Fabric CI/CD problemas: lo que nadie te cuenta en 2026
Son las tres de la tarde de un viernes, tu pipeline de Azure DevOps compiló sin errores, los items de Fabric sincronizaron y la puerta de release pasó verde. El lunes a las nueve de la mañana, el ingeniero de datos te avisa que el refresh del Semantic Model está roto, las particiones del lakehouse se corrompieron y nadie puede abrir un reporte sin un timeout. Esa es la historia de los fabric cicd problemas que los tutoriales oficiales no documentan, y que la comunidad japonesa viene mapeando con detalle desde principios de 2026.
El deployment gap de Microsoft Fabric CI/CD es la brecha entre lo que la documentación oficial de Microsoft asume sobre el despliegue de items —semantic models, lakehouses, data pipelines, notebooks y reportes— y lo que efectivamente ocurre cuando movés esas definiciones JSON de un workspace de staging a uno de producción. La comunidad japonesa, encabezada por el desarrollador ryoma-nagata en Qiita, armó un flujo completo para Azure DevOps Pipelines que expone las dependencias implícitas, los límites de API y la ausencia total de rollback nativo. El problema no es teórico: son equipos perdiendo horas de productividad por asumir que un lakehouse y un semantic model pueden desplegarse en el orden que se te cante.
En 30 segundos
- Los items de Fabric tienen dependencias que los JSON no capturan. Un semantic model depende de tablas de un lakehouse que aún no se termina de desplegar, y el orden de despliegue que usás en el pipeline define si el refresh funciona o explota.
- Los límites de API de Fabric penalizan los despliegues concurrentes. Workspaces grandes alcanzan el throttling cuando desplegás muchos items a la vez; se necesita lógica de backoff y reintentos que no viene en ningún template oficial.
- Fabric no tiene semántica de rollback. Si un despliegue corrompe medidas o metadatos, volver atrás implica reimportar manualmente desde un workspace de backup, sin ayuda de la plataforma.
- La comunidad japonesa ya testeó en producción lo que acá recién estamos sufriendo. Recomiendan despliegue secuencial, bloqueo de workspace durante las ventanas de deploy, y parametrización consciente de la capacidad entre entornos.
¿Qué dependencias implícitas existen entre los items de Fabric?
Ponele que estás migrando un reporte de ventas de staging a producción. El JSON de definición del reporte apunta a un semantic model, ese semantic model consume tablas de un lakehouse que a su vez se nutre de un data pipeline que dejaste corriendo la noche anterior. En los tutoriales cada item se trata como un bloquecito independiente que podés mover en cualquier orden porque “el workspace resuelve las referencias”. La realidad es otra.
Cuando desplegás, el semantic model intenta refrescarse contra tablas del lakehouse que o no existen todavía o tienen una estructura distinta a la que espera (porque el pipeline de staging terminó antes pero el de producción, no). El reporte, mientras tanto, se publica y apunta a un semantic model que acaba de fallar la validación de esquema. ¿El resultado? Timeouts en cascada y horas de debugging un lunes a las ocho de la mañana. La documentación que armó ryoma-nagata en Qiita mapea estas dependencias a mano: recomienda exportar los items como JSON con las referencias explícitas, validar que los IDs de workspace de destino coincidan, y —esto es clave— respetar un orden de despliegue que resuelva primero las capas de datos y después las capas semánticas y de visualización. Más contexto en nuestra comparativa entre ambas plataformas.
¿Por qué el orden de despliegue es crítico en Fabric CI/CD?
El orden importa, y no un poco: es la diferencia entre un deploy silencioso y un sábado conectado a la VPN. Si desplegás un semantic model antes de que el lakehouse subyacente tenga sus tablas listas, el refresh va a fallar y vas a necesitar ejecutarlo de nuevo manualmente (si es que el modelo no quedó en un estado inconsistente). Al revés tampoco sirve: si desplegás el lakehouse, pero el pipeline que lo alimenta aún no corrió en el entorno nuevo, el modelo semántico se encuentra con una carcasa vacía.
El pipeline de Azure DevOps que documenta la comunidad japonesa (basado en el enfoque de ryoma-nagata) resuelve esto con secuenciación explícita: primero los data pipelines y lakehouses, después los notebooks que transforman datos, luego los semantic models, y recién al final los reportes. No hay magia —es un YAML con dependsOn bien puesto y esperas activas que verifican que cada capa esté operativa antes de pasar a la siguiente. Microsoft, en su tutorial de CI/CD con Azure DevOps, menciona la exportación de items pero deja el orden a criterio del desarrollador. Ahí está la trampa.
¿Cómo afectan los límites de API de Fabric a los despliegues concurrentes?
Fabric tiene un límite de requests por minuto sobre sus APIs de administración, y en workspaces con una cantidad significativa de items ese límite se alcanza rápido cuando desplegás todo en paralelo. El throttling no es amable: devuelve errores 429 que en teoría podés reintentar, pero la documentación oficial no especifica un backoff estándar, y en la práctica algunos items quedan a medio crear mientras otros fallaron del todo. Se genera un estado sucio que Fabric no limpia solo.
Ryoma-nagata metió en su pipeline una lógica de throttling con reintentos exponenciales, pero además recomendó algo más drástico: ventanas de despliegue con el workspace bloqueado. Sin tráfico de usuarios concurrente, las APIs responden mejor. También sugiere dividir el despliegue en batches de pocos items, con pausas entre tandas. Es rudimentario, sí, pero funciona. Cualquiera que haya corrido un despliegue de 60 items y visto cómo explota a la mitad sabe que rudimentario y funcional es mejor que “best practice” y roto.
¿Qué problemas de capacidad surgen al pasar de un workspace a otro?
Acá hay otra trampa fina: los workspaces de Fabric pueden estar asociados a capacidades distintas. Un semantic model que funciona bárbaro en un workspace con Premium Per User (PPU) puede fallar cuando lo movés a un workspace atado a una capacidad Premium comprada por capacidad reservada, porque ciertas funcionalidades (por ejemplo, la escritura directa sobre XMLA endpoints o algunas opciones de refresh programado) están restringidas en función del tier. Lo explicamos a fondo tras el incidente de seguridad en repositorios.
Los archivos de definición JSON no siempre incluyen esas restricciones de capacidad; son metadatos del workspace de origen que no se exportan o que se pierden en la parametrización. La comunidad japonesa recomienda parametrización consciente de la capacidad: identificar en el pipeline de release qué features dependen de la capacidad y reemplazar los valores en el JSON antes de hacer el PUT a la API de Fabric. Ojo, no es una solución mágica —requiere que el equipo conozca bien las diferencias entre tiers— pero evita el clásico “en staging anda y en prod no”.
¿Cómo implementar rollback cuando un despliegue de Fabric falla?
La respuesta corta: no podés. Fabric CI/CD no tiene semántica de rollback nativa, punto. Si un despliegue corrompe medidas de un semantic model o deja un reporte apuntando a un ID de modelo que ya no existe, no hay un botón de “deshacer” ni un comando de API que restaure el estado anterior del workspace.
La respuesta larga: mantenés un workspace de backup que es un snapshot limpio del último estado bueno, y cuando algo sale mal reimportás manualmente desde ahí. Es un enfoque casero, pero es lo que la comunidad japonesa valida después de varios desastres en producción. Ryoma-nagata sugiere automatizar la creación de ese snapshot como paso previo al despliegue, con un pipeline que clone los items del workspace productivo a uno de backup usando las mismas APIs de Fabric. ¿Alguien lo verificó de forma independiente? Todavía no a gran escala, pero el patrón es sensato y no requiere features que Fabric no tenga hoy. Eso sí, asumí que el RTO (Recovery Time Objective) va a ser de decenas de minutos, no de segundos.
¿Qué prácticas recomienda la comunidad japonesa para producción?
Después de hacer stress-testing con workspaces reales —y de comerse los errores de timeout, corrupción y throttling—, los desarrolladores japoneses compilaron un conjunto de prácticas que, sin ser oficiales, marcan la diferencia entre un deploy que sobrevive y uno que te arruina el finde: Tema relacionado: como vimos al analizar las opciones de CI/CD.
- Despliegue secuencial por capas de dependencia. Nada de paralelismo total: data pipelines y lakehouses primero, notebooks después, semantic models en tercer lugar, y reportes al final.
- Bloqueo de workspace durante la ventana de despliegue. Suspender el acceso de usuarios y cargas programadas evita conflictos con las APIs y mejora la consistencia.
- Workspace de backup como objetivo de rollback. Es manual, pero es lo único que funciona hoy.
- Parametrización consciente de la capacidad. Revisar y ajustar en el pipeline las features que dependen del tier del workspace destino.
- Throttling con reintentos exponenciales y batching. Dividir el despliegue en grupos pequeños con pausas entre tandas.
Estas prácticas, según reporta el análisis publicado en Dev.to, no son especulación: la comunidad japonesa las aplicó en entornos con decenas de workspaces y items, encontrando los bordes que los tutoriales oficiales de Microsoft omiten. La documentación en inglés sigue siendo escasa, y los equipos que no leen japonés están pagando el precio con madrugadas de soporte.
| Problema | Causa raíz | Mitigación recomendada |
|---|---|---|
| Dependencias implícitas no resueltas | JSON de items no captura referencias entre capas | Orden explícito: lakehouse → modelo → reporte |
| Errores 429 por throttling | Límites de API sin backoff documentado | Batching de pocos items + reintentos exponenciales |
| Fallas por cambio de capacidad | Features atadas al tier no se exportan en definiciones | Parametrización del tier en pipeline de release |
| Rollback inexistente | Fabric no tiene API de restauración de workspace | Snapshot pre-deploy a workspace de backup |
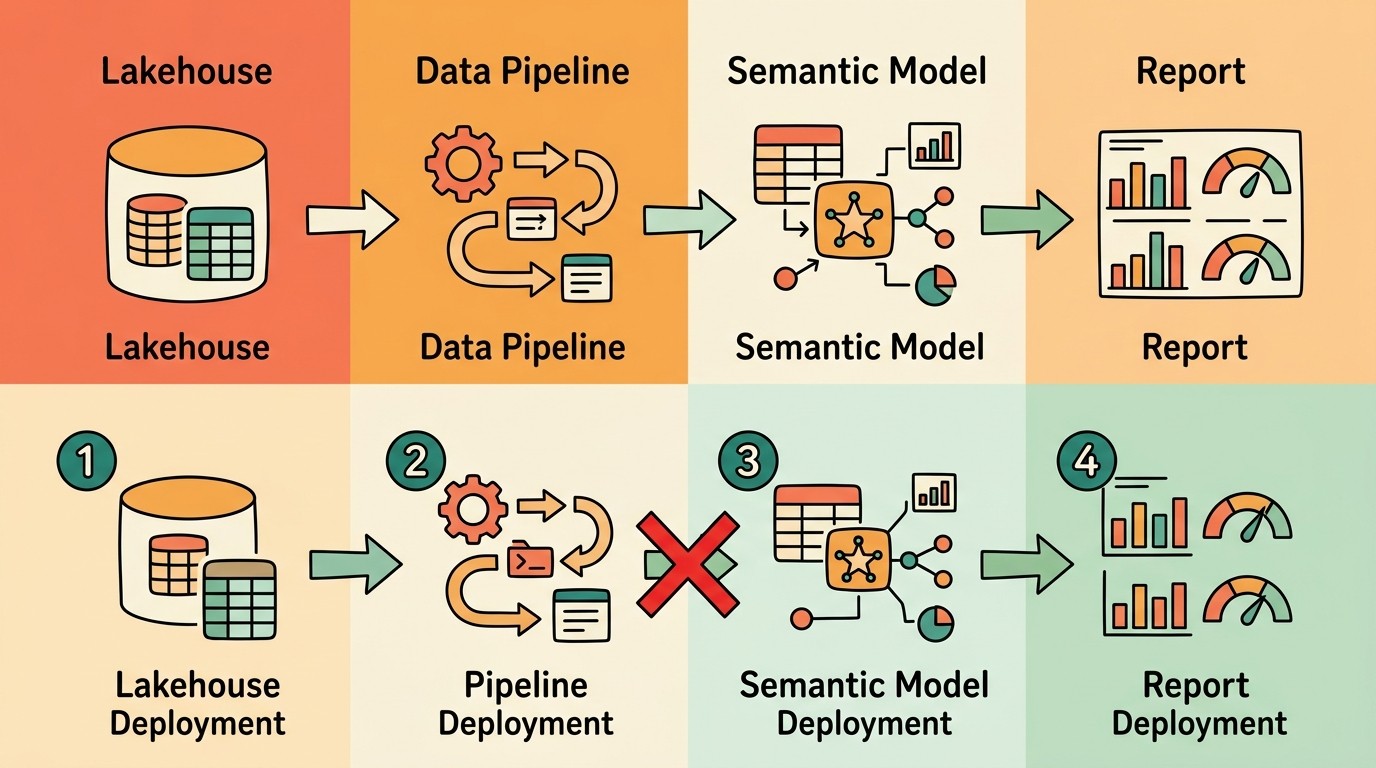
Errores comunes al hacer CI/CD en Microsoft Fabric
1. Desplegar todos los items en paralelo sin secuenciar.
El error más típico. El template de Azure DevOps te tienta a meter todos los items en un loop y ejecutarlos concurrentemente. Funciona en ambientes chicos de prueba y explota en cualquier workspace que pese un poco. La corrección es construir stages con dependencias explícitas, como harías en cualquier pipeline de datos que se respete.
2. No validar el entorno de capacidad antes del despliegue.
Muchos equipos dan por sentado que el workspace de producción tiene el mismo tier que el de staging. Cuando no, los errores no son evidentes: el item se despliega “bien” pero falla al primer refresh. Agregá un paso de validación de capacidad en el pipeline (un script que compare los settings del workspace origen y destino) antes de mover nada.
3. Confiar ciegamente en la idempotencia de las APIs de Fabric.
Las APIs son idempotentes en la teoría: si mandás dos veces el mismo JSON, el estado final debería ser el mismo. En la práctica, las race conditions entre requests concurrentes generan estados intermedios sucios. Si vas a reintentar, hacelo con cuidado y siempre después de verificar el estado del item, no asumiendo que el PUT previo dejó todo prolijo.
Preguntas Frecuentes
¿Por qué falla mi pipeline de Fabric CI/CD en producción si en staging funciona bien?
La causa más frecuente es una combinación de orden de despliegue incorrecto y diferencias de capacidad entre workspaces. Los items se despliegan sin respetar las dependencias (un semantic model antes que su lakehouse) y, además, el tier de producción puede no soportar las mismas features que el de staging. Validá el orden de stages en tu pipeline y compará las capacidades de ambos workspaces antes de cada release. Relacionado: al detallar las diferencias entre herramientas.
¿Cómo manejar dependencias entre items en Fabric?
Identificá las dependencias implícitas que los JSON de definición no capturan, sobre todo lakehouses que alimentan semantic models y modelos que alimentan reportes. Secuenciá el despliegue en capas: primero pipelines y lakehouses, luego notebooks, después semantic models, y al final reportes. Agregá esperas activas que verifiquen que cada capa esté operativa antes de pasar a la siguiente.
¿Qué hacer cuando el refresh del semantic model falla después del deploy?
No reintentes el refresh sin revisar el estado del lakehouse subyacente. Es probable que el lakehouse no tenga aún las tablas esperadas porque su propio pipeline no corrió en el entorno de destino. Verificá la integridad de las capas de datos, asegurate de que el lakehouse esté listo, y recién ahí ejecutá el refresh. Si el modelo quedó inconsistente, reimportalo desde un workspace de backup.
¿Cuáles son los límites de API de Fabric en despliegues concurrentes?
Fabric impone un límite de requests por minuto sobre sus APIs de administración. Alcanzarlo genera errores HTTP 429 (Too Many Requests). En workspaces con una cantidad elevada de items, un despliegue paralelo lo detona casi seguro. Mitigalo dividiendo el despliegue en batches de pocos items con pausas y usando reintentos con backoff exponencial.
Conclusión
El deployment gap en Microsoft Fabric CI/CD es un agujero negro de horas de soporte que los equipos están empezando a dimensionar ahora, en 2026. La documentación oficial te lleva hasta un “hello world” prolijo, pero en producción los items tienen dependencias reales, las APIs tienen límites, y no existe una forma nativa de volver atrás. La comunidad japonesa lo entendió antes y compartió patrones concretos —secuenciación, throttling, backups manuales— que hoy son la única guía confiable para no dejar la salud mental en cada release. Si tu equipo usa Fabric y está armando pipelines de CI/CD, revisar estos patrones no es opcional: es lo que separa un deploy silencioso de un lunes de emergencia.
Fuentes
- Microsoft Fabric CI/CD: The Deployment Gap Nobody Talks About – Dev.to – Artículo original que recopila los hallazgos de la comunidad japonesa sobre los problemas en producción.
- Tutorial de CI/CD con Azure DevOps para Microsoft Fabric – Microsoft Learn – Documentación oficial en inglés que detalla el flujo de exportación y despliegue de items.
- Tutorial de CI/CD con Azure DevOps para Microsoft Fabric – Microsoft Learn ES – Versión en español del tutorial oficial.