GitHub abril 2026: dos caídas críticas explicadas
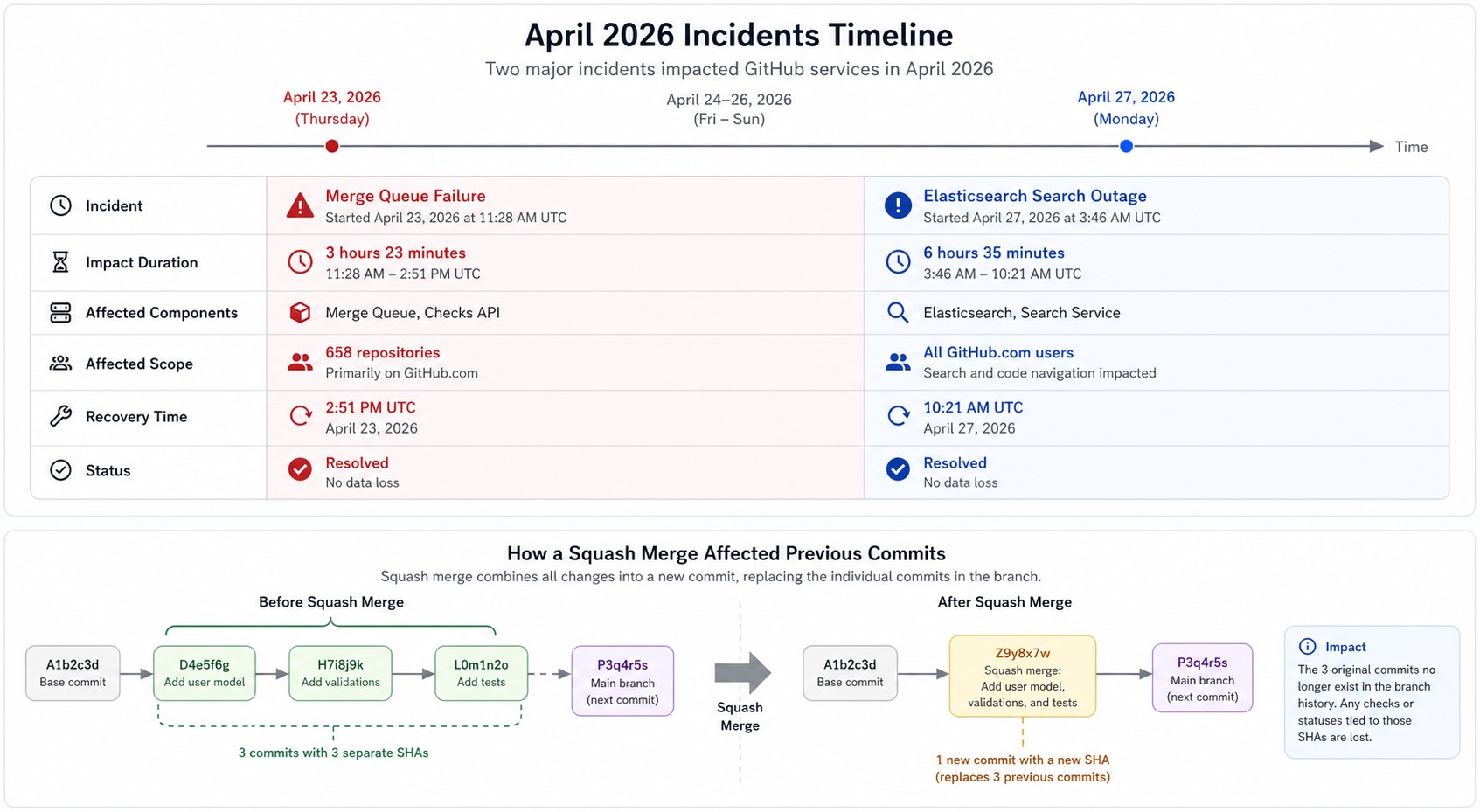
En pocas palabras: GitHub sufrió dos caídas críticas en abril de 2026: el 23, un fallo en Merge Queue generó commits incorrectos en 658 repositorios y 2.092 pull requests; el 27, una sobrecarga de Elasticsearch dejó sin funcionar la búsqueda de PRs, issues y proyectos en toda la plataforma.
Ejemplo práctico
El equipo de plataforma de Nubalt, una fintech cordobesa de 42 desarrolladores, tenía Merge Queue activado en su monorepo principal con un promedio de 130 pull requests fusionados por día. El 23 de abril a las 14:10 (hora Argentina), tras el deploy de la mañana, tres servicios empezaron a fallar en staging porque un commit de fusión había revertido una migración de base de datos ya aprobada la semana anterior. El líder técnico, Damián Rossi, cruzó el timeline de los PR con el aviso de githubstatus.com, confirmó que su repo estaba entre los 658 afectados y tomó tres medidas: desactivó Merge Queue, congeló los merges a main y auditó con git log --merges --since="2026-04-23" los 87 PR fusionados esa jornada.
De esos 87, encontraron 4 commits de fusión con reversiones fantasma. Los rehicieron manualmente con git revert del commit defectuoso y reaplicaron los cambios legítimos desde la rama de cada feature, validando cada uno con la suite de tests antes de reabrir la cola.
Resultado: el incidente se contuvo en 2 horas 40 minutos, se recuperaron los 4 PR corruptos sin pérdida de código y evitaron desplegar a producción una migración revertida. Desde entonces el equipo dejó Merge Queue en pausa hasta el fix de GitHub y sumó un chequeo automático de githubstatus.com al pipeline de CI, que bloquea los merges cuando hay un incidente activo en la plataforma.
Cómo funciona
- Encolado del PR: cuando aprobás un pull request, Merge Queue no lo fusiona al toque sino que lo mete en una fila ordenada junto a los demás PR listos del mismo repositorio.
- Fusión especulativa: el sistema toma cada PR de la fila y arma un commit tentativo apilándolo sobre los cambios que están adelante suyo, asumiendo que todos van a entrar en ese orden.
- Validación en cadena: corre los tests y checks sobre ese commit especulativo; si pasan, el PR avanza y el siguiente de la cola se reevalúa contra el nuevo estado de la rama.
- Integración final: una vez validado, el commit se escribe en la rama base sin necesidad de volver a resolver conflictos manualmente, lo que acelera equipos con muchos merges por hora.
- Dónde falló en abril: el defecto rompió el paso de fusión especulativa y generó commits que, en vez de sumar los cambios, revertían código ya integrado — por eso los 2.092 PR afectados no tenían arreglo automático.
GitHub tuvo dos incidentes críticos de disponibilidad en abril de 2026: el 23 de abril, un defecto en el sistema Merge Queue afectó 658 repositorios y dejó 2.092 pull requests con commits incorrectos que revertían cambios previos. El 27 de abril, una sobrecarga en Elasticsearch colapsó la búsqueda de PRs, issues y proyectos en toda la plataforma.
En 30 segundos
- El 23 de abril, Merge Queue generó commits de fusión incorrectos que revertían código previo en 658 repos y 2.092 PRs — sin reparación automática posible.
- El 27 de abril, Elasticsearch se sobrecargó y dejó sin resultados la búsqueda de PRs, issues y proyectos (Git y las APIs siguieron funcionando).
- La causa de fondo es el crecimiento exponencial de tráfico desde diciembre de 2025, impulsado por flujos de desarrollo con agentes de IA.
- GitHub está intentando escalar su infraestructura 30 veces y migrando componentes críticos a Azure.
- Podés seguir el estado en tiempo real en githubstatus.com.
GitHub disponibilidad: qué pasó en abril de 2026
GitHub es la plataforma de alojamiento de código y colaboración de Microsoft usada por más de 100 millones de desarrolladores para gestionar repositorios Git, revisar código y coordinar despliegues. Cuando falla, no es un inconveniente menor: para miles de equipos que dependen de ella en su pipeline de CI/CD, cada minuto de incidente es código que no llega a producción.
Abril de 2026 trajo dos episodios distintos que, juntos, empiezan a dibujar un patrón. No son caídas aleatorias. Tienen una causa estructural que GitHub reconoció públicamente y que vale entender.
Incidente 1: Merge Queue quebrado (23 de abril)
Ponele que tu equipo lleva dos semanas trabajando en una feature, abrieron la PR, pasaron todos los checks, alguien apretó merge — y en vez de fusionar el trabajo nuevo, el commit resultante revirtió cambios anteriores que ya estaban en main. Eso es exactamente lo que ocurrió. Para más detalles técnicos, mirá optimizar presencia en múltiples regiones.
Según el comunicado oficial de GitHub, el defecto afectó específicamente pull requests que usaban el método squash dentro del sistema Merge Queue. El resultado: commits de fusión incorrectos que revertían código previo, sin ningún mecanismo de reparación automática disponible. Los números finales fueron 658 repositorios afectados y 2.092 PRs con el problema.
Lo más delicado de este incidente es la naturaleza del daño. Una caída de búsqueda se recupera sola cuando vuelve el servicio. Esto no: si no detectaste el problema antes de que otros commits se apilaran encima, reconstruir el historial correcto es un trabajo manual que puede llevar horas. (Y si ya hiciste deploy de ese código, la cosa se complica bastante más.)
¿Qué debería hacer tu equipo ante algo así? Validar el diff de cada merge crítico antes de avanzar, y si usás Merge Queue con squash, revisá el historial de commits de las PRs fusionadas ese día.
Incidente 2: Búsqueda colapsada por Elasticsearch (27 de abril)
Cuatro días después, el 27 de abril, el subsistema Elasticsearch de GitHub se sobrecargó y dejó la búsqueda de pull requests, issues y proyectos sin resultados en toda la plataforma.
Este incidente tiene una lectura distinta. Git siguió funcionando. Las APIs respondían. Los repos estaban accesibles. El daño fue específicamente en la capa de búsqueda e indexación — lo que significa que si sos parte de un equipo grande donde encontrás trabajo buscando por número de issue o filtrando PRs por etiqueta, quedaste medio ciego operativamente. Esto se conecta con lo que analizamos en configurar herramientas en contenedores.
Es un tipo de falla que tiende a subestimarse (porque “al menos el código está”) pero que impacta en la coordinación del equipo durante horas.
¿Por qué está ocurriendo esto? La presión de los agentes IA
Acá viene lo que hace que estos incidentes sean más que dos bugs aislados.
Desde diciembre de 2025, GitHub viene registrando un crecimiento exponencial en el volumen de operaciones. La causa principal, según la empresa, son los flujos de desarrollo automatizados con agentes de IA que generan commits, abren PRs y disparan checks de CI a una velocidad que los humanos no pueden sostener manualmente. Un agente que itera sobre código puede abrir decenas de PRs en el tiempo que un desarrollador abre una.
El volumen nuevo de tráfico que GitHub está intentando absorber representa una escala 30 veces mayor a la que la plataforma fue diseñada originalmente para manejar, de acuerdo con lo que reportó InfoQ sobre los planes de escalabilidad. Para dar respuesta a eso, la empresa está ejecutando una migración de componentes críticos hacia Azure como solución estructural de largo plazo.
Migrás tu infraestructura mientras la usas a máxima carga. Que salgan algunos incidentes no es sorprendente; lo que sorprende es que no haya más.
Historial de disponibilidad de GitHub en 2026
Enero y marzo de 2026 ya habían tenido episodios menores. Pero febrero fue el mes más crítico: GitHub cerró con 90,21% de uptime, muy por debajo del objetivo declarado de 99,95%. Para ponerlo en contexto, 90,21% de uptime mensual implica aproximadamente 71 horas de servicio degradado o caído en 28 días. Más contexto en automatizar procesos críticos.
| Mes | Uptime estimado | Incidente notable |
|---|---|---|
| Enero 2026 | ~98% | Intermitencia en Actions |
| Febrero 2026 | 90,21% | Múltiples degradaciones de servicio |
| Marzo 2026 | ~97% | Episodios aislados de lentitud |
| Abril 2026 | Por confirmar | Merge Queue + Elasticsearch |
El patrón es claro: los problemas no son aleatorios, reflejan la presión de escalar una infraestructura que creció más rápido de lo previsto.
Cómo verificar el estado de GitHub en tiempo real
Si en tu equipo todavía no tienen esto configurado, hoy es el día.
Fuente primaria: GitHub Status
La página oficial githubstatus.com muestra el estado de cada componente por separado: Git Operations, API Requests, Actions, Packages, Pages, Codespaces, Copilot. Permite suscribirse a notificaciones por email, SMS, webhook o RSS. Es la fuente de verdad — si algo no aparece ahí, GitHub no lo reconoce oficialmente.
Alternativas de monitoreo externo
Para equipos que necesitan alertas antes de que GitHub actualice su propia página (lo cual puede tomar varios minutos), herramientas como StatusGator e IncidentHub agregan y correlacionan reportes de usuarios en tiempo real. Útil para detectar incidentes en el momento en que arrancan, no cuando ya se confirmaron.
Recomendaciones inmediatas para equipos de desarrollo
Hay cosas concretas que podés hacer ahora mismo:
- Suspendé merges durante incidentes activos. Si githubstatus.com muestra degradación en “Git Operations” o “Pull Requests”, esperá. Un merge en ese estado puede generar exactamente el tipo de problema del 23 de abril.
- Mantené backups locales de cambios en curso. Antes de hacer push o merge de trabajo crítico, asegurate de tener el estado local guardado. Si el merge resulta corrupto, vas a necesitar reconstruir desde ahí.
- Validá commits después de cada merge. Especialmente si usás Merge Queue con squash. Un
git log --oneline -10después del merge tarda 3 segundos y puede salvarte horas. - Configurá alertas del equipo. No alcanza con que una persona del equipo monitoree. Integrá las notificaciones de GitHub Status a tu canal de Slack o Teams para que todos estén al tanto al mismo tiempo.
- Documentá ventanas de incidente. Si sabés que GitHub tuvo problemas entre las 14:00 y las 17:00, podés auditar qué merges ocurrieron en ese rango y revisarlos con atención.
Errores comunes durante incidentes de GitHub
Error 1: Confundir “Git funciona” con “todo está bien”. El incidente del 27 de abril lo deja claro: podés clonar repos y hacer push normalmente mientras la búsqueda y los issues están rotos. Si tu workflow depende de encontrar trabajo por búsqueda, el hecho de que Git responda no significa que podés operar normalmente.
Error 2: Hacer retry agresivo durante degradaciones. Si Actions o la API están lentas y tu pipeline reintenta cada 30 segundos, estás sumando carga a un sistema ya saturado. Configurá backoff exponencial en tus integraciones y, en incidentes confirmados, simplemente pausá los pipelines no urgentes.
Error 3: Asumir que el incidente terminó porque “ya funciona para mí”. Las recuperaciones parciales son comunes. GitHub puede restaurar funcionalidad básica mientras sigue habiendo inconsistencias en datos ya afectados. Esperá la actualización de “resolved” en githubstatus.com antes de asumir que el entorno es confiable para operaciones críticas. Ya lo cubrimos antes en realizar auditoría de seguridad completa.
Qué significa esto para equipos en Latinoamérica
La dependencia de GitHub en la región es alta, y los incidentes tienden a ocurrir en horario laboral de Europa y Costa Este de EE.UU., que coincide con la tarde de Argentina, Chile y Brasil. Eso significa que podés llegar a la tarde con pipelines rotos justo cuando querés cerrar la sprint.
Para equipos que usan infraestructura propia — hosting, VPS, servidores de integración — tener un monitoreo externo de dependencias como GitHub, y no asumir que el problema es propio cuando el CI falla, es parte de una buena práctica de operaciones. Proveedores locales como donweb.com para hosting e infraestructura te dan una capa que controlás directamente, aunque la dependencia de la plataforma de repositorios siempre va a existir.
Preguntas Frecuentes
¿Qué pasó con GitHub el 23 y 27 de abril de 2026?
El 23 de abril, un defecto en el sistema Merge Queue generó commits incorrectos que revertían cambios previos en 658 repositorios y 2.092 pull requests usando squash merge. El 27 de abril, el subsistema Elasticsearch se sobrecargó y dejó sin resultados la búsqueda de PRs, issues y proyectos en toda la plataforma, aunque Git y las APIs continuaron funcionando.
¿Cómo afecta la caída de GitHub a mis repositorios?
Depende del tipo de incidente. Si afecta Git Operations, los push, pull y clones pueden fallar. Si afecta Merge Queue (como el 23 de abril), los merges ejecutados durante el incidente pueden contener datos incorrectos. Si afecta búsqueda (como el 27 de abril), el código está íntegro pero no podés encontrar issues ni PRs por búsqueda. Siempre validá el estado en githubstatus.com para saber qué componente está afectado.
¿Dónde puedo ver el estado actual de GitHub?
La fuente oficial es githubstatus.com, que muestra el estado de cada componente por separado y permite suscribirse a alertas. Para detección más rápida, servicios externos como StatusGator agregan reportes de usuarios en tiempo real y suelen detectar incidentes antes de que GitHub los reconozca oficialmente.
¿Es seguro hacer merge en GitHub ahora?
Si githubstatus.com muestra todos los componentes en verde, el sistema está operativo. Para merges críticos, la recomendación es validar el commit resultante con git log inmediatamente después, especialmente si usás Merge Queue con squash. Durante cualquier degradación activa en “Pull Requests” o “Git Operations”, suspendé merges hasta que el incidente esté marcado como resuelto.
¿Por qué GitHub está teniendo tantos problemas de disponibilidad en 2026?
El crecimiento exponencial de tráfico desde diciembre de 2025 — impulsado por flujos de desarrollo con agentes de IA que generan operaciones a escala masiva — puso presión sobre una infraestructura que no estaba dimensionada para ese volumen. GitHub está intentando escalar 30 veces su capacidad y migrando componentes críticos a Azure. Los incidentes de disponibilidad son, en parte, consecuencia de esa migración en curso bajo carga real.
Conclusión
Los dos incidentes de abril no son bugs aislados: son síntomas visibles de una plataforma que está siendo forzada a crecer más rápido de lo que su arquitectura original permite. El caso del Merge Queue es el más preocupante porque el daño no es reversible automáticamente: requiere auditoría manual de cada merge afectado.
Lo que cambió en 2026 es la naturaleza del tráfico. Cuando los agentes de IA pueden generar decenas de operaciones por minuto, la infraestructura de una plataforma pensada para humanos empieza a crujir en lugares inesperados. GitHub lo sabe y está trabajando en escalar, pero mientras tanto, la estrategia más inteligente para tu equipo es monitorear activamente y no asumir disponibilidad.
Agregá githubstatus.com a tu dashboard de operaciones hoy. No es paranoia; es que ya tuvieron dos incidentes relevantes en una semana.
¿Hay un problema con GitHub ahora?
Para verificar el estado actual de GitHub, visitá githubstatus.com que muestra cada componente en tiempo real. Este artículo cubre incidentes de abril 2026; el estado cambia constantemente así que siempre chequea la página oficial.
¿Qué pasó exactamente el 23 de abril con Merge Queue?
Un defecto en el sistema Merge Queue de GitHub generó commits de fusión incorrectos que revertían código previo. Afectó 658 repositorios y 2.092 pull requests, sin mecanismo automático de reparación — requirió reconstrucción manual del historial.
¿Qué hago si mi merge salió corrupto por este incidente?
Validá el diff con git log –oneline para identificar los commits afectados. Si el código corrupto ya está en main, considerá un rollback inmediato. Si aún no hiciste deploy, reconstruí el historial manualmente antes de avanzar.
¿Qué pasó con los issues durante la caída de Elasticsearch del 27 de abril?
Los issues no se perdieron, pero la búsqueda quedó rota en toda la plataforma. No podías filtrar por label, número o contenido, aunque toda la información seguía ahí. Se recuperó cuando Elasticsearch volvió en pocas horas.
¿Cómo sé si tu repositorio fue afectado por el Merge Queue del 23?
Si usabas Merge Queue con squash el 23 de abril entre las 14:00 y 15:30 UTC, corrés `git log –merges –since=”2026-04-23″` para detectar commits que hayan revertido cambios previos.
¿Cómo evitar que las caídas de GitHub rompan tu pipeline?
Configurá alertas en githubstatus.com o integrá un webhook en tu CI que bloquee merges cuando hay un incidente activo en la plataforma.