El misterio del BOOTSTRAP_TIMEOUT en Databricks sobre AWS
Los nodos EC2 estaban sanos (3/3 status checks) y el cluster de Databricks igual nunca arrancó. El error fue BOOTSTRAP_TIMEOUT tras 11 minutos de espera, y la causa no era el “puerto 443 cerrado” que repite medio Stack Overflow: el tráfico moría en un firewall de inspección centralizado detrás de un Transit Gateway. La solución de fondo es AWS PrivateLink. Un caso de Databricks cluster bootstrap timeout AWS documentado el 2 de julio de 2026.
En 30 segundos
- Qué pasó: un cluster classic compute en una VPC customer-managed tiró BOOTSTRAP_TIMEOUT a los 11 minutos con los EC2 healthy.
- Por qué: el egress centralizado (spoke VPC → Transit Gateway → firewall de inspección → NAT → IGW) bloqueaba el tráfico hacia el control plane, sin logs obvios.
- El síntoma engañoso: el firewall permitía el puerto 443, así que el “abrí el 443” clásico no aplicaba.
- Cómo se debuggeó: desplegando un EC2 de prueba en la misma subnet y trazando el paquete con nc/tcpdump hasta
tunnel.<region>.cloud.databricks.com:443. - Fix definitivo: AWS PrivateLink para que el tráfico del control plane vaya por el backbone de AWS y no dependa del firewall.
BOOTSTRAP_TIMEOUT es el error que Databricks lanza cuando un cluster no completa su arranque dentro del tiempo por defecto (unos 11 minutos) porque los nodos no lograron establecer conectividad con el control plane. En AWS classic compute, aparece cuando las instancias EC2 levantan bien pero el túnel de secure cluster connectivity nunca se establece. No es un fallo de la instancia: es un problema de red entre el data plane y el control plane.
¿Qué causa el error BOOTSTRAP_TIMEOUT en un cluster de Databricks?
Ponele que lanzás un cluster, la UI de Databricks lo muestra en estado INSTANCE_INITIALIZING, y en Terraform ves ese cartelito que te va comiendo la paciencia:
databricks_cluster.this["shared_small"]: Still creating... [10m20s elapsed]
Y después, el golpe: Error: cannot create cluster... BOOTSTRAP_TIMEOUT. Según la KB oficial de Databricks, este error significa que los nodos arrancaron pero no pudieron “reportarse” al control plane a tiempo. La diferencia con otros errores de cluster es clave: acá no hay un problema de cuota EC2, ni una AMI rota, ni un fallo de arranque de la instancia. La máquina está viva. Lo que no funciona es la conversación con Databricks.
Con secure cluster connectivity activado (sin IPs públicas en los nodos), el cluster inicia una conexión outbound hacia el control plane. Si esa conexión no se completa, el nodo queda esperando y el reloj corre.
¿Por qué fallan los clusters detrás de un firewall centralizado con Transit Gateway?
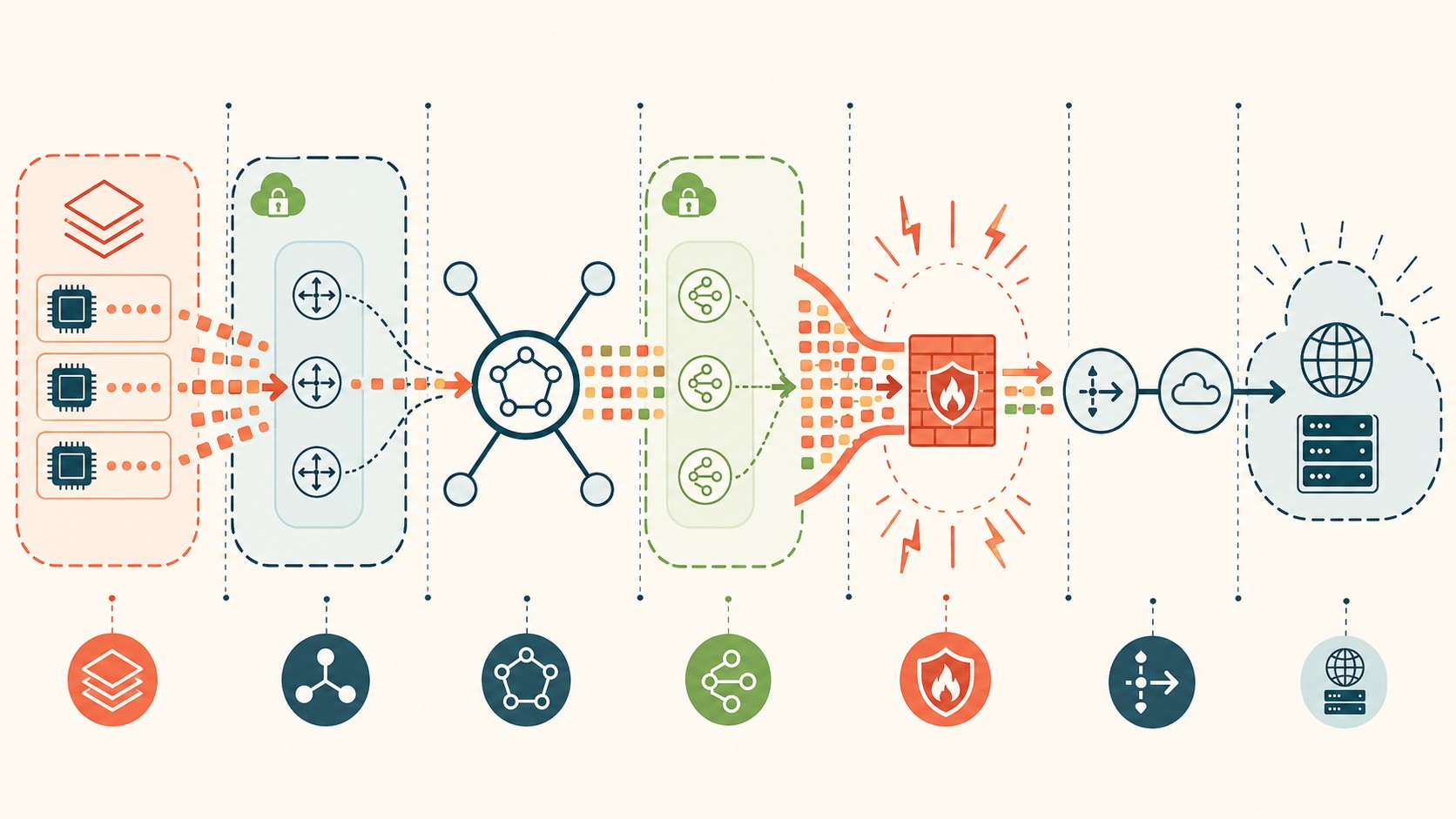
Acá viene lo bueno. En una arquitectura hub-and-spoke, la VPC donde vive el cluster (la “spoke”) no sale a internet por su cuenta. Todo el tráfico de salida se centraliza a través de un Transit Gateway que lo manda a una cuenta de red compartida, donde un firewall de inspección (típicamente un Gateway Load Balancer con appliance) revisa cada paquete antes de dejarlo pasar al NAT y al Internet Gateway.
El flujo completo, tal como lo describe el análisis publicado en dev.to, es este: nodo del cluster (sin IP pública) → route table de la spoke (0.0.0.0/0 apunta al TGW) → Transit Gateway en la cuenta de red-hub → VPC DMZ → firewall de inspección vía GWLB → NAT → IGW → internet → control plane de Databricks. Tres cuentas y saltos de por medio, cualquiera de los cuales puede tragarse el paquete.
El problema es que el firewall de inspección puede bloquear el tráfico en silencio. No te tira un “denegado” que aparezca en la consola de Databricks. Simplemente el paquete no llega, el túnel no se arma, y a los 11 minutos te comés el timeout. Por eso este caso es tan traicionero: parece un problema de Databricks cuando en realidad es de tu política de firewall.
¿Cuál es la diferencia entre “puerto 443 cerrado” y un BOOTSTRAP_TIMEOUT real?
La respuesta más repetida en foros es “abrí el puerto 443 de salida”. El tema es que en este caso el firewall ya permitía el 443. La regla estaba. El tráfico igual moría.
¿Por qué? Porque permitir el puerto no es lo mismo que permitir el destino. Con secure cluster connectivity, los nodos abren la conexión hacia afuera (no reciben tráfico entrante), así que el problema no está en un Security Group de inbound. Está en la inspección: el firewall filtra por FQDN o por dominio, y si el destino tunnel.<region>.cloud.databricks.com no está en la allowlist, chau. El puerto abierto no sirve de nada si el hostname no pasa el filtro.
¿Qué ruta debe seguir el tráfico del cluster hacia el control plane?
Para debuggear esto tenés que pensar como el paquete. Cada salto tiene que estar bien ruteado y permitido, o la cadena se corta. Esta es la tabla salto por salto:
| Salto | Dónde ocurre | Qué tiene que estar bien |
|---|---|---|
| 1. Nodo del cluster | Subnet de la spoke VPC | Sin IP pública; conexión outbound iniciada |
| 2. Route table spoke | Spoke VPC | 0.0.0.0/0 → Transit Gateway |
| 3. Transit Gateway | Cuenta network-hub | Ruta al CIDR de destino (control plane) |
| 4. VPC DMZ + GWLB | Cuenta network-hub | Endpoint del firewall alcanzable |
| 5. Firewall de inspección | Appliance detrás del GWLB | FQDN de Databricks en la allowlist |
| 6. NAT + IGW | DMZ VPC | Salida a internet habilitada |
| 7. Destino | Internet | tunnel.<region>.cloud.databricks.com:443 |
¿Qué destinos hay que allowlistar en el firewall para Databricks?
No alcanza con un solo hostname. El cluster necesita hablar con varios destinos para arrancar y funcionar. Según la documentación de customer-managed VPC, estos son los que no pueden faltar:
- El túnel de conectividad:
tunnel.<region>.cloud.databricks.compor el puerto 443. Es el que arma el secure cluster connectivity; sin esto, BOOTSTRAP_TIMEOUT asegurado. - El control plane regional: el FQDN del workspace de tu región, también por 443.
- El metastore RDS regional: por el puerto 3306 (MySQL). El cluster consulta el metastore de Hive gestionado.
- Los endpoints de servicios AWS: S3, STS, Kinesis y CloudWatch Logs. Databricks los usa para storage, credenciales temporales y logging.
- El CIDR del nodo: asegurate de que el rango de la subnet del cluster esté contemplado como origen permitido en las reglas del firewall.
¿Cómo debuggear un BOOTSTRAP_TIMEOUT paso a paso?
El método que usó el autor para cazar el problema es reproducible y no depende de adivinar. Seguí este orden:
- Verificá los status checks del EC2: tienen que dar 3/3. Si dan bien, descartás la instancia y sabés que es red.
- Desplegá un EC2 de prueba en la misma subnet de la spoke: desde ahí corré
nc -vz tunnel.<region>.cloud.databricks.com 443o un telnet. Si no conecta, replicaste el problema fuera de Databricks. - Capturá paquetes con tcpdump: mirá si el tráfico siquiera llega al firewall o se muere antes, en el TGW.
- Revisá los logs del firewall: buscá el FQDN de Databricks. Si aparece como bloqueado, ya tenés el culpable.
- Chequeá las route tables del Transit Gateway: confirmá que existe la ruta hacia el CIDR de destino y que no hay un blackhole.
Este flujo te dice exactamente en qué salto se corta la cadena. Subís el EC2 de prueba, tirás un nc, mirás el tcpdump, cruzás con el log del firewall y de repente el “misterio” de 11 minutos se convierte en una regla de allowlist que faltaba. Nada de magia.
¿Por qué PrivateLink es la solución a largo plazo?
Arreglar la allowlist del firewall te destraba hoy. Pero seguís dependiendo de que nadie toque esa política, de que el equipo de red no cambie una regla, de que el FQDN del control plane no rote. Es frágil.
AWS PrivateLink cambia el juego: el tráfico entre tu data plane y el control plane de Databricks viaja por el backbone privado de AWS, no por internet. Ya no pasa por el firewall de inspección centralizado para ese tráfico crítico. Se configura en los settings del workspace de Databricks y en los VPC endpoints, siguiendo la guía de firewall hub-and-spoke del provider de Terraform. Elimina la dependencia de que la política de egress esté perfecta para que un cluster arranque. Es la jugada de fondo cuando administrás infraestructura de datos en AWS con egress centralizado.
Errores comunes al enfrentar un BOOTSTRAP_TIMEOUT
- Asumir que es “abrí el 443” y cerrar el ticket: si el firewall filtra por FQDN, el puerto abierto no alcanza. Corrección: verificá que el hostname del túnel esté en la allowlist, no solo el puerto.
- Mirar los Security Groups de inbound: con secure cluster connectivity el tráfico es outbound. Corrección: enfocate en las reglas de egress y en la inspección del firewall.
- Culpar a Databricks sin trazar el paquete: el estado
INSTANCE_INITIALIZINGcon EC2 healthy casi siempre es red tuya, no de ellos. Corrección: desplegá el EC2 de prueba y hacé el nc antes de abrir un caso de soporte. - Olvidarse del metastore y S3: allowlisteás el túnel pero no el puerto 3306 ni los endpoints de AWS, y el cluster arranca a medias. Corrección: allowlisteá todos los destinos, no solo el control plane.
Preguntas Frecuentes
¿Qué significa el error BOOTSTRAP_TIMEOUT en Databricks?
BOOTSTRAP_TIMEOUT significa que el cluster no completó su arranque en el tiempo por defecto (unos 11 minutos) porque los nodos no lograron conectarse al control plane. Los EC2 pueden estar sanos igual: es un problema de red entre data plane y control plane, no de la instancia.
¿Por qué el cluster no inicia si las instancias EC2 están healthy?
Porque un status check 3/3 solo confirma que la máquina virtual funciona, no que tenga ruta hacia Databricks. Con secure cluster connectivity el nodo debe iniciar una conexión outbound al túnel; si un firewall o una route table la bloquea, el cluster queda colgado aunque el EC2 esté impecable.
¿Qué puertos necesita Databricks para egress centralizado?
El puerto 443 para el túnel de conectividad y el control plane, y el puerto 3306 para el metastore RDS regional. También necesita alcanzar los endpoints de S3, STS, Kinesis y CloudWatch Logs. Con abrir solo el 443 no alcanza.
¿Cómo debuggeo conectividad de Databricks detrás de un firewall?
Desplegá un EC2 de prueba en la misma subnet del cluster y probá nc -vz tunnel.<region>.cloud.databricks.com 443. Si no conecta, capturá con tcpdump para ver hasta qué salto llega el paquete y cruzá con los logs del firewall. Eso aísla el punto exacto donde muere el tráfico.
¿PrivateLink elimina por completo el riesgo de BOOTSTRAP_TIMEOUT?
PrivateLink saca el tráfico del control plane del camino por internet y del firewall centralizado, lo que elimina la causa más común en arquitecturas hub-and-spoke. No cubre otros orígenes (cuotas EC2, subredes mal configuradas), pero para el caso de egress centralizado es la solución más robusta.
Conclusión
Lo que cambió acá no es una feature nueva de Databricks: es entender que un BOOTSTRAP_TIMEOUT con EC2 healthy casi nunca es culpa de Databricks. En arquitecturas con egress centralizado (Transit Gateway más firewall de inspección), el tráfico del cluster hacia el control plane puede morir en un filtro de FQDN sin dejar rastro obvio, y el clásico “abrí el 443” no lo resuelve. La jugada correcta tiene dos tiempos: destrabar hoy allowlisteando los destinos reales (túnel, control plane, metastore 3306, endpoints de AWS) y después migrar a PrivateLink para que ese tráfico crítico deje de depender de la política de firewall. Si administrás datos en AWS con esta topología, trazá el paquete antes de abrir un ticket. Te va a ahorrar horas.



![Open System Firmware: Experiences deploying LinuxBoot, coreboot at Google (2021) [video] - ilustracion](https://donweb.news/wp-content/uploads/2026/06/linuxboot-coreboot-firmware-abierto-google-hero-768x432.jpg)