Tar pits: la nueva defensa contra scrapers de IA
¿Estás cansado de que los crawlers de IA te coman el ancho de banda y bloquearlos no sirva de nada? La defensa contra scrapers de IA cambió de estrategia: en vez de devolver un 403, ahora se los atrapa en un laberinto infinito de páginas falsas con herramientas como Nepenthes y AI Labyrinth de Cloudflare.
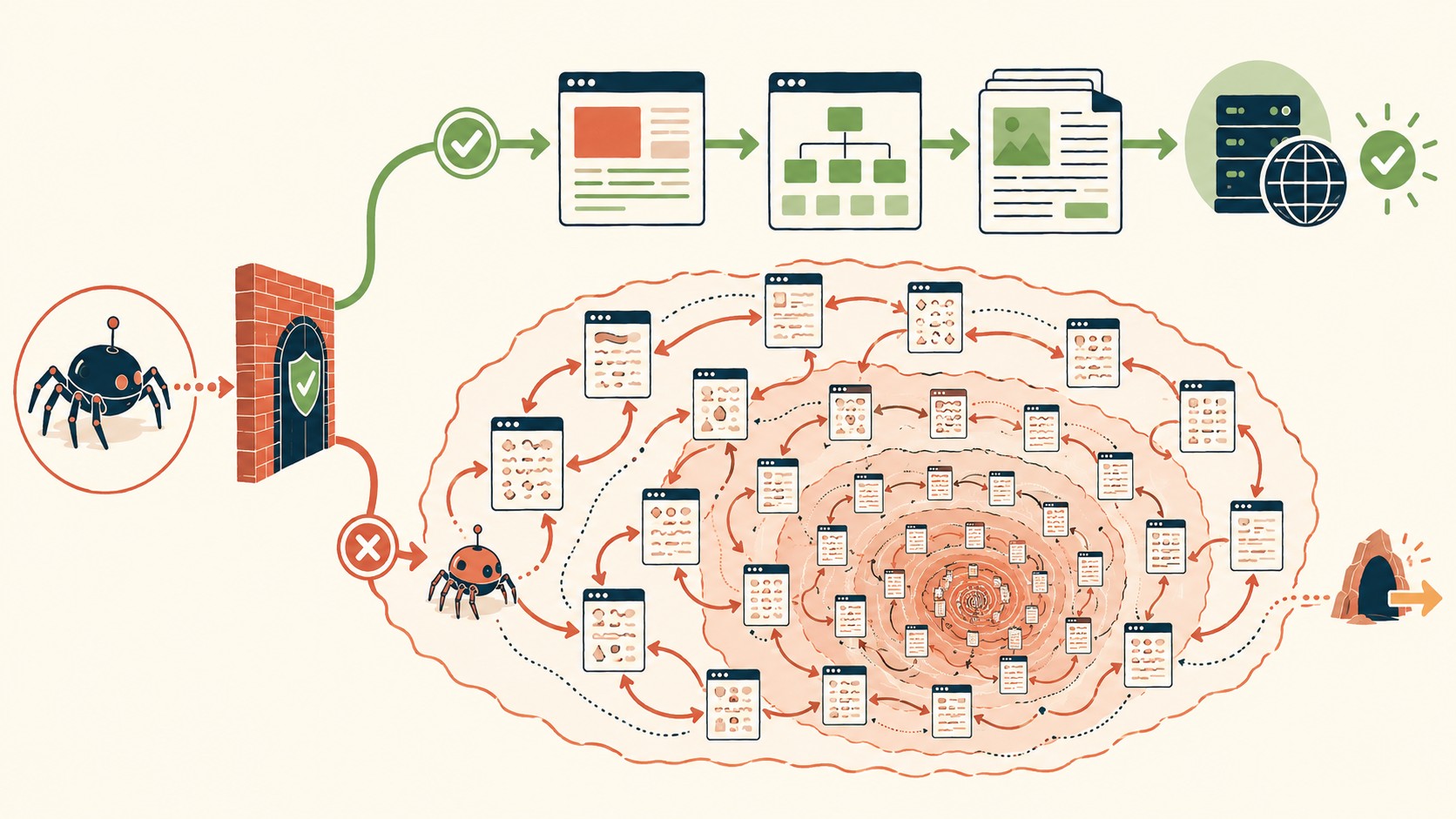
Un tar pit web es un servidor que le dice “sí” a cada bot, le sirve páginas generadas al azar y las rellena con decenas de enlaces que vuelven al mismo pozo. El crawler los persigue sin parar porque no tiene criterio ni condición de salida. Es una trampa pasiva pensada para agotar al scraper, no para frenarlo en seco.
En 30 segundos
- El bloqueo simple no alcanza: un 403 le enseña al scraper qué lo trabó, y vuelve rotando IP, user-agent y proxy residencial.
- Nepenthes es la opción autohospedada: código abierto, gratis, sirve páginas deterministas con ~40 enlaces circulares cada una.
- AI Labyrinth es la opción gestionada: Cloudflare la incluye sin costo y usa enlaces ocultos con nofollow, sin riesgo de SEO.
- El volumen de crawlers de IA explotó: se comen el ancho de banda de cualquier sitio, y por eso bloquear dejó de alcanzar.
- Ojo con Google: mal configurado, un tar pit puede sacarte del índice. Bien hecho, no.
¿Qué es un tar pit web y por qué se necesita contra scrapers de IA?
Un tar pit web (o “trampa de alquitrán”) es una técnica de defensa contra scrapers de IA que acepta a los crawlers en vez de bloquearlos, y los hunde en un flujo infinito de páginas generadas al azar, cada una con decenas de enlaces que vuelven al mismo laberinto. Lo crearon operadores de sitios para agotar los recursos del bot sin darle ninguna señal de que cayó en una trampa.
Acá viene el problema de fondo con el bloqueo clásico. Un 403 es información. El scraper lo lee, aprende qué defensa lo frenó, y se adapta: rota la IP, cambia el user-agent, entra de nuevo por un proxy residencial una hora después. Como lo resume el artículo de dev.to del 22 de junio de 2026, “una regla de denegación le enseña al atacante exactamente qué lo trabó”.
El tar pit invierte la jugada. Dice que sí a todo. El bot pide una página y la recibe llena de enlaces que loopean de vuelta. Cada enlace falso parece un descubrimiento nuevo. Un humano se aburre a las cuatro pantallas de texto sin sentido y cierra la pestaña. Un scraper no tiene gusto ni salida, así que sigue encolando URLs para siempre. Lo analizamos en nuestro artículo sobre integración de APIs de IA en tus sistemas.
¿Por qué ahora? Porque el volumen explotó. El tráfico de crawlers de IA creció a tal punto que se come el ancho de banda de cualquier sitio, y Cloudflare respondió con su anuncio oficial de AI Labyrinth. Para un sitio chico montado en un VPS, eso es factura de transferencia y CPU quemada para entrenar a un modelo ajeno.
¿Cómo funcionan los tar pits: la estrategia del laberinto infinito?
Ponele que un crawler pide /articulo-123. El servidor le devuelve una página real en apariencia, con párrafos armados y unos 40 enlaces internos. Cada uno apunta a otra página igual de falsa. El bot encola los 40, los visita, y cada uno le escupe otros 40. No hay fondo.
La parte fina es el determinismo. Las páginas son aleatorias pero se generan de forma determinista, así la misma URL devuelve siempre la misma basura. Eso importa. Si una URL diera contenido distinto en cada visita, un crawler inteligente la marcaría como dinámica y la descartaría. Al ser estable, parece un archivo estático más.
Hay dos agravantes que suman al diseño:
- Delays intencionales: Nepenthes mete pausas de alrededor de 1,4 a 1,5 segundos por respuesta. No tira el servidor, pero hace que recorrer el laberinto le cueste tiempo y conexiones abiertas al scraper.
- Markov-babble: el texto se genera con cadenas de Markov, palabras que parecen frases pero no dicen nada. Si ese contenido entra a un dataset de entrenamiento, lo contamina con ruido.
El resultado es asimétrico. A vos te cuesta unos pocos kilobytes generar cada página. Al scraper le cuesta tiempo, ancho de banda y, si traga el Markov-babble, calidad de datos. Esa asimetría es todo el punto.
Nepenthes vs AI Labyrinth: ¿cuál conviene para tu sitio?
La elección se reduce a una pregunta: ¿querés control total y te bancás la configuración, o querés que alguien lo resuelva por vos? Nepenthes es la herramienta cruda. AI Labyrinth es el servicio gestionado de Cloudflare. Mirá la comparación:
| Criterio | Nepenthes | AI Labyrinth (Cloudflare) |
|---|---|---|
| Modelo | Autohospedado, código abierto | Gestionado, en la red de Cloudflare |
| Costo | Gratis (código abierto) | Gratis, incluido hasta en el plan gratuito |
| Configuración | Manual: vos decidís qué URLs caen en la trampa | Automática, sin tocar nada |
| Riesgo de SEO | Alto si no lo aislás bien con robots/nofollow | Bajo: enlaces ocultos y nofollow, invisibles para humanos |
| Requisito | nginx o Apache propio | Tener el sitio detrás del proxy de Cloudflare |
| Detección de bots | La definís vos por reglas | Cloudflare distingue bots no autorizados de Google/Bing |
Si manejás tu propio servidor y querés ensuciar activamente los datos de entrenamiento, Nepenthes es para vos. Si tenés un blog o un ecommerce sin equipo de infra que lo mantenga, AI Labyrinth gana por practicidad. Para el resto de tu stack (hosting, dominios, el VPS donde corre todo), opciones como donweb.com te dan la base sobre la que después montás la defensa.
¿Cómo despliego Nepenthes en mi servidor web?
Nepenthes es de código abierto y se autohospeda. Se sienta detrás de tu servidor web y atiende cualquier ruta que vos le derives. Los pasos gruesos:
- Instalá el servicio detrás de nginx o Apache, como un backend más al que reverse-proxeás un path específico.
- Definí el alcance con cabeza: elegí una rama de URLs que NO esté en tu sitemap ni en tu índice de búsqueda. Esta es la decisión crítica y es manual.
- Bloqueá esa rama en robots.txt para que los bots buenos (Google, Bing) ni la toquen, y reservá la trampa para los que ignoran el archivo.
- Probá el determinismo: pegale dos veces a la misma URL trampa y confirmá que devuelve idéntico contenido.
Un detalle que conviene tener claro: la propia documentación describe a Nepenthes como “deliberadamente malicioso”. No es un plugin amable. Si lo apuntás mal, te podés tragar a tu propio crawler. Por eso el alcance manual no es un trámite, es el 90% del trabajo.
¿Cómo activo AI Labyrinth en Cloudflare sin romper el SEO?
Esta es la ruta sin configuración. Si tu sitio ya pasa por el proxy de Cloudflare (DNS apuntando a su red), AI Labyrinth se activa desde el panel de bots. Según la documentación de Cloudflare, la herramienta inyecta enlaces invisibles con atributo nofollow en las respuestas servidas a bots no autorizados, y los manda a un laberinto de páginas falsas.
¿Por qué no afecta el SEO? Tres motivos concretos:
- Los enlaces son invisibles para personas: no aparecen en el render visual de la página.
- Llevan nofollow, así que un crawler legítimo que los respete no los sigue.
- Solo se sirven a bots no autorizados: Cloudflare ya distingue a Googlebot y Bingbot del scraper genérico, y a esos no les muestra el laberinto.
El costo de entrada es tener el sitio en Cloudflare. Si ya estás ahí, es cuestión de un toggle. Si no, migrar el DNS es el precio.
¿Desaparece mi sitio de Google si pongo un tar pit?
El riesgo es real con Nepenthes mal configurado, pero evitable. Si la trampa alcanza al crawler de Google, tu indexación se puede ir a cero porque Google encola páginas basura en vez de tu contenido real. La solución no es magia: aislá la trampa.
Las dos defensas que protegen tu ranking:
- robots.txt + meta robots: bloqueá la rama del tar pit para crawlers buenos y poné
noindexen esas URLs trampa. - nofollow en los enlaces de entrada: que ningún link interno legítimo apunte al laberinto.
AI Labyrinth ya resuelve esto solo, porque sus enlaces son ocultos, nofollow y solo visibles para bots maliciosos. Con Nepenthes lo tenés que armar a mano. Como horizonte, varios proveedores empujan hacia AMTD (Automated Moving Target Defense), defensas que cambian de forma sola para que el atacante nunca encuentre un patrón estable.
¿Qué otras defensas existen contra scrapers de IA?
El tar pit no es bala de plata. Funciona mejor como una capa más, no como la única. Las que se combinan bien:
- robots.txt: OpenAI y Anthropic lo respetan; otros como Perplexity, según reportes, no siempre. Sirve contra los bots honestos, no contra los demás.
- Rate limiting + WAF: reglas por IP y límites de requests por minuto para cortar oleadas antes de que escalen.
- CAPTCHA selectivo: disparado solo ante patrones sospechosos, no para todo el tráfico (porque arruina la experiencia humana).
- Verificación de user-agent real: chequear que quien dice ser Googlebot lo sea de verdad por DNS inverso.
La receta práctica es por capas: tar pit para los bots que ignoran las reglas, robots.txt para los que las respetan, rate limiting para todos. Servirle basura a un bot falso suele rendir más que el bloqueo seco, porque no le das ninguna pista de cómo entraste a defenderte.
Qué está confirmado y qué no
Confirmado:
- AI Labyrinth existe, es de Cloudflare y está disponible sin costo, según su documentación oficial.
- Nepenthes es código abierto y autohospedado.
- Los enlaces de AI Labyrinth son ocultos y con nofollow.
No confirmado o a tomar con pinzas:
- La efectividad real a largo plazo: los scrapers también evolucionan, y mañana podrían detectar patrones de laberinto.
- El impacto exacto del Markov-babble en datasets de entrenamiento ajenos. La idea es sólida, la medición independiente es escasa.
- El comportamiento de cada bot frente a robots.txt cambia seguido. Lo que hoy respeta un crawler, mañana puede ignorarlo.
Errores comunes al montar un tar pit
- Apuntar la trampa a URLs indexadas: es el error que te borra de Google. Si la rama del tar pit está en tu sitemap, Googlebot la sigue y encola basura. Mantené la trampa fuera del índice, siempre.
- Olvidar el nofollow y el noindex: sin esas dos etiquetas, cualquier crawler legítimo trata el laberinto como contenido real. Ponelas antes de activar nada.
- Pensar que reemplaza al rate limiting: el tar pit ocupa al bot, no lo frena. Sin límites de request, un scraper agresivo igual te consume conexiones. Va combinado, no solo.
- Servir contenido no determinista: si cada visita devuelve algo distinto, el crawler detecta que es dinámico y se va. El determinismo es lo que hace creíble la trampa.
Preguntas Frecuentes
¿Qué es un tar pit web?
Es un servidor que en vez de bloquear a los crawlers los acepta y los hunde en un flujo infinito de páginas falsas con enlaces que loopean entre sí. El objetivo es agotar los recursos del scraper sin darle ninguna señal de que cayó en una trampa. Para más detalles técnicos, mirá herramientas de automatización para tu infraestructura.
¿Nepenthes o AI Labyrinth, cuál conviene?
AI Labyrinth conviene si querés cero configuración y ya usás Cloudflare, porque es automático y sin riesgo de SEO. Nepenthes conviene si manejás tu propio servidor y querés control total sobre qué URLs caen en la trampa.
¿Cuánto cuesta AI Labyrinth?
Nada. Cloudflare lo incluye sin costo adicional, incluso en su plan gratuito. El único requisito es tener el sitio detrás del proxy de Cloudflare con el DNS apuntando a su red.
¿Un tar pit me saca de Google?
Solo si lo configurás mal. Con AI Labyrinth no hay riesgo porque sus enlaces son ocultos y con nofollow. Con Nepenthes tenés que aislar la trampa con robots.txt y meta noindex para que Googlebot no la siga.
¿Robots.txt alcanza para frenar a los scrapers de IA?
No alcanza solo. OpenAI y Anthropic respetan robots.txt, pero otros bots según reportes lo ignoran. Por eso conviene sumarlo a un tar pit y a rate limiting, en capas, en vez de confiar en un único método.
Conclusión
El bloqueo seco perdió contra los scrapers de IA: cada 403 es una lección gratis para el atacante. La movida que ganó terreno en 2026 es la opuesta, decirles que sí y hundirlos en un laberinto. Si querés probarlo sin riesgo, activá AI Labyrinth en Cloudflare con un toggle. Si querés control total y te banca la infra, montá Nepenthes y aislalo con robots.txt y noindex.
Lo importante es no tratarlo como solución única. Tar pit para los bots que ignoran las reglas, robots.txt para los que las respetan, rate limiting para todos. Esa combinación es lo que hoy protege el ancho de banda y, de paso, le mete ruido al dataset del que se quiere colgar de tu contenido.