Inteligencia de infraestructura: el salto post-AIOps
La inteligencia de infraestructura es el modelo operativo que reemplaza las reglas IF/THEN de la automatización clásica por sistemas que analizan patrones y deciden solos. Según la investigación de Pulumi sobre tendencias cloud publicada en 2026, dejó de ser un experimento de laboratorio para volverse prioridad estratégica en empresas que manejan workloads distribuidos.
La inteligencia de infraestructura (o AIOps, por sus siglas en inglés) es la aplicación de machine learning y análisis de datos a la gestión de infraestructura IT para detectar anomalías, predecir fallas y tomar decisiones operativas sin reglas predefinidas. Red Hat e IBM la describen como la capa que procesa telemetría, encuentra patrones y actúa, encima de la automatización que ya tenés. No la reemplaza: la complementa.
En 30 segundos
- El problema: la automatización (IaC, CI/CD, autoscaling) resuelve la ejecución, pero no decide. Por eso siguen los outages y el alert fatigue.
- El cambio: en 2026 las empresas pasan de reglas fijas a sistemas que aprenden patrones, según Pulumi.
- El desperdicio: los clusters de Kubernetes suelen correr sobreaprovisionados. Plata tirada en CPU y memoria que nadie usa.
- Los números: la automatización ya llevó procesos de despliegue de días a minutos, y los equipos gestionan entornos mucho más grandes sin sumar gente en proporción.
- El consejo: no tires tu automatización. La inteligencia se construye encima, no en reemplazo.
¿Por qué la automatización basada en reglas ya no alcanza?
Ponele que tenés un autoscaling configurado con HPA. Sube la CPU al 80%, arranca un pod nuevo. Baja, lo apaga. Funciona. Hasta que un martes a las 3 de la mañana el problema no era la CPU sino una cola de mensajes que se tapó, y tu regla nunca miró ahí.
Ese es el techo de la automatización. Resuelve problemas de ejecución, no de decisión. Durante años el estándar fue invertir fuerte en Infrastructure as Code, pipelines de CI/CD, provisioning automático y políticas. Y dio resultado: tareas que llevaban días pasaron a minutos, el error humano bajó, la frecuencia de deploy subió. Relacionado: pipelines CI/CD automatizados.
Pero la realidad operativa de 2026 es otra. Las empresas corren sobre múltiples clouds, modelos híbridos, ecosistemas de Kubernetes y miles de servicios interconectados. Según la investigación de Pulumi sobre infraestructura cloud, los modelos operativos guiados por IA se volvieron prioridad estratégica justo por eso. Las reglas IF/THEN no escalan con la complejidad. Vos podés escribir una regla para cada falla conocida, pero las fallas nuevas no avisan.
¿Cuál es la diferencia entre infraestructura automatizada e inteligente?
La distinción es concreta y conviene tenerla clara antes de comprar cualquier plataforma “agentic” de turno. La automatización ejecuta lo que vos le dijiste. La inteligencia de infraestructura infiere lo que conviene hacer a partir de datos que cambian.
| Aspecto | Infraestructura automatizada | Infraestructura inteligente (AIOps) |
|---|---|---|
| Lógica | Reglas IF/THEN fijas | Aprende patrones de la telemetría |
| Ante un evento nuevo | No reacciona (no hay regla) | Detecta la anomalía y propone acción |
| Escalado | Por umbral (CPU, RAM) | Predictivo, según demanda real |
| Alertas | Una por cada condición | Correlaciona y prioriza la causa raíz |
| Mantenimiento | Reescribir reglas a mano | El modelo se reajusta con datos nuevos |
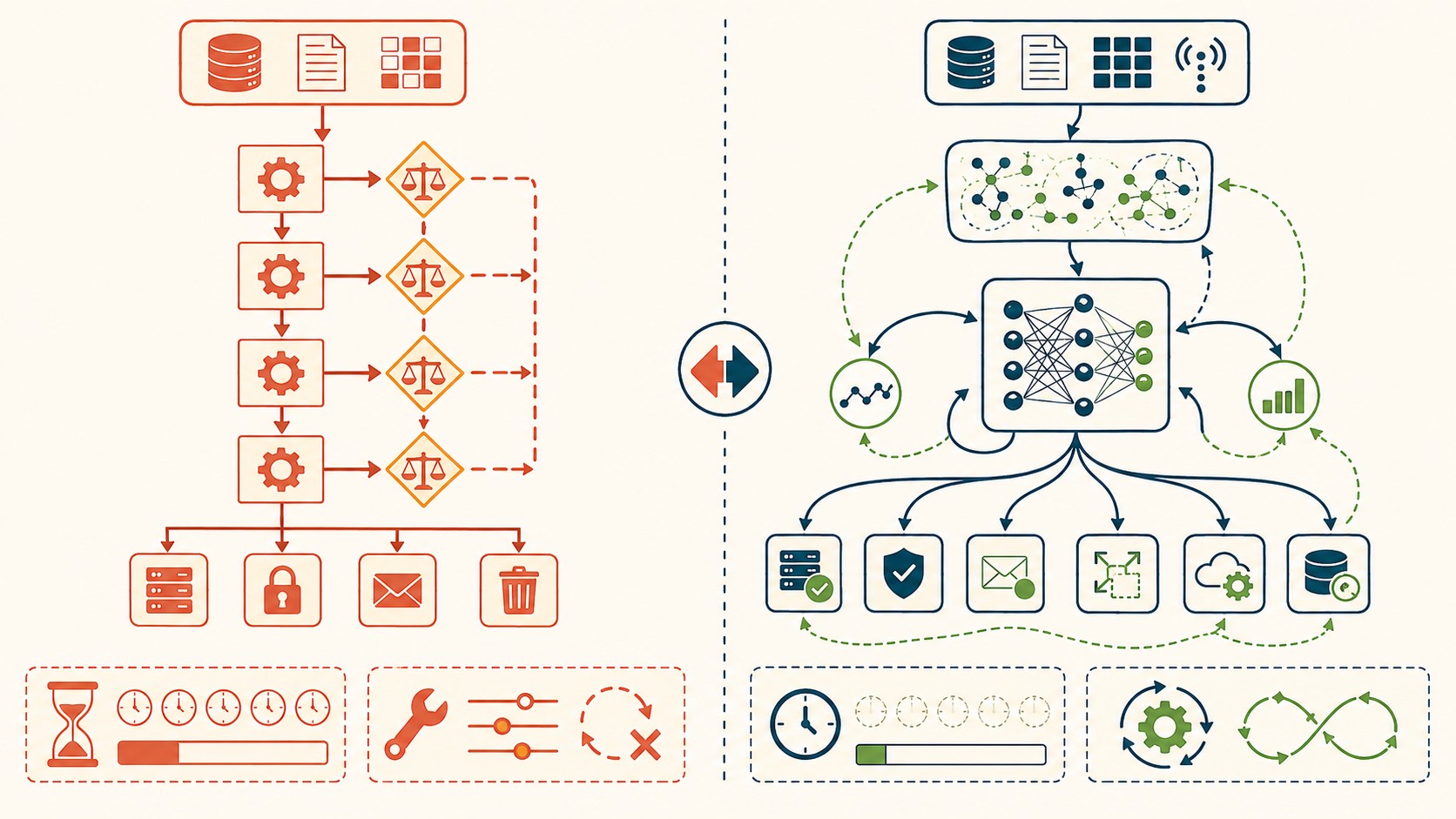
Ojo: la columna de la izquierda no desaparece. El IaC sigue siendo el cimiento. La inteligencia se apoya en esa base para decidir qué provisionar y cuándo, en vez de esperar a que un humano escriba la regla número 4.000.
¿Qué problemas reales resuelve la inteligencia de infraestructura?
Tres dolores de cabeza que cualquiera que haya estado de guardia conoce.
El ruido de alertas (alert fatigue)
- El síntoma: 200 alertas a la madrugada por un solo incidente. ¿Cuál es la que importa? Nadie sabe.
- La respuesta: los sistemas de AIOps correlacionan eventos y devuelven una causa raíz en lugar de 200 notificaciones. Menos pager a las 3 AM, más sueño para el equipo.
Los costos de cloud descontrolados
- El dato duro: los clusters de Kubernetes suelen correr sobreaprovisionados. Pedís recursos “por las dudas” y pagás de más todos los meses.
- La corrección: el análisis de patrones de uso real ajusta requests y limits sin que vos adivines. Acá es donde la factura de tu VPS o tu nube empieza a tener sentido, y si todavía estás eligiendo dónde alojar tu infraestructura, donweb.com tiene opciones de cloud en Argentina con soporte local.
La degradación de performance
- El problema: la app se pone lenta de a poco y para cuando salta el umbral, ya perdiste usuarios.
- La detección temprana: los modelos de anomalías ven la tendencia antes del límite y avisan cuando todavía hay margen para actuar.
¿Cómo funciona AIOps en la práctica?
El flujo es más simple de lo que suena. Primero recibís datos: métricas, logs, traces, eventos. Después un motor de ML analiza ese stream y busca patrones. Cuando algo se sale de lo normal, lo detecta. Y según la madurez de la plataforma, propone una acción o la ejecuta sola con guardrails. Más contexto en elegir entre Jenkins y GitHub.
Subís un servicio, todo anda bien en métricas promedio, pero el modelo nota que la latencia del percentil 99 se está arrastrando hacia arriba hora tras hora mientras el tráfico sube en una región puntual, correlaciona eso con un pool de conexiones que se está agotando y te avisa antes de que el percentil 50 siquiera se mueva. Eso es lo que una regla de umbral no te da.
Pulumi metió esto en su producto Neo, una plataforma agentic que combina IaC con decisiones automáticas. La idea no es sacar al ingeniero del medio. Es que el ingeniero defina los límites (los guardrails empresariales) y el sistema opere adentro de esa caja.
Casos reales y resultados medibles
La automatización ya demostró que procesos de provisioning que llevaban días pueden completarse en minutos. No es un ajuste cosmético: es pasar de “esperá hasta el jueves” a “lo tenés en minutos”. Tema relacionado: escalar infraestructura globalmente.
La inteligencia de infraestructura apunta a mejoras concretas sobre esa base:
- Más infraestructura gestionada por el mismo equipo, sin sumar gente en proporción.
- Despliegues más rápidos.
- Menos violaciones de política, porque los guardrails se aplican antes de que el cambio llegue a producción.
Tomalo con pinzas igual: buena parte de estas mejoras las reportan los propios fabricantes y todavía falta verificación independiente a gran escala. Pero la dirección es clara y coincide con lo que reporta el resto del sector.
¿Cómo adoptar inteligencia en tu infraestructura?
No empieces comprando la plataforma más cara. Empezá midiendo.
- Auditá lo que ya tenés: listá tus reglas de automatización actuales (HPA, alertas, políticas). Vas a encontrar reglas muertas y umbrales que nadie revisó hace dos años.
- Identificá dónde fallan las reglas: ¿qué incidentes se repiten y ninguna regla los atrapa? Ahí está tu caso de uso.
- Sumá observabilidad antes que IA: sin datos limpios (métricas, logs, traces), ningún modelo va a aprender nada útil. Garbage in, garbage out.
- Mejorá el autoscaling con ML: KEDA y HPA mejorados con señales predictivas son un buen primer paso antes de saltar a decisiones totalmente autónomas.
- Avanzá hacia decisiones sin regla: recién cuando confiás en los datos y los guardrails, dejá que el sistema actúe solo en escenarios acotados.
Errores comunes al implementar inteligencia de infraestructura
- Tirar la automatización existente. El IaC y los pipelines son la base. La inteligencia se construye encima. Arrancar de cero es perder años de trabajo por una moda.
- Conectar IA a datos sucios. Si tu telemetría está incompleta o mal etiquetada, el modelo va a “aprender” patrones falsos y a tomar peores decisiones que tu regla vieja.
- Dar autonomía total el día uno. Sin guardrails, un sistema que decide solo puede escalar costos o apagar lo que no debe. Empezá en modo sugerencia, validá, después soltá.
- Comprar la “inteligencia” como caja negra. Si no podés ver por qué el sistema tomó una decisión, no vas a poder defenderla en un postmortem. Exigí explicabilidad.
Preguntas Frecuentes
¿Cuál es la diferencia entre automatización e inteligencia en infraestructura?
La automatización ejecuta reglas fijas que vos definís (si pasa X, hacé Y). La inteligencia de infraestructura aprende patrones de la telemetría y decide acciones que nadie programó de antemano. La primera resuelve la ejecución; la segunda resuelve la decisión.
¿Cómo reduce la IA los costos de la nube?
Analiza el uso real de CPU y memoria y ajusta los recursos solicitados al consumo efectivo. Como los clusters de Kubernetes suelen correr sobreaprovisionados, el ahorro principal viene de dejar de pagar capacidad reservada que nunca se usa. Complementá con agentes inteligentes sin API.
¿Por qué siguen los outages si tengo automatización?
Porque la automatización solo reacciona a condiciones que vos anticipaste con una regla. Un evento nuevo, sin regla asociada, pasa desapercibido. La inteligencia de infraestructura detecta anomalías que no estaban previstas y por eso atrapa fallas que el autoscaling por umbral ignora.
¿Qué es AIOps?
AIOps es la aplicación de machine learning y análisis de datos a las operaciones de IT. Procesa métricas, logs y eventos, encuentra patrones y correlaciona alertas para reducir ruido y predecir fallas. Red Hat e IBM lo definen como la capa de decisión sobre la automatización existente.
¿Cómo se implementa AIOps en Kubernetes?
Se arranca con observabilidad sólida (métricas, logs y traces limpios), después se suman autoscalers mejorados con ML como KEDA o HPA con señales predictivas, y por último se delegan decisiones acotadas con guardrails. La clave es avanzar por etapas, no dar autonomía total de entrada.
Conclusión
Lo que cambió en 2026 no es que la automatización haya fallado. Es que tocó su techo. Las reglas IF/THEN resuelven la ejecución y eso ya está. El siguiente nivel es que el sistema decida, no solo que actúe.
Si gestionás infraestructura, el movimiento práctico es claro: medí dónde te fallan las reglas hoy, limpiá tu telemetría, y sumá inteligencia encima de lo que ya funciona. No de cero. La evolución de la automatización y los guardrails de plataformas como Pulumi Neo muestran hacia dónde va el sector. La pregunta no es si adoptar inteligencia de infraestructura, sino qué tan rápido podés dejar tus datos en condiciones para que valga la pena.