Salud del servidor: lecciones del caso Veltrix 2026
Cuando los servidores del Treasure Hunt Engine empezaron a fallar en producción, el equipo no tenía un problema de hardware sino un problema de supuestos. La configuración estándar recomendada por los desarrolladores de la plataforma Veltrix generó errores java.lang.OutOfMemoryError y advertencias de disco lleno desde el primer día de carga real. La optimización de la salud del servidor no es cuestión de aplicar la documentación oficial: es entender por qué esa documentación no alcanza para tu sistema específico.
En 30 segundos
- El Treasure Hunt Engine corriendo en Veltrix colapsó con parámetros estándar: crashes repetidos, corrupción de datos y errores
OutOfMemoryErrordesde el inicio - Los intentos iniciales con Prometheus y Grafana fallaron porque monitoreaban métricas pero ignoraban las interdependencias entre componentes del sistema
- La configuración genérica del proveedor no contempla arquitecturas únicas; hay que medir el comportamiento real bajo carga propia
- El 80% de los crashes en servidores de aplicaciones no es falta de memoria sino mala gestión del caché y configuración de páginas
- Una estrategia de alertas con umbrales contextualizados previene los falsos positivos que terminan anestesiando al equipo de operaciones
El problema: la configuración genérica no garantiza estabilidad
La optimización de la salud del servidor tiene un enemigo silencioso: la documentación oficial. No porque esté mal escrita, sino porque asume un caso de uso promedio que no existe. Cualquiera que haya desplegado una aplicación en producción sabe que el “ambiente recomendado” del proveedor es un punto de partida, no una garantía.
Según el análisis publicado el 25 de mayo de 2026, el equipo detrás del Treasure Hunt Engine arrancó siguiendo al pie de la letra los parámetros sugeridos por los desarrolladores de Veltrix: memoria asignada, límites de CPU, espacio en disco. Resultado: crashes frecuentes, corrupción de datos y errores como java.lang.OutOfMemoryError y disk space exceeded apareciendo incluso antes de llegar a cargas pico.
El problema de fondo era que los parámetros estándar no contemplaban la arquitectura específica del sistema: múltiples instancias corriendo sin coordinación, componentes interdependientes que nadie había mapeado, y cargas de trabajo que se alejaban bastante del caso “típico” que la documentación describía.
Síntomas de un servidor en problemas antes del crash
Los servidores no fallan de golpe. Avisan. El problema es que los avisos son lentos, intermitentes y fáciles de ignorar si no tenés un sistema que los correlacione.
Los síntomas previos al colapso suelen seguir este patrón: primero aparece latencia creciente en respuestas que antes eran rápidas, después picos de memoria que se resuelven solos (y que en los logs pasan desapercibidos), luego errores intermitentes que “no se reproducen” cuando los investigás, y finalmente lentitud generalizada que el equipo atribuye a “la red” o “el tráfico”.
¿Por qué esto termina en corrupción de datos? Porque cuando un proceso se queda sin memoria de forma abrupta, las escrituras en disco quedan incompletas. Según el análisis de Geekflare sobre corrupción de datos, la interrupción inesperada de procesos durante operaciones de escritura es una de las causas más frecuentes de corrupción en sistemas de producción, junto con fallas de hardware en discos con sectores defectuosos.
Prometheus y Grafana aparecen como la solución obvia, y sí ayudan, pero con una advertencia importante. Lo explicamos en detalle en nuestro artículo sobre optimizar tus pipelines de deployment.
Arquitectura de monitoreo: lo que Prometheus y Grafana no resuelven solos
El equipo del Treasure Hunt Engine implementó Prometheus y Grafana desde el inicio. Aun así, los crashes siguieron. ¿El motivo? Tenían métricas pero no tenían observabilidad. Son cosas distintas.
Las métricas te dicen qué pasó. La observabilidad te dice por qué pasó. Podés ver que la memoria llegó al 95% a las 3am, pero si no entendés qué proceso la consumió, qué lo disparó, y cómo interactúa con el resto del sistema, solo sabés que hay un incendio pero no dónde está la fuente.
La arquitectura recomendada por Whitestack para un stack de observabilidad real incluye cuatro capas: recolección de métricas (Prometheus), visualización (Grafana), correlación de logs (Loki o Elasticsearch), y trazabilidad distribuida (Jaeger o Tempo). Las métricas clave a monitorear son CPU (uso y throttling), memoria RAM (uso, swap, page faults), disco (IOPS, latencia de lectura/escritura, espacio por partición), y latencia de red entre componentes internos.
Lo que el equipo de Veltrix aprendió de mala manera: no alcanza con saber que la memoria está alta. Hay que saber qué componente la consume, con qué frecuencia, y si ese patrón cambia en el tiempo.
Optimización de memoria y caché: la pieza clave que nadie configura bien
Ponele que tu servidor tiene 16GB de RAM y la aplicación usa 12GB bajo carga. Parece bien. Pero si el garbage collector de Java corre cada 30 segundos y pausa todos los threads por 2 segundos cada vez, tenés latencia intermitente que ningún gráfico de memoria va a mostrar claramente.
La gestión de caché es donde se gana o se pierde la estabilidad. Según la documentación de Microsoft sobre gestión de caché en Windows Server, la mayoría de los sistemas operativos intentan usar toda la RAM disponible para caché de disco (file system cache), lo cual puede generar competencia directa con las aplicaciones que necesitan memoria propia.
Tres configuraciones que marcan la diferencia en la práctica:
- Límites de heap explícitos en JVM: sin valores de
-Xmsy-Xmxdefinidos, la JVM puede tomar toda la RAM disponible antes de que el OS reaccione - Configuración de swap adecuada: usar swap como colchón de emergencia está bien; depender de él para carga normal no
- Políticas de caché L2/L3: en sistemas con Redis o Memcached, definir TTL y estrategias de eviction explícitas evita que el caché crezca indefinidamente
El caso del servidor modificado con 512MB en el análisis de Veltrix es ilustrativo: no era falta de RAM, era que el proceso no tenía límite superior definido y consumía todo lo disponible antes de liberar.
Estrategia de alertas que no anestesia al equipo
El problema más frecuente de las alertas no es que no existan: es que son tantas y tan poco contextualizadas que el equipo aprende a ignorarlas. Tema relacionado: evaluar soluciones de integración continua.
Una alerta de “memoria al 80%” que dispara a las 3am todos los martes porque hay un proceso de backup programado no es una alerta útil. Es ruido. Y el ruido repetido genera el peor escenario posible: el día que la memoria al 80% sea una señal real de un problema, nadie la va a mirar.
¿Cómo se resuelve esto? Con umbrales contextualizados. No “memoria mayor a 80%” sino “memoria mayor a 80% por más de 10 minutos fuera del horario de backup”. La diferencia parece sutil pero cambia todo.
Para infraestructura en VPS o servidores dedicados, donweb.com incluye paneles de monitoreo que permiten configurar alertas por umbrales desde el panel de control, lo cual zafa para monitoreo básico sin necesidad de armar toda una infraestructura de observabilidad propia.
Para automatización más avanzada: webhooks que disparan acciones correctivas cuando se supera un umbral (escalar recursos, reiniciar un servicio específico, notificar por Slack). El objetivo no es que el equipo duerma menos sino que el sistema sea capaz de auto-gestionar los problemas conocidos.
Mejores prácticas para salud a largo plazo
Auditoría de hardware cada 6 meses. Suena aburrido hasta que un disco con sectores defectuosos te corrompe la base de datos en producción.
Los discos duros mecánicos tienen una vida útil típica de 3-5 años bajo uso intensivo. Los SSDs duran más pero tienen límites de escritura que en ambientes de alta carga se alcanzan antes de lo esperado. Revisá el SMART status de tus discos regularmente.
ManageEngine identifica como mejores prácticas para salud de servidores: backups locales y fuera del sitio (los locales solos no cuentan), revisión continua de configuración según crecimiento de datos, y auditorías de seguridad que prevengan corrupción por malware. Este último punto lo subestima mucha gente: el ransomware y algunos tipos de malware pueden corromper datos silenciosamente antes de que te des cuenta.
Un cambio de configuración en staging antes de producción. Siempre. Sin excepciones. Cubrimos ese tema en detalle en expandir a múltiples regiones.
Caso de estudio: Treasure Hunt Engine en Veltrix, desarmado paso a paso
El análisis publicado en mayo de 2026 detalla tres problemas estructurales que el equipo de Veltrix tuvo que resolver desde cero:
Primero: múltiples instancias del motor corriendo sin coordinación. Cada instancia asumía que tenía acceso exclusivo a ciertos recursos, lo cual generaba condiciones de carrera en escrituras a disco y en memoria compartida.
Segundo: ausencia de mapeo de interdependencias. Nadie había documentado qué componente dependía de cuál, entonces cuando fallaba uno (por el motivo que fuera), la cascada de fallos era impredecible y difícil de diagnosticar.
Tercero: el monitoreo existente medía el estado de cada componente de forma aislada. Memoria del componente A: OK. CPU del componente B: OK. Pero nadie miraba qué pasaba cuando A y B interactuaban bajo carga simultánea.
La solución no fue agregar más recursos ni cambiar el proveedor. Fue replantear la arquitectura de monitoreo para capturar métricas de las interacciones entre componentes, definir parámetros basados en carga medida (no en recomendaciones genéricas), y establecer límites explícitos para cada proceso. Después de eso, los crashes desaparecieron (que no es poco, dado el historial).
Comparativa de herramientas de monitoreo de salud de servidor
| Herramienta | Tipo | Mejor para | Costo aprox. | Curva de aprendizaje |
|---|---|---|---|---|
| Prometheus + Grafana | Open source | Métricas con visualización personalizada | Infraestructura propia | Alta |
| Datadog | SaaS | Observabilidad completa con correlación automática | USD 15-23/host/mes | Media |
| Zabbix | Open source | Monitoreo de red e infraestructura clásico | Infraestructura propia | Alta |
| Netdata | Open source / SaaS | Métricas en tiempo real con bajo overhead | Gratis (on-premise) | Baja |
| ManageEngine OpManager | Licencia | Entornos corporativos con múltiples dispositivos | Desde USD 245/año | Media |
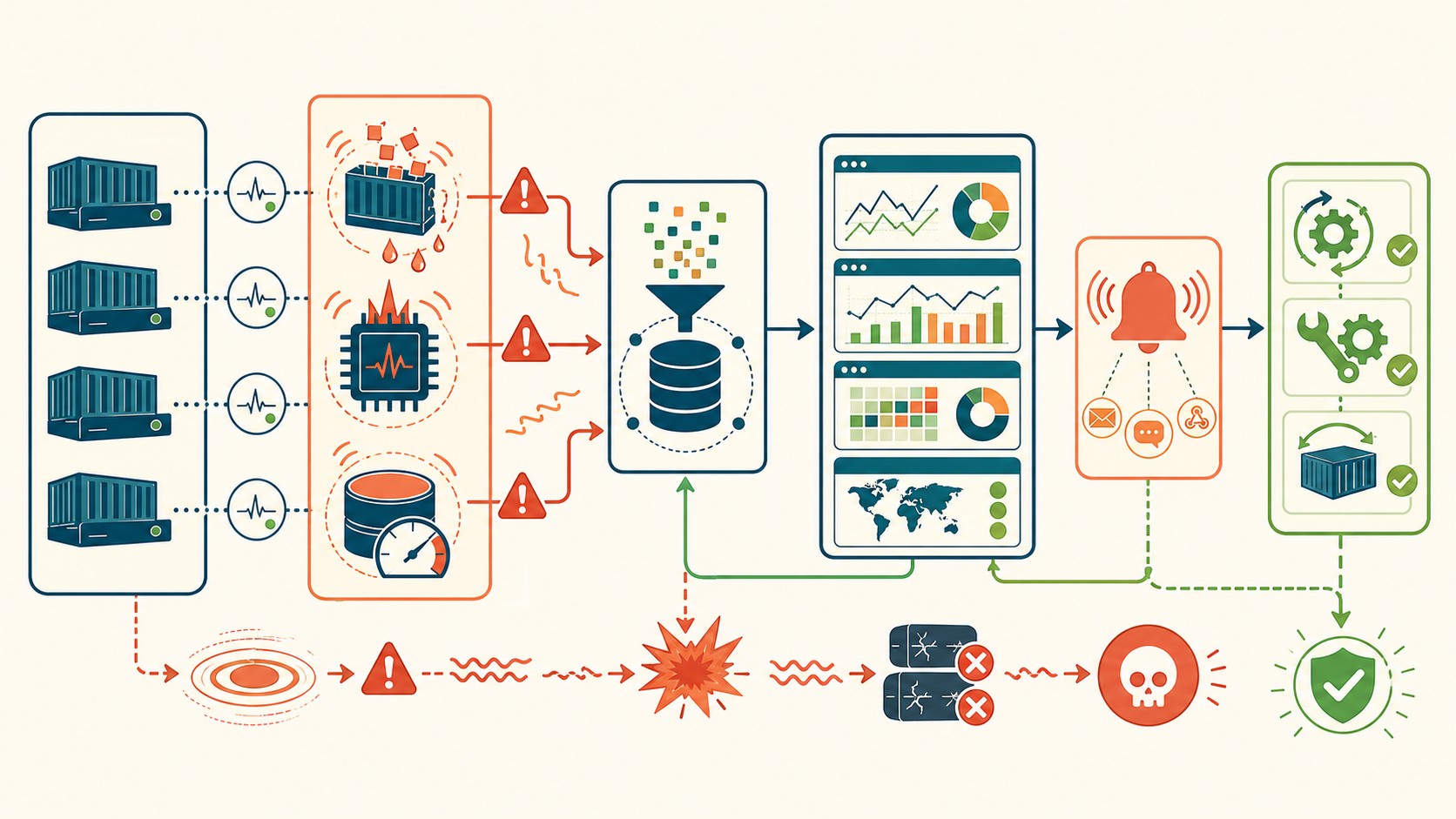
Errores comunes que llevan a crashes evitables
Confiar en los valores por defecto de la JVM
Sin -Xms y -Xmx configurados, la JVM toma entre el 25% y el 50% de la RAM del sistema como heap máximo. En un servidor compartido o con múltiples procesos Java, esto puede generar que dos procesos compitan por la misma memoria. Definí límites explícitos siempre. Para más detalles técnicos, mirá ejecutar procesos sin dependencias externas.
Tratar las alertas de disco como problema de espacio y no de I/O
Cuando aparece “disk space exceeded”, el reflejo es agregar más disco. Pero muchas veces el problema real es latencia de I/O por discos fragmentados, procesos de log sin rotación, o archivos temporales que no se limpian. Revisá el throughput y la latencia antes de escalar el almacenamiento.
No probar cambios de configuración bajo carga real
Cambiar parámetros de memoria o CPU en staging con tráfico sintético de 10 usuarios no te dice nada de cómo va a comportarse bajo 500 usuarios concurrentes con patrones de uso reales. Herramientas como k6 o Locust para generar carga realista antes de cualquier cambio de configuración en producción.
Asumir que el monitoreo existente cubre interdependencias
Prometheus monitorea instancias. No monitorea automáticamente qué pasa cuando la instancia A llama a la instancia B y B está degradada. Para eso necesitás trazabilidad distribuida o al menos métricas de latencia inter-servicio.
Para profundizar en esto, mirá Treasure Hunt Engine Was A Ticking Time Bomb Until We Rethou.
Esto se relaciona con Treasure Hunt Engine Was A Ticking Time Bomb Until We Rethou, donde lo explicamos al detalle.
Si querés profundizar, tenemos más detalles en nuestro artículo sobre Salud del servidor.
Preguntas Frecuentes
¿Cómo monitorear la salud de mi servidor en tiempo real?
Prometheus con exporters específicos (node_exporter para Linux, windows_exporter para Windows) recolecta métricas de CPU, memoria, disco y red cada 15 segundos por defecto. Grafana las visualiza en dashboards. Para empezar sin infraestructura propia, Netdata tiene instalación en un comando y muestra métricas en tiempo real desde el navegador sin configuración adicional.
¿Cómo prevenir crashes y errores OutOfMemoryError?
Definí límites explícitos de heap para procesos Java (-Xms512m -Xmx2g según tu RAM disponible) y configurá alertas antes de que el uso supere el 80% sostenido por más de 5 minutos. Revisá los logs de garbage collection para detectar si el GC está corriendo con demasiada frecuencia, señal de que el heap configurado es insuficiente para la carga real.
¿Cuál es la configuración correcta para evitar corrupción de datos?
No existe una configuración universal, pero hay tres medidas que aplican a casi todos los sistemas: backups automáticos con verificación de integridad (no solo copiar archivos sino verificar que se restauran), journaling activado en el filesystem, y shutdown graceful en vez de kill forzado para procesos críticos. La corrupción más frecuente viene de escrituras interrumpidas, no de hardware defectuoso.
¿Por qué la configuración recomendada del proveedor no funciona para mi sistema?
Las configuraciones recomendadas se basan en cargas típicas para el caso de uso más común. Si tu arquitectura tiene múltiples instancias coordinadas, picos de carga irregulares, o componentes con dependencias no estándar, los parámetros genéricos no contemplan esas variaciones. El punto de partida es la documentación; el punto de llegada son los parámetros ajustados a tu carga medida en producción.
¿Qué herramientas necesito para un monitoreo básico pero efectivo?
Para un setup mínimo viable: Prometheus para recolección, Grafana para visualización, y Alertmanager para notificaciones por email o Slack. Todo open source, desplegable en un servidor pequeño. Si preferís evitar el mantenimiento de la infraestructura de monitoreo, Netdata Cloud tiene un plan gratuito que cubre hasta algunos nodos con retención de 14 días de historial.
Conclusión
El caso del Treasure Hunt Engine en Veltrix es un buen ejemplo de algo que se repite constantemente en sistemas en producción: el problema no era el hardware ni el proveedor, era la brecha entre la configuración genérica y los requisitos específicos del sistema. Esa brecha solo se cierra midiendo el comportamiento real bajo carga real.
Si corrés aplicaciones en servidores propios o VPS, el camino es el mismo: instalá monitoreo granular antes de que aparezcan los problemas, definí límites explícitos para cada proceso, y configurá alertas que tengan contexto. Un servidor que nadie monitorea es una bomba de tiempo con el timer en modo silencioso.
Fuentes
- Dev.to — Treasure Hunt Engine: análisis completo del caso Veltrix (2026)
- Whitestack — Cómo implementar Prometheus y Grafana para observabilidad
- ManageEngine — Mejores prácticas de monitoreo de salud de servidores
- Geekflare — Causas y prevención de corrupción de datos en servidores
- Microsoft Learn — Gestión de caché y memoria en Windows Server