Un motor de venta flash que no puede vender de más
Un desarrollador construyó un motor de venta flash que no puede vender de más, ni siquiera con 1.000 compradores simultáneos, y lo hizo sobre Amazon Aurora DSQL. La clave no fue un contador más rápido: fue modelar cada unidad vendible como una fila distinta en la base de datos. Acá te explico el truco, paso a paso (sin inventar nada).
El proyecto salió publicado el 13 de junio de 2026 en un post en dev.to para el hackathon “Hack the Zero Stack”. Y aunque suene a caso de nicho, el problema que resuelve aparece en cualquier sistema de hosting, ticketing o ecommerce que necesite vender stock limitado bajo presión. Este es el clásico problema de “hosting how built”: cómo se construye algo que sea rápido a nivel global y consistente al mismo tiempo.
Aurora DSQL es la base de datos serverless, compatible con PostgreSQL y multi-región activa-activa de AWS, que detecta conflictos de escritura en el momento del commit en lugar de usar bloqueos. Sirve para cargas que necesitan consistencia fuerte y baja latencia en varias regiones a la vez, y es de Amazon Web Services. Ese detalle de “sin bloqueos” es el que cambia todo el diseño.
En 30 segundos
- Un contador único que se decrementa en cada compra colapsa bajo carga: miles de escrituras a la misma fila generan una tormenta de reintentos.
- Aurora DSQL usa control optimista de concurrencia (OCC): las transacciones corren sin locks y el conflicto se detecta al hacer commit.
- La solución ganadora: una fila por cada unidad vendible. 100 asientos = 100 filas. Cada compra reclama una al azar.
- Es multi-región activa-activa con consistencia fuerte, así que no hay ventana de replicación donde vender de más.
- La app tiene que reintentar cuando recibe un error de serialización. Esa lógica vive en tu código, no en la base.
¿Por qué un contador simple no funciona en ventas flash?
Ponele que tenés 500 entradas y una sola fila en la base que dice stock = 500. Cada compra hace UPDATE ... SET stock = stock - 1. Suena perfecto.
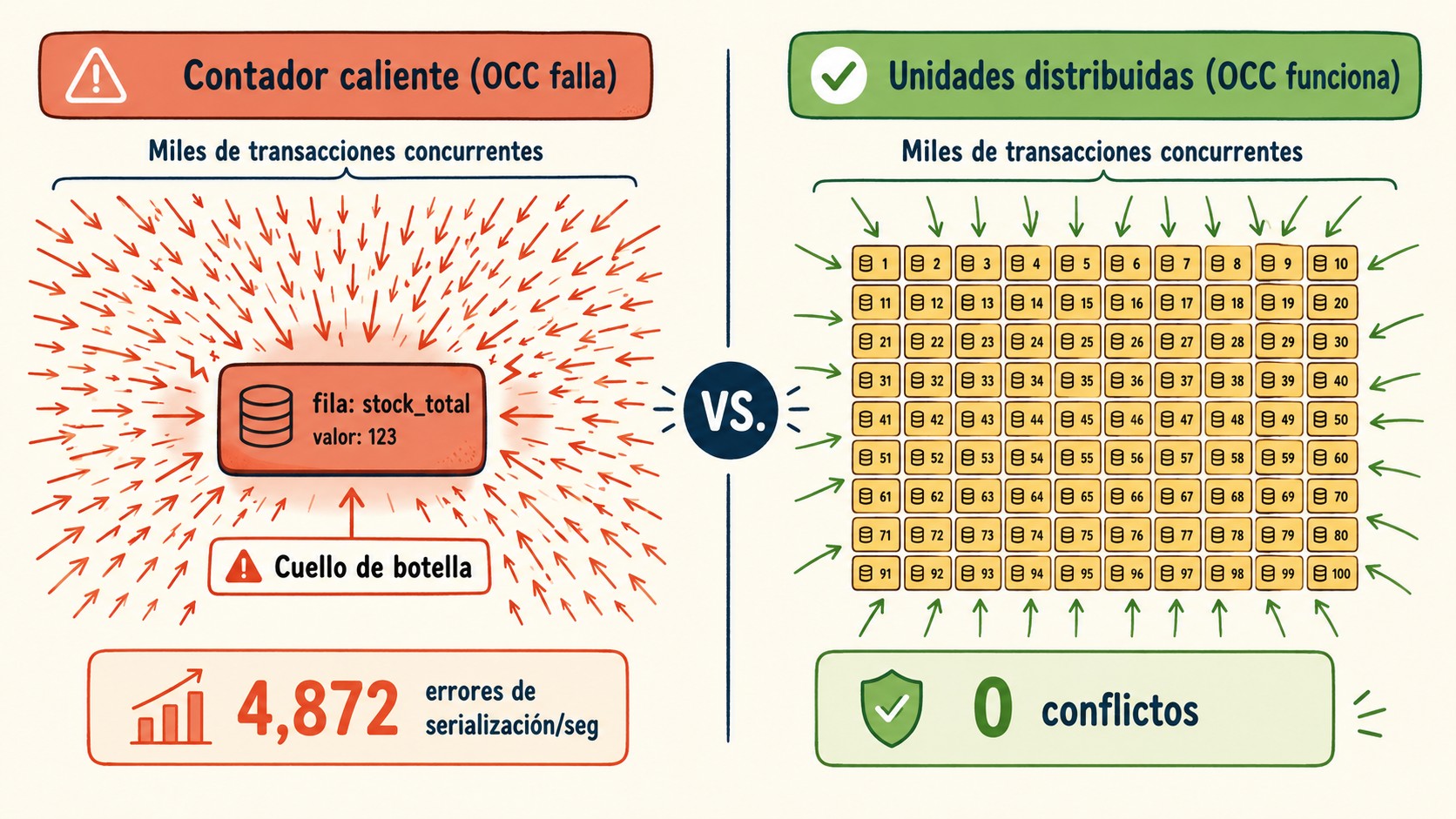
Funciona bárbaro con tráfico normal. El problema arranca cuando 10.000 personas clickean en el mismo segundo. Todas esas transacciones pelean por escribir la misma fila, y esa fila se convierte en lo que se llama un “hot counter”: un punto caliente que se transforma en cuello de botella. Te puede servir nuestra cobertura de infraestructura en la nube escalable.
¿Y qué pasa cuando lo llevás a varias regiones? Peor todavía. Con consistencia eventual, durante la ventana de replicación dos regiones pueden creer que les queda stock al mismo tiempo. Resultado: vendés de más. El autor lo dice sin vueltas en su nota: con consistencia eventual entre regiones, el overselling es casi inevitable.
¿Qué es el control optimista de concurrencia (OCC)?
El control optimista de concurrencia es un mecanismo donde las transacciones corren sin pedir bloqueos por adelantado, asumiendo que no van a chocar, y recién al hacer commit la base verifica si hubo conflicto. Si dos transacciones tocaron lo mismo, una gana y la otra recibe un error de serialización y tiene que reintentar.
Comparalo con el locking tradicional. Ahí una transacción pide el candado de la fila, las demás esperan en fila india, y nadie pisa a nadie. Es seguro pero serializa todo: bajo alta concurrencia, la cola se hace eterna.
OCC apuesta a lo contrario: que los choques son raros. Y ahí está la trampa. Un contador compartido es justo el caso donde los choques NO son raros, son la norma. Miles de escrituras a una misma clave significan miles de conflictos en commit time, y cada perdedor reintenta. Eso es una tormenta de reintentos que se come el throughput. El peor escenario posible para OCC. Complementá con hosting con máxima disponibilidad.
La trampa de Aurora DSQL: por qué AWS advierte contra los contadores compartidos
Acá viene lo bueno. La documentación oficial de Aurora DSQL sobre control de concurrencia es explícita: hay que distribuir las escrituras a lo largo del rango de claves. No concentrar todo en una sola fila.
Si ignorás eso y armás tu contador caliente, Aurora DSQL te va a devolver errores de serialización a granel. Cada compra que pierde el conflicto reintenta, vuelve a chocar, reintenta de nuevo. El sistema no se rompe, pero se arrastra. Y en una venta flash, arrastrarse es perder la venta.
La lección es contraintuitiva: la base de datos no te falla por falta de potencia, te falla porque la modelaste mal para su motor de concurrencia. El diseño “obvio” es el diseño equivocado.
La solución: modelar cada unidad vendible como una fila distinta
En lugar de un contador, una fila por unidad. Si vendés 100 asientos, tenés 100 filas, cada una con un estado: available o claimed.
Una compra reclama una unidad al azar en una sola transacción fuertemente consistente. La idea, conceptualmente, es algo así. Para más detalles técnicos, mirá arquitectura cloud con DevOps.
- Buscás una unidad libre al azar. Un
SELECTcon filtrostatus = 'available'que elige una fila aleatoria, para que dos compradores no peguen siempre a la misma. - La marcás como reclamada. Un
UPDATEque cambia el estado aclaimedy asocia el comprador. - Confirmás en una única transacción. Si nadie te ganó esa fila, commit. Si te la robaron, error de serialización y vas por otra.
¿Notás la diferencia? Ahora las escrituras están repartidas entre 100 filas en vez de apretadas en una. Las colisiones bajan muchísimo porque cada comprador, en la práctica, va por una unidad distinta. Esto es justo lo que pedía la documentación de AWS: esparcir las escrituras por el rango de claves. El repositorio de ejemplos de AWS sobre modelado de concurrencia en Aurora DSQL muestra patrones parecidos.
¿Cómo garantiza transacciones consistentes en varias regiones?
Esta es la parte donde Aurora DSQL se gana el lugar. Según el anuncio oficial de AWS, es multi-región activa-activa con consistencia fuerte. No eventual. Fuerte.
¿Por qué importa tanto? Porque una venta flash global con consistencia eventual tiene un agujero: durante la replicación entre regiones, dos data centers pueden vender el mismo asiento sin enterarse hasta segundos después. Con consistencia fuerte, ese agujero no existe. Cuando una región confirma que el asiento 47 quedó reclamado, esa verdad es global de inmediato.
Subís el inventario, lo distribuís en regiones, los compradores pegan desde tres continentes a la vez, y el sistema sigue contando bien porque ninguna transacción confirma sobre una versión vieja de los datos. Eso es lo que vuelve elegante el approach: la consistencia no es un parche que agregás vos, viene de fábrica.
Implementación práctica: reintentos y manejo de errores
Ojo con esto, porque es donde la gente tropieza. Con OCC, tu aplicación TIENE que saber reintentar.
En una base con locking, si dos transacciones chocan, la base las ordena por vos y vos casi no te enterás. Con Aurora DSQL no. Cuando tu transacción pierde el conflicto, recibís un error de serialización y sos vos quien decide qué hacer: la respuesta correcta casi siempre es reintentar, buscando otra unidad disponible. Sobre eso hablamos en pipelines de despliegue automático.
En la práctica envolvés la operación en un loop con un tope de reintentos (por ejemplo, 3 o 5 intentos) y un pequeño backoff entre cada uno. Si después de varios intentos no conseguiste unidad, probablemente ya no quede stock, y ahí sí le mostrás al usuario el clásico “agotado”. La lógica es simple, pero no es opcional: sin reintentos, tu tasa de errores se dispara apenas sube la concurrencia.
Comparación: otros enfoques para ventas flash
Aurora DSQL no es la única forma de atacar esto. Te dejo cómo se para frente a las alternativas que se usan en la industria, según los patrones que documenta System Design School.
| Enfoque | Velocidad | Consistencia global | Complejidad operativa |
|---|---|---|---|
| Contador atómico en Redis | Altísima | Limitada por región | Baja, pero replicar entre regiones es difícil |
| Cola + sala de espera (waiting room) | Media (sirve para UX) | Buena si se centraliza | Alta: hay que orquestar la cola |
| Inventory sharding manual | Alta | Buena | Alta: vos manejás los shards |
| Aurora DSQL + OCC (fila por unidad) | Alta | Fuerte, multi-región nativa | Baja: la base hace el trabajo pesado |
Redis con contadores atómicos es rapidísimo, pero te complica cuando querés varias regiones consistentes. Las colas y salas de espera son geniales para la experiencia del usuario (esa pantallita de “estás en el puesto 1.240”), pero te suman una pieza más para mantener. El sharding de inventario funciona, aunque te deja a cargo de toda la plomería. Aurora DSQL se lleva el premio a la elegancia: simple de operar, escalable y con consistencia global de serie.
Profundizamos en transacciones distribuidas en este otro artículo.
Errores comunes al armar un motor de venta flash
- Usar un contador único “porque es más fácil”. Es la trampa número uno. Bajo OCC, una sola fila caliente te genera una tormenta de reintentos. Modelá una fila por unidad desde el día cero.
- No implementar reintentos en la app. Si tu código no captura el error de serialización y vuelve a intentar, vas a rechazar compras válidas que solo necesitaban un segundo intento.
- Confiar en consistencia eventual para stock. Está bien para un feed de novedades, no para inventario. Si dos regiones cuentan distinto aunque sea por un segundo, vendiste de más.
- Olvidarte de la aleatoriedad al reclamar unidades. Si todos los compradores van siempre por la “primera fila disponible”, concentrás los choques. Elegí la unidad al azar para repartir la carga.
Preguntas Frecuentes
¿Qué es el overselling en una venta flash?
El overselling es vender más unidades de las que existen en stock. Pasa cuando varios procesos creen, al mismo tiempo, que todavía queda inventario disponible. En sistemas distribuidos con consistencia eventual es un riesgo concreto durante la ventana de replicación entre regiones.
¿Por qué un contador compartido es malo bajo OCC?
Porque el control optimista de concurrencia detecta los conflictos al hacer commit, y un contador único concentra miles de escrituras en una sola fila. Eso genera colisiones masivas y una tormenta de reintentos que hunde el throughput. La documentación de AWS recomienda distribuir las escrituras por el rango de claves.
¿Qué es Amazon Aurora DSQL?
Amazon Aurora DSQL es una base de datos serverless de AWS, compatible con PostgreSQL, multi-región activa-activa y con consistencia fuerte. Usa control optimista de concurrencia en lugar de bloqueos tradicionales. Está pensada para cargas que necesitan baja latencia global y consistencia transaccional al mismo tiempo.
¿Necesito reintentos en mi aplicación con Aurora DSQL?
Sí. Con OCC, una transacción que pierde un conflicto devuelve un error de serialización, y tu código tiene que capturarlo y reintentar. A diferencia de las bases con locking, la lógica de reintento vive en la aplicación, no en la base. Lo habitual es un loop con tope de intentos y un pequeño backoff.
¿Sirve este patrón para ecommerce y ticketing?
Sí, cualquier sistema que venda stock limitado bajo alta concurrencia se beneficia del modelo de “una fila por unidad”. Aplica a entradas para shows, drops de productos, reservas de servidores en hosting o cualquier inventario finito. El principio es el mismo: repartir las escrituras y garantizar consistencia fuerte.
Conclusión
Lo interesante de este caso no es Aurora DSQL en sí, es el cambio de cabeza que obliga a hacer. El diseño “obvio” (un contador que baja de a uno) es justo el que te explota bajo concurrencia real. La movida ganadora es modelar cada unidad como su propia fila y dejar que la base, con su consistencia fuerte multi-región, haga el laburo pesado.
Si estás construyendo algo que venda stock limitado bajo presión, quedate con tres cosas: repartí las escrituras, no confíes en consistencia eventual para inventario, y meté la lógica de reintentos en tu app desde el principio. Y si tu proyecto necesita hosting o dominios en Argentina para correr ese frontend, donweb.com te resuelve esa parte mientras vos te concentrás en la base de datos.
Fuentes
- AWS Database Blog – Anuncio oficial de Amazon Aurora DSQL
- Documentación de AWS – Control de concurrencia en Aurora DSQL
- dev.to – How I built a flash-sale engine that can’t oversell
- GitHub – Ejemplos de modelado de concurrencia en Aurora DSQL
- System Design School – Patrones de inventario para ventas flash