Liveness vs Readiness en Kubernetes: no los confundas
Los probes de liveness y readiness en Kubernetes no son un detalle de configuración menor: son la diferencia entre un sistema que se recupera solo y uno que te despierta a las 3 de la mañana porque entró en restart loop. Liveness determina si el contenedor debe reiniciarse; readiness determina si ese pod debe recibir tráfico. Un minuto de indisponibilidad en un servicio de alta carga equivale a miles de requests perdidos, y en sistemas de auditoría o finanzas, esos requests no se recuperan.
En 30 segundos
- Liveness probe decide si Kubernetes reinicia el contenedor. Readiness probe decide si el pod recibe tráfico. Hacen cosas distintas y no son intercambiables.
- Nunca pongas chequeos de dependencias externas (Kafka, Redis, base de datos) en el liveness probe: si la BD cae, todos tus pods entran en restart loop sobre la outage original.
- Un
initialDelaySecondsdemasiado corto es la causa más común de restart loops en startup: si tu app tarda 30 segundos en levantar y le das 5, Kubernetes la mata antes de que arranque. - Respuestas HTTP de probe mayores a 10 KiB hacen que kubelet cierre la conexión y lo cuente como fallo, aunque el servicio esté sano.
- Readiness failure es reversible: el pod vuelve al pool de endpoints en cuanto la dependencia se recupera. Liveness failure reinicia el pod, que es una operación distinta y más costosa.
Por qué los dos probes son necesarios: Liveness vs Readiness
Un liveness probe es la respuesta a “¿este contenedor puede hacer progreso?” Si el proceso está bloqueado, en deadlock, o en un estado del que no puede salir solo, Kubernetes lo reinicia. Un readiness probe determina algo diferente: “¿este pod está en condiciones de recibir tráfico ahora mismo?” Si la respuesta es no, el pod sale del set de endpoints del Service, pero no se reinicia.
La analogía que me convence: liveness es saber si el conductor está consciente. Readiness es saber si está capacitado para manejar en este momento. Un conductor puede estar consciente pero tener el auto con la rueda pinchada (no listo para el tráfico). O puede estar completamente dormido (necesita que alguien lo “reinicie”).
Según el análisis publicado en mayo de 2026, en servicios sensibles a pérdida de datos como audit trails, sistemas de logging y servicios financieros, un minuto de indisponibilidad no es un fallo temporal: es pérdida permanente de datos. Los requests no se reintentan, las escrituras no llegan. Eso es lo que hace que la configuración correcta de probes pase de ser “detalle de deployment” a parte de la estrategia de confiabilidad.
Cómo afectan las dependencias (Kafka, Redis, OpenSearch) al diseño de probes
Acá viene lo bueno, y también donde la mayoría la embarra.
La regla es clara: nunca incluyas dependencias externas en el liveness probe. Nunca. Si tu liveness hace un chequeo de conectividad a Kafka y el broker tiene un problema transitorio, lo que pasa es esto: la base de datos o el broker cae, tu liveness probe falla, Kubernetes reinicia el pod, el pod vuelve a arrancar, vuelve a fallar el liveness porque la dependencia sigue caída, y reinicia de nuevo. Entraste en restart loop encima de la outage original. Duplicaste el problema.
Las dependencias externas van en el readiness probe. El flujo correcto es: Redis cae → readiness probe falla → el pod sale de los endpoints → deja de recibir tráfico → cuando Redis vuelve, el readiness probe pasa → el pod vuelve al pool. El servicio degradó, pero se recuperó solo sin que nadie tuviera que intervenir manualmente. Más contexto en automatizar deployments con CI/CD.
Ejemplos concretos de qué va dónde:
- Liveness: chequeo interno de deadlock, estado del loop principal de la aplicación, disponibilidad del puerto local
- Readiness: conectividad a Kafka broker, disponibilidad de Redis, estado del cluster de OpenSearch, conexión a base de datos
¿Alguien puede justificar poner la base de datos en el liveness? Difícilmente. El pod no “está muerto” porque la BD esté caída, simplemente no puede servir tráfico en ese momento.
Readiness failures vs liveness failures: impacto y recuperación
El readiness probe corre durante todo el ciclo de vida del pod, no solo en el arranque. Eso es importante porque el estado de un pod puede cambiar: una dependencia que estaba bien a las 10am puede caerse a las 2pm.
| Situación | Readiness Failure | Liveness Failure |
|---|---|---|
| ¿Qué hace Kubernetes? | Saca el pod de los endpoints del Service | Reinicia el contenedor |
| ¿El pod sigue corriendo? | Sí | No (se reinicia) |
| ¿Es reversible automáticamente? | Sí, cuando el probe vuelve a pasar | Depende de si el reinicio resuelve el problema |
| ¿Cuándo usar? | Dependencia externa caída, carga alta, startup | Deadlock, corrupción de estado, proceso colgado |
| ¿Impacto en tráfico? | Pod deja de recibir requests nuevos | Pod se reinicia, hay downtime del pod |
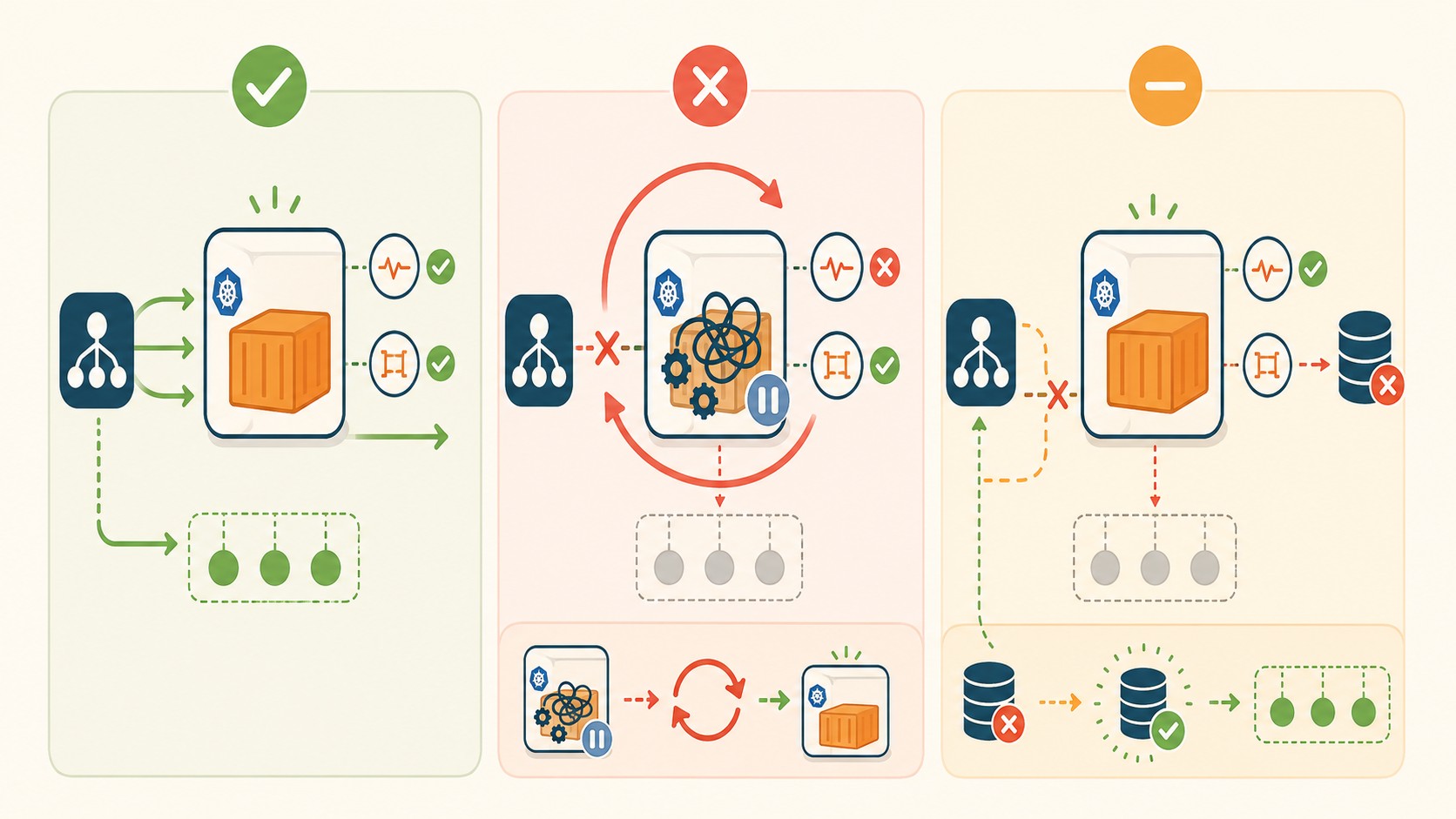
La reversibilidad del readiness failure es lo que lo hace valioso. El pod sigue consumiendo recursos, mantiene sus conexiones, y en cuanto la dependencia vuelve, Kubernetes lo reincorpora al pool sin que nadie haga nada.
Parámetros críticos: frequency, timeout y thresholds
Ponele que tu app tarda 45 segundos en inicializar, y configuraste initialDelaySeconds: 10. Lo que va a pasar es que el liveness probe va a fallar antes de que la app arranque, Kubernetes va a reiniciar el pod, y vas a estar en ese loop hasta que alguien lo note. O hasta que el CrashLoopBackOff te llame la atención en los logs.
Los parámetros que tenés que ajustar con cabeza:
- initialDelaySeconds: tiene que ser mayor que el peor caso de startup de tu app. Si en producción tarda hasta 40 segundos, poné 50. No seas mezquino acá.
- timeoutSeconds: tiene que superar la latencia máxima esperada de tus dependencias. Si Redis puede tardar hasta 3 segundos bajo carga, poné al menos 5.
- failureThreshold * periodSeconds: el producto de estos dos valores es el tiempo total que Kubernetes va a esperar antes de considerar el probe fallido definitivamente. Tiene que cubrir el peor caso de startup.
- periodSeconds: cada cuánto corre el probe. Para readiness en un servicio de alta carga, 10 segundos suele ser un buen balance.
Valores de referencia razonables para readiness en una app REST típica: initialDelaySeconds: 15, timeoutSeconds: 5, periodSeconds: 10, failureThreshold: 3. Esto da 15 segundos de gracia al inicio y 30 segundos de margen antes de sacar el pod del pool. Lo explicamos a fondo en disponibilidad en múltiples regiones.
Errores comunes que generan restarts agresivos
Estos son los errores que aparecen una y otra vez, sin importar el tamaño del equipo:
1. Liveness probe con chequeo de dependencias externas. Ya lo cubrimos, pero merece repetición: es el error más frecuente y el más destructivo. Causa restart loops encima de outages.
2. initialDelaySeconds demasiado corto. El pod entra en CrashLoopBackOff en el arranque, el equipo no entiende por qué, y perdés 30 minutos antes de darte cuenta que la app necesitaba más tiempo para inicializar.
3. Respuestas HTTP mayores a 10 KiB. Esto es menos conocido: según la documentación oficial de Kubernetes, kubelet cierra la conexión si la respuesta supera 10 KiB y lo cuenta como fallo del probe. Si tu endpoint de health devuelve mucha información de diagnóstico, puede estar matando pods que están perfectamente sanos.
4. Rutas o puertos incorrectos en el HTTP probe. El pod está sano, pero el probe apunta a /health y el endpoint real es /healthz. O el puerto está mal. Kubernetes lo trata como fallo. Básico, pero pasa.
5. No diferenciar startup probe de readiness probe. El startup probe existe justamente para aplicaciones que tienen un startup largo. Mientras el startup probe no pase, Kubernetes no evalúa liveness ni readiness. Usarlo correctamente evita tener que poner initialDelaySeconds enormes en liveness. Tema relacionado: alternativas a Kubernetes para proyectos pequeños.
Implementación práctica: ejemplos de configuración
Un ejemplo concreto de cómo se ve una configuración correcta para una app REST con base de datos:
livenessProbe:
httpGet:
path: /livez
port: 8080
initialDelaySeconds: 30
periodSeconds: 15
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /readyz
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3El endpoint /livez solo chequea el estado interno de la app (que el proceso esté respondiendo, que no haya deadlock). El endpoint /readyz chequea que la conexión a la base de datos esté disponible, que las colas estén accesibles, todo lo que necesita para servir tráfico.
Para servicios que se conectan a Kafka, un TCP probe puede ser suficiente para el readiness si no querés implementar un endpoint HTTP:
readinessProbe:
tcpSocket:
port: 9092
initialDelaySeconds: 10
periodSeconds: 10Ojo: esto solo verifica que el puerto esté abierto, no que Kafka esté procesando mensajes. Para sistemas donde necesitás esa garantía, la recomendación para Kafka Streams es implementar un endpoint HTTP que verifique el estado del KafkaStreams internamente.
Pérdida de datos en sistemas sensibles: lo que se juega realmente
Hay una diferencia entre un servicio de e-commerce que pierde un request de listado de productos y un sistema de auditoría que pierde una escritura. En el primer caso, el usuario recarga la página. En el segundo, ese evento no vuelve.
Los sistemas que no pueden permitirse perder requests (audit trails, servicios financieros, pipelines de logging) necesitan que los probes estén configurados con un margen conservador. Más vale que el readiness probe tarde 10 segundos más en recuperarse que hacer un restart innecesario que interrumpa in-flight requests. Complementá con health checks en arquitecturas serverless.
Una configuración demasiado agresiva (timeouts cortos, failureThreshold bajo) en estos sistemas es peor que no tener probes, porque te da una falsa sensación de confiabilidad mientras genera turbulencia innecesaria en momentos de carga alta.
Preguntas Frecuentes
¿Cuál es la diferencia entre un liveness probe y un readiness probe?
Liveness probe determina si Kubernetes debe reiniciar el contenedor: falla cuando el proceso está bloqueado o en deadlock. Readiness probe determina si el pod debe recibir tráfico: falla cuando el servicio está vivo pero no puede responder correctamente, por ejemplo porque una dependencia externa está caída. Son preguntas distintas y requieren configuraciones distintas.
¿Cuándo falla un readiness probe en Kubernetes y qué hace el cluster?
El readiness probe falla cuando el endpoint configurado devuelve un código HTTP fuera del rango 200-399, cuando se supera el timeout, o cuando la conexión TCP no se establece. Cuando falla, Kubernetes saca el pod del set de endpoints del Service: no le manda tráfico nuevo, pero no lo reinicia. El pod vuelve automáticamente al pool cuando el probe vuelve a pasar.
¿Cómo configurar correctamente los probes para evitar restart loops?
Tres ajustes clave: primero, poné initialDelaySeconds mayor que el peor tiempo de startup de tu app. Segundo, nunca incluyas dependencias externas en el liveness probe. Tercero, usá startupProbe para aplicaciones con startup largo, así no tenés que poner valores exagerados en liveness. Si ya estás en restart loop, revisá los logs del probe con kubectl describe pod para ver exactamente qué está fallando.
¿Debo revisar dependencias externas en el liveness probe?
No. Las dependencias externas (base de datos, Redis, Kafka, APIs de terceros) nunca van en el liveness probe. Si las ponés ahí y la dependencia cae, Kubernetes va a reiniciar tu pod repetidamente mientras la dependencia siga caída, generando un restart loop sobre la outage original. Las dependencias externas van en el readiness probe, que solo saca el pod del pool de tráfico sin reiniciarlo.
¿Qué sucede si mis probes tienen timeouts demasiado cortos?
Si el timeout es más corto que la latencia real de la dependencia que estás chequeando, el probe va a fallar aunque el servicio esté funcionando correctamente. Bajo carga alta, las latencias suben, y un timeout ajustado para condiciones normales puede empezar a fallar justo cuando más necesitás que el sistema sea estable. El timeout debería ser al menos el doble de la latencia máxima esperada de las dependencias chequeadas.
Conclusión
Los probes Kubernetes liveness readiness son uno de esos temas donde la configuración incorrecta no se nota hasta que hay un incidente en producción. La distinción fundamental es simple: liveness para el proceso en sí, readiness para el servicio incluyendo sus dependencias.
Si tenés que llevarte una sola regla: las dependencias externas van en readiness, nunca en liveness. Eso solo te va a ahorrar la clase de incidente donde la BD cae por 2 minutos y tus pods siguen reiniciándose 20 minutos después de que la BD volvió.
Lo demás es calibración: initialDelaySeconds conservador, timeout mayor que la latencia máxima esperada, y endpoints de health bien separados (/livez para el estado interno, /readyz para la capacidad de servir tráfico). Si tu infraestructura corre en la nube, servicios como los que ofrece donweb.com para cloud y hosting gestionado ya tienen health checks configurados por defecto, pero en Kubernetes propio estas decisiones son tuyas.
Fuentes
- Sagar Trimukhe – Why livez and readyz Matter for Kubernetes Health Probes (2026)
- Kubernetes Docs – Liveness, Readiness and Startup Probes
- Kubernetes Docs – Configure Liveness, Readiness and Startup Probes
- Colin Breck – Kubernetes Probes: How to Avoid Shooting Yourself in the Foot
- CubeAPM – Kubernetes Readiness Probe Failed Error