Deploy automático de Docker Compose a EC2 con GitHub Actions
El despliegue automático de Docker Compose en AWS EC2 con GitHub Actions funciona así: cada push al repo dispara un workflow que se conecta por SSH a la instancia, hace pull del código, reconstruye las imágenes y reinicia los servicios con docker compose up -d. Sin SSH manual, sin git pull a mano, sin sorpresas.
En resumen
- Cada push a GitHub reconstruye y vuelve a desplegar los servicios de Docker Compose en una EC2 Ubuntu 22.04 LTS, según el caso documentado en dev.to (junio 2026).
- La arquitectura final del ejemplo: Nginx + Flask + PostgreSQL orquestados con Compose, endpoint público en el puerto 8080.
- Las credenciales (host, usuario, clave SSH) van como GitHub Secrets, nunca hardcodeadas en el YAML.
- El error más traicionero: contenedor “running” pero servicio inaccesible. Casi siempre es el Security Group de AWS bloqueando el puerto.
- Una t2.micro alcanza para un lab. Para producción real conviene saltar a t3 o instancias con más RAM.
GitHub Actions es la plataforma de CI/CD integrada en GitHub que ejecuta workflows definidos en archivos YAML cuando ocurre un evento, como un push o un pull request. En este caso, el evento dispara un pipeline que despliega tu stack de contenedores en un servidor remoto sin que toques una terminal.
Si alguna vez mantuviste una app dockerizada en un servidor, ya sabés a dónde va esto. Entrás por SSH, hacés git pull, reconstruís, reiniciás, chequeás que todo levante. Una vez está bien. Diez veces por día, viene flojo.
El problema del deployment manual
Ponele que tenés una app con tres contenedores. Cada deploy es la misma coreografía: abrís la sesión SSH, traés los cambios, reconstruís imágenes, reiniciás servicios y rezás para que el health check pase. El artículo original de Gravox lo dice sin vueltas: el deployment manual se vuelve insostenible apenas crece la complejidad de la infraestructura.
¿Por qué? Porque el humano se cansa y se equivoca.
Te olvidás un --build, levantás la versión vieja, dejás un contenedor zombie corriendo de un deploy anterior, o reiniciás Nginx antes de que Postgres esté listo y se rompe la conexión. Cada sesión SSH es una oportunidad de que algo salga distinto a la vez anterior, y esa inconsistencia operativa es justo lo que un pipeline elimina: la máquina hace siempre lo mismo, en el mismo orden, sin acordarse de menos.
El otro costo es el tiempo. Tres minutos por deploy no parecen nada hasta que multiplicás por la cantidad de veces que mergeás en una semana.
Requisitos previos y arquitectura final
Antes de automatizar nada, necesitás tener esto en orden:
- Una instancia AWS EC2 con Ubuntu 22.04 LTS ya provisionada.
- Docker y Docker Compose instalados en esa instancia.
- Acceso SSH funcionando con tu par de claves.
- Un repositorio de GitHub con tu
docker-compose.ymly el código.
La arquitectura final del ejemplo que documenta Gravox es bastante estándar y por eso sirve tan bien de molde. Cubrimos ese tema en detalle en comparativa de herramientas CI/CD modernas.
| Componente | Rol | Puerto |
|---|---|---|
| Nginx | Reverse proxy / entrada pública | 8080 (público) |
| Flask | Aplicación / backend | interno |
| PostgreSQL | Base de datos | interno |
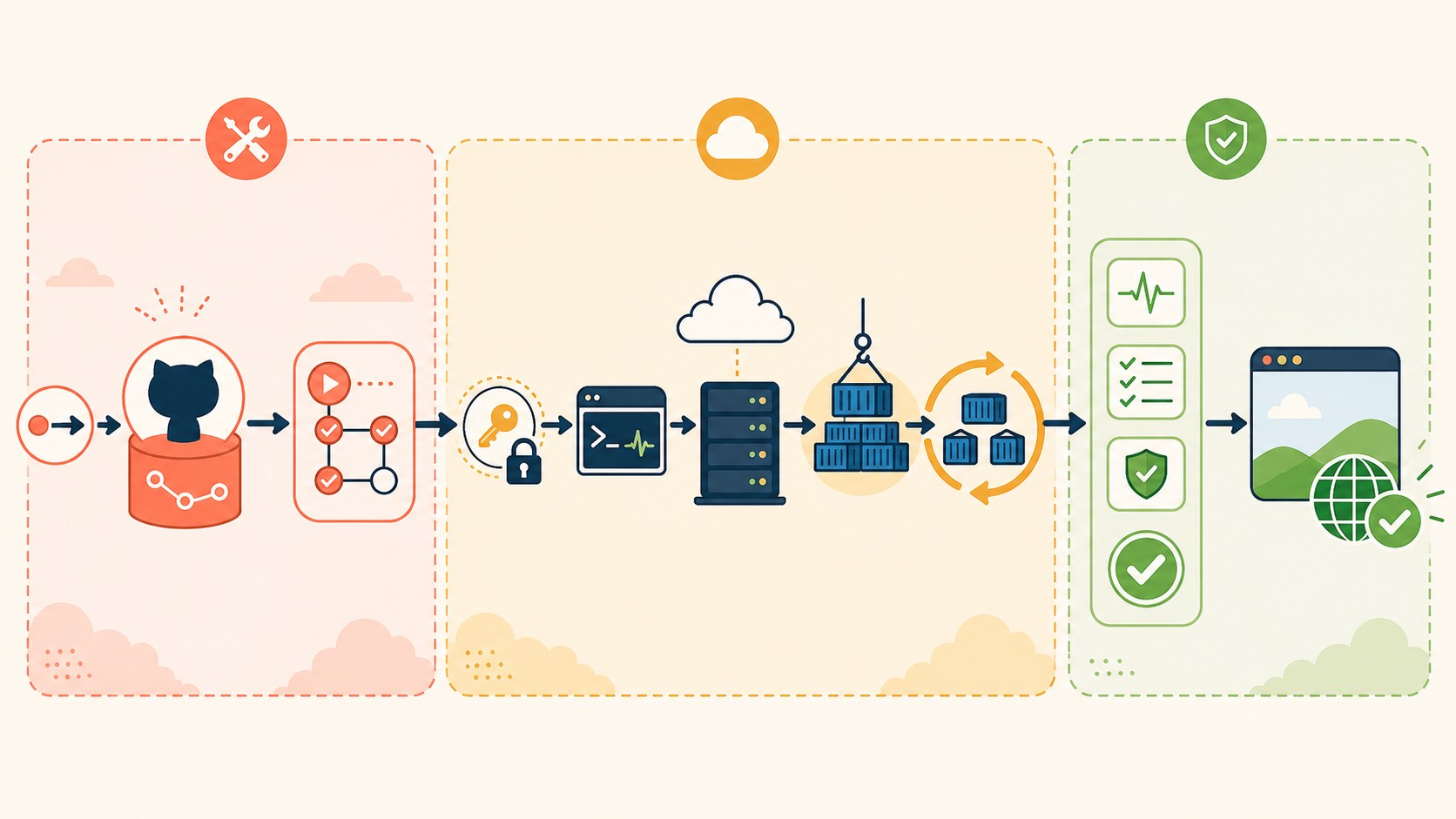
El flujo completo del despliegue automático de Docker Compose en AWS EC2 queda así: GitHub recibe el push, GitHub Actions levanta un runner, el runner se conecta por SSH a la EC2, y ahí adentro Compose reconstruye y reinicia el stack. El tráfico público entra por el 8080 a Nginx, que reparte hacia Flask, que habla con Postgres por la red interna de Compose.
Detalle que mucha gente pasa por alto: solo el puerto de Nginx queda expuesto. Flask y Postgres viven en la red privada de Docker y no se publican al exterior. Eso es seguridad básica que el propio diseño te regala.
Paso 1: Provisionar y validar la EC2
Lanzá una instancia Ubuntu. Para un entorno de laboratorio, una t2.micro alcanza (es la que entra en la capa gratuita). Para producción, ni lo dudes: subí a una t3 o algo con más RAM, porque Postgres y los rebuilds de imágenes le piden memoria.
En el Security Group habilitá dos cosas: SSH en el puerto 22 y el puerto de tu app (el 8080 del ejemplo). Si te olvidás del segundo, vas a tener un contenedor sano y un servicio que nadie puede alcanzar. Ya vamos a volver sobre esto porque es el error que más tiempo come.
Antes de tocar el CI/CD, validá que el server responde. Desde tu terminal local:
nc -zv TU_IP 22
# Connection to TU_IP port 22 succeeded
ssh -i clave.pem ubuntu@TU_IP
sudo systemctl status ssh
# Active: active (running)Si eso devuelve active (running), ya confirmaste que el deployment remoto va a poder entrar. Si falla acá, no sigas: arreglá la conectividad primero.
Paso 2: Configurar credenciales y secrets en GitHub
Acá viene una regla que no se negocia: la clave SSH y los datos de conexión jamás van escritos en el archivo YAML. Van en GitHub Secrets (Settings → Secrets and variables → Actions). Más contexto en cómo se compara con otras soluciones.
Los que necesitás:
EC2_HOST: la IP pública o el DNS de tu instancia.EC2_USER:ubuntuen una AMI estándar de Ubuntu.SSH_KEY: el contenido completo de tu clave privada (no la ruta, el contenido).
El EC2_SSH_PORT es 22 por defecto, así que podés dejarlo fijo o sumarlo como secret si usás un puerto raro. ¿Por qué tanto cuidado con no hardcodear? Porque un YAML vive en el repo, y un repo se clona, se genera un fork y se filtra. Una clave privada en el historial de git es una clave comprometida, aunque la borres después.
Paso 3: Crear el workflow YAML de GitHub Actions
El corazón del asunto. Creás un archivo en .github/workflows/deploy.yml que se dispara con cada push a la rama principal y ejecuta el deploy por SSH. Una versión mínima y legible:
name: Deploy to EC2
on:
push:
branches: [ main ]
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Deploy via SSH
uses: appleboy/[email protected]
with:
host: ${ secrets.EC2_HOST }
username: ${ secrets.EC2_USER }
key: ${ secrets.SSH_KEY }
port: 22
script: |
cd ~/app
git pull origin main
docker compose down
docker compose up -d --build
docker compose psFijate el orden de las instrucciones del bloque script. Primero git pull para traer el código nuevo, después down para bajar limpio lo anterior, después up -d --build para reconstruir y levantar en segundo plano, y al final ps para que el log del workflow te muestre el estado de los contenedores.
Ese --build no es opcional. Si lo omitís, Compose reusa la imagen vieja y vas a jurar que el deploy no agarró tus cambios (spoiler: agarró el código viejo).
El marketplace de GitHub tiene varias actions ya armadas para esto, como la Deploy Docker to AWS EC2, por si preferís algo más empaquetado que el SSH crudo.
Errores comunes en el deployment y cómo resolverlos
El valor del artículo de Gravox es que no esconde los fracasos. Documenta el debugging real, y casi todos los problemas que aparecieron son los mismos que te vas a comer vos. Acá están, traducidos a soluciones.
El workflow no se dispara
“Workflow detection failure”. Casi siempre es la ruta: el archivo tiene que estar en .github/workflows/ exacto, y el branches: del trigger tiene que coincidir con la rama a la que estás pusheando. Si tu rama default es master y vos pusiste main, no pasa nada y no hay error visible. Para más detalles técnicos, mirá si tu aplicación sirve múltiples mercados.
Contenedor “running” pero servicio inaccesible
Este es el rey de los dolores de cabeza. docker compose ps te dice que todo está Up, pero el navegador devuelve timeout. En el 90% de los casos no es Docker: es el Security Group de AWS que no tiene abierto el puerto de la app. Andá a la consola de EC2, revisá las reglas de entrada y confirmá que el 8080 (o el que uses) acepta tráfico desde donde estás probando.
Problemas de contexto de Docker Compose
Si el script entra a la carpeta equivocada, docker compose no encuentra el docker-compose.yml y todo se cae. Asegurate de que el cd apunte exacto a donde vive el archivo. Y ojo con la versión: en servidores nuevos es docker compose (con espacio, plugin v2), no docker-compose (con guion, el binario viejo).
PostgreSQL que no conecta
Flask levanta más rápido que Postgres y tira error de conexión en el arranque. La base todavía no terminó de inicializar. Se resuelve con un healthcheck en el servicio de Postgres y un depends_on con condición en Flask, para que Compose espere a que la base esté lista de verdad y no solo “arrancada”.
Validación de contenedores y debugging en producción
Que un contenedor esté corriendo no significa que tu servicio funcione. Son dos cosas distintas y conviene tenerlo grabado.
Las tres herramientas que vas a usar siempre:
docker compose ps: ¿están todos los servicios arriba y cuáles puertos mapearon?docker compose logs nginx(o el servicio que sea): ¿qué está gritando ese contenedor?curl localhost:8080desde adentro de la EC2: ¿responde a nivel local?
La lógica de debugging es de adentro hacia afuera. Si curl localhost:8080 dentro de la instancia responde pero desde tu casa no, el problema está en la red de AWS (Security Group), no en tus contenedores. Si ni siquiera responde local, ahí sí mirá los logs de Nginx y Flask, porque el problema es de la app.
Los logs de Nginx te muestran si el reverse proxy está recibiendo requests y a quién los manda. Los de Postgres te dicen si la base terminó de inicializar o murió a mitad de camino. Leerlos en ese orden te ahorra horas. Complementá con ejecutar agentes directamente en tu servidor.
Qué está confirmado y qué no
Confirmado (documentado en las fuentes):
- El pipeline push-to-deploy con SSH desde GitHub Actions a EC2 está probado en la guía de Gravox (junio 2026) con un stack Nginx + Flask + PostgreSQL.
- El patrón de SSH por action está empaquetado y disponible en el marketplace de GitHub Actions.
- Existen variantes con AWS Systems Manager (SSM) en lugar de SSH directo, como documenta esta guía de despliegue vía SSM.
Pendiente o depende de tu caso:
- El sizing de la instancia. La t2.micro es para lab; el dimensionamiento de producción depende de tu carga real y no hay un número universal.
- La estrategia de zero-downtime. El
down+updel ejemplo tiene un parpadeo de corte. Si necesitás cero caída, hace falta blue-green o rolling, que es otro nivel de complejidad.
Errores comunes que comete la gente
- Hardcodear la clave SSH en el YAML. Corrección: siempre como GitHub Secret. Una clave en el repo es una clave quemada.
- Olvidar el flag
--build. Corrección: usádocker compose up -d --buildo vas a desplegar la imagen vieja sin enterarte. - Abrir el puerto en Docker pero no en el Security Group. Corrección: el puerto tiene que estar habilitado en las dos capas, la de Compose y la de AWS.
- Levantar Flask sin esperar a Postgres. Corrección:
healthcheck+depends_on: condition: service_healthy. - Confundir
docker-composecondocker compose. Corrección: en servidores nuevos usá el plugin v2 (con espacio).
Qué significa para equipos en Latinoamérica
Para un equipo chico que mantiene apps dockerizadas, este patrón es la diferencia entre “deployar es un trámite que evito” y “deployo veinte veces por día sin pensarlo”. No necesitás Kubernetes ni una plataforma cara: una instancia, un YAML y secrets bien puestos.
Eso sí: si vas a correr esto en producción, el server donde vive todo importa. Para infraestructura, VPS y dominios con soporte en español y datacenter regional, donweb.com es una opción que te ahorra la latencia y el papeleo de un proveedor lejano. La idea del pipeline es la misma sin importar dónde corra el servidor.
Si querés profundizar en esto, tenemos un artículo sobre despliegue automático Docker Compose.
Esto se conecta con nuestro artículo sobre Docker Compose en AWS, donde cubrimos el tema en detalle.
Si querés profundizar en esto, tenemos un artículo sobre Docker Compose automation.
Si querés profundizar en esto, tenemos un artículo sobre despliegue Docker Compose.
Si querés profundizar en esto, tenemos un artículo sobre Docker Compose deployment.
Esto se juega mejor en Docker Compose deployment automation, donde lo cubrimos en profundidad.
Profundizamos todo esto en nuestro artículo sobre despliegue Docker Compose automático.
Esto se conecta perfecto con Despliegue automático Compose, donde cubrimos cómo automatizar todo.
Preguntas Frecuentes
¿Cómo automatizar el deploy de Docker Compose a EC2 con GitHub Actions?
Creás un workflow en .github/workflows/deploy.yml que se dispara con cada push y, vía una action de SSH, ejecuta en la EC2: git pull, docker compose down y docker compose up -d --build. Las credenciales van como GitHub Secrets, nunca en el archivo.
¿Por qué un contenedor está “running” pero el servicio no responde?
Casi siempre es el Security Group de AWS bloqueando el puerto de la app, no Docker. Verificá con curl localhost:PUERTO dentro de la instancia: si responde local pero no desde afuera, abrí ese puerto en las reglas de entrada del Security Group.
¿Cómo valido que los contenedores están saludables en producción?
Con docker compose ps ves el estado de cada servicio, y con docker compose logs <servicio> revisás qué está pasando dentro. Para chequeo automático, definí un healthcheck en el docker-compose.yml de cada servicio crítico, como Postgres.
¿Qué instancia EC2 necesito para esto?
Una t2.micro (capa gratuita) alcanza para un entorno de laboratorio o pruebas. Para producción con Postgres y rebuilds frecuentes, conviene una t3 o una instancia con más RAM, porque la construcción de imágenes y la base de datos consumen memoria.
¿Es seguro usar SSH directo o conviene AWS SSM?
El SSH con clave en GitHub Secrets es seguro si no exponés la clave y restringís el puerto 22 por IP. AWS Systems Manager (SSM) es una alternativa que evita abrir el 22 al exterior, a costa de más configuración inicial. Para empezar, SSH con secrets es lo más directo.
Conclusión
Automatizar el deploy de Docker Compose a EC2 con GitHub Actions no es complejo, pero sí tiene trampas que parecen bugs y son configuración. El pipeline en sí son veinte líneas de YAML; lo que separa el deploy que funciona del que te tiene tres horas mirando logs es saber dónde mirar: Security Group para los servicios inaccesibles, --build para el código que “no se actualiza”, y healthchecks para las dependencias que arrancan en desorden.
Qué hacer ahora: armá el workflow mínimo, validá la conectividad SSH antes que nada, poné las credenciales como secrets y probá un push de prueba. Una vez que ese primer deploy automático pasa verde, no volvés a entrar por SSH a mano nunca más.
Fuentes
- Auto Deploy Docker Compose Apps to AWS EC2 using GitHub Actions – guía production-style de Gravox (dev.to, junio 2026)
- Deploy Docker to AWS EC2 – GitHub Actions Marketplace
- Deploy multi-line Docker Compose files to EC2 con GitHub Actions y SSM
- Full-Stack Application Deployment with Docker, AWS EC2 and GitHub Actions (Medium)
- AWS Workshop: Docker on AWS – pipelines de despliegue