base puede ser mejor o mucho peor.
- Cada cuánto refrescar una vista no tiene receta: depende de cuánta frescura tolere cada métrica.
- El punto exacto en que conviene migrar a warehouse varía según volumen, presupuesto y cantidad de fuentes.
Errores comunes al armar la capa de análisis
- Correr reportes contra la primaria “porque es un ratito”. Ese ratito es el que te clava el CPU al 90%. Mandá todo lo analítico a la réplica desde el día uno.
- Materializar todo. Cada vista materializada hay que refrescarla, y eso también cuesta. Pre-calculá solo lo que se repite de verdad, no cada query que se te cruza.
- Mostrar datos de réplica donde el usuario espera exactitud al instante. Para un saldo o un stock en vivo, el lag de replicación te juega en contra. Esas lecturas van a la primaria.
- Saltar directo al data warehouse. Es la solución más cara y la última de la lista, no la primera. Si no probaste réplica y vistas, no sabés si las necesitabas.
Preguntas Frecuentes
¿Cómo hago analytics sin que se ralentice mi base de datos de producción?
Rutá todas las queries analíticas a una réplica de lectura, no a la primaria. La réplica es una copia que solo atiende SELECTs, así tus reportes nunca compiten con las transacciones de los usuarios. Es el cambio más barato y de mayor impacto.
¿Qué es una capa de análisis y por qué la necesito?
Es un conjunto de patrones SQL y de arquitectura (réplicas, vistas materializadas, tablas desnormalizadas) entre tus datos crudos y tus reportes. La necesitás porque las bases transaccionales y las cargas analíticas tienen propósitos opuestos: correrlas juntas degrada a las dos.
¿Puedo usar réplicas de lectura para queries analíticas?
Sí, y es el primer paso recomendado. Postgres y MySQL traen replicación nativa. La única salvedad es la eventual consistency: la réplica va por debajo de un segundo atrás de la primaria, así que sirve para dashboards de negocio pero no para datos que el usuario necesita exactos al instante.
¿Necesito un data warehouse completo o hay opciones más simples?
En la mayoría de los casos no lo necesitás todavía. Réplicas de lectura más materialized views resuelven el grueso del problema sin infraestructura nueva. El warehouse recién se justifica cuando tenés múltiples fuentes de datos, volumen creciente y queries que siguen lentas pese a la capa liviana.
¿Cuál es el primer paso para optimizar analytics en mi base de datos?
Crear una réplica de lectura y apuntar todos los dashboards ahí. Aísla el tráfico analítico de inmediato y no toca tu esquema. Después, recién después, pre-calculás con materialized views las agregaciones que más se repiten.
Conclusión
El reflejo de muchos equipos cuando los dashboards se ponen lentos es saltar a un data warehouse. Casi nunca hace falta. Una réplica de lectura te aísla el tráfico, una vista materializada te mata la query de 14 segundos, y una tabla ancha le da a tu BI una superficie limpia. Las tres ya están en tu motor.
Armá la capa por capas, valga la redundancia: réplica primero, después pre-cálculo, después superficies. Medí si todavía duele. Si después de eso las queries siguen lentas y tenés varias fuentes para cruzar, ahí sí, el warehouse es el siguiente paso lógico. Antes, es complejidad que no estás necesitando.