254 errores de GitHub Actions en una base consultable por IA
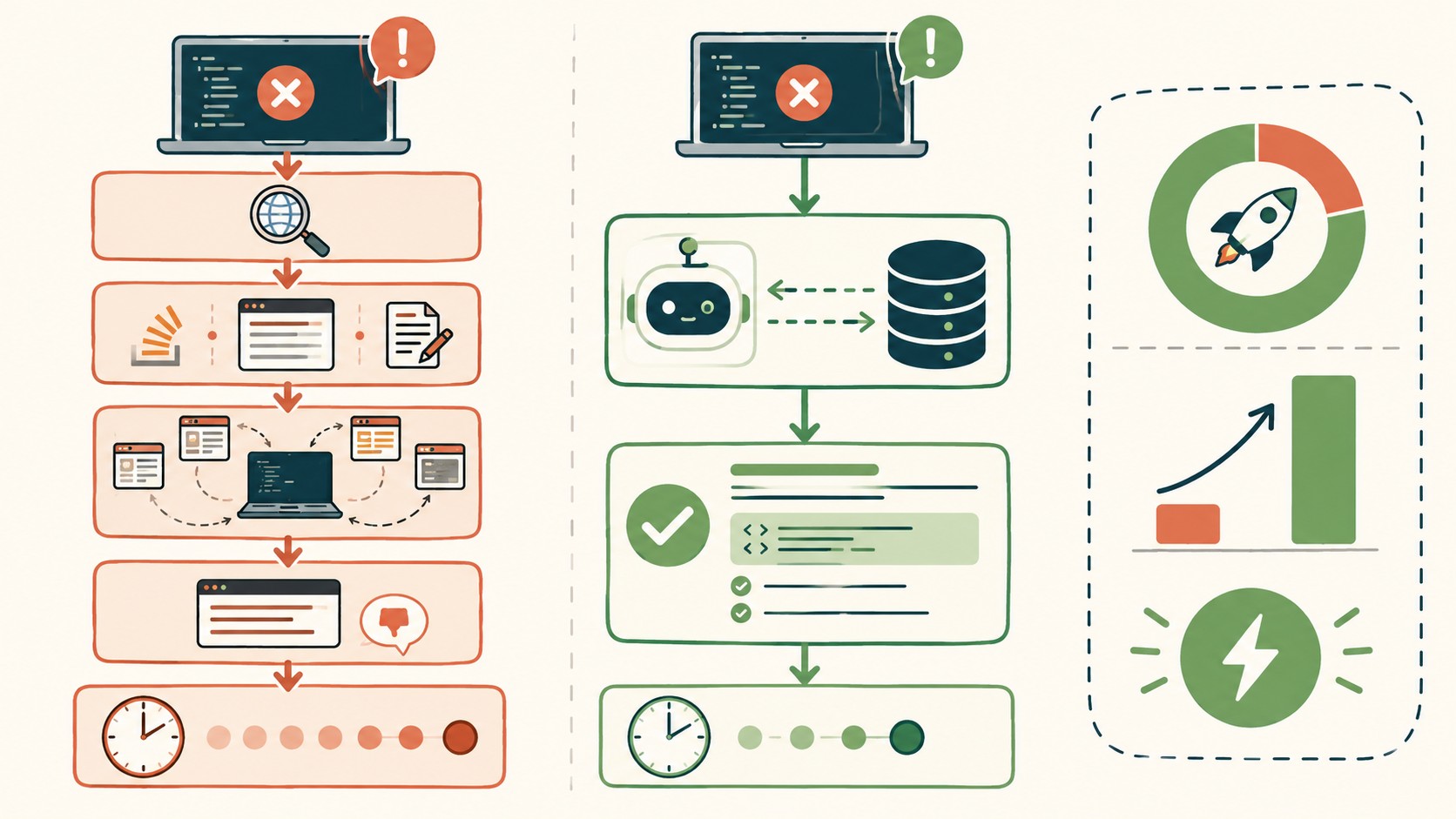
Un dev rompe un workflow de GitHub Actions, le salta un error críptico y se pasa 45 minutos buscando en Google antes de tocarle el hombro al único que ya lo vio antes. Esa escena se repite en casi todos los equipos. La idea detrás de cómo transformé 65+ fallos de GitHub Actions en una base de datos consultable por IA ataca justo ese punto: documentar 254 errores estructurados que tanto personas como agentes puedan consultar sin salir a rastrear internet.
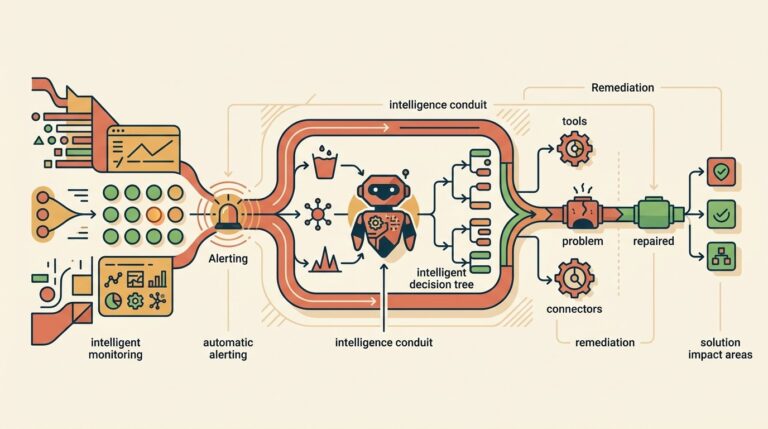
Una base de datos queryable de errores CI/CD es un repositorio estructurado de fallos conocidos, cada uno con su categoría, causa raíz y fix verificado, accesible por consulta directa desde herramientas, agentes de IA o paquetes de código. No es un blog: es data tabulada que una máquina filtra por mensaje de error o por intención de arreglo, sin parsear texto narrativo ni adivinar.
En 30 segundos
- 254 errores estructurados repartidos en ocho categorías, consultables vía MCP, skills de Copilot CLI o un paquete npm.
- El problema no era falta de docs, era descubribilidad bajo presión: a las 4 de la tarde de un viernes nadie navega tranquilo una guía de referencia.
- Un agente de IA quema tokens buscando contexto en internet; con una base local resuelve el fallo sin ese ruido.
- El origen fue una guía de 65+ escenarios de error que se volvió referencia, pero los equipos seguían trabados igual.
- Replicarlo lleva 5 fases: juntar errores reales, categorizar, documentar el fix, estructurar en JSON/SQLite y exponer por API o CLI.
Claude es un modelo de lenguaje grande desarrollado por Anthropic, diseñado para asistir en análisis, escritura, programación y resolución de problemas. Puede procesar consultas complejas y generar respuestas contextuales.
¿Por qué tu equipo pierde 45 minutos en cada error de GitHub Actions?
Ponele que estás por hacer deploy un viernes a las 4 de la tarde. El pipeline se rompe, te tira un error de permisos que nunca viste, y arranca el ritual: copiás el mensaje, lo pegás en el buscador y rezás para que aparezca una respuesta de Stack Overflow de 2023 que todavía aplique.
El autor del artículo original lo describe sin vueltas: en todos los equipos donde trabajó hay una misma persona que se convirtió en el silo de conocimiento tribal para fallos de CI. Cuando esa persona no está, el equipo queda trabado. Y el costo no es solo tiempo. Es deployment bloqueado, ventana de release perdida y un dev frustrado pingueando a otro que tampoco quería que lo interrumpan. Relacionado: en nuestra comparativa de plataformas CI/CD.
El tema es que el problema no era falta de documentación. El propio autor ya había publicado una guía con más de 65 escenarios de error, con causa raíz y fix, que se compartió un montón. Y aún así los equipos seguían sufriendo. ¿Por qué? La doc estaba, pero nadie la encontraba en el momento exacto en que la necesitaba.
Qué es una base de datos queryable de errores CI/CD (y por qué no basta un blog)
Un blog está hecho para que lo lea una persona, de arriba a abajo, con tiempo. Una base de datos estructurada está hecha para que la consulten máquinas Y personas, por consulta puntual.
La diferencia práctica es la descubribilidad bajo presión. Con un blog tenés que saber qué buscar, abrirlo, scrollear y leer hasta dar con tu caso. Con una base queryable hacés una consulta concreta (por categoría, por fragmento del mensaje de error, o por la intención del fix) y te devuelve el registro exacto. Según el artículo original en dev.to, el resultado fueron 254 entradas estructuradas, cada una pensada para responder a una consulta, no para que la leas como nota.
Acá viene lo bueno: la misma data sirve para tres consumidores distintos sin reescribirla. Un dev la abre desde la terminal. Un agente de IA la consulta como herramienta. Un sistema de alertas la cruza automáticamente cuando detecta un fallo conocido.
Cómo se categorizaron los 254 errores en ocho grupos base
La estructura es lo que hace consultable a la cosa. Sin categorías no hay filtrado automático ni detección de patrones. El artículo agrupó los errores en ocho categorías, que en la práctica de GitHub Actions suelen ser estas: En al elegir tu plataforma de automatización profundizamos sobre esto.
- Permisos y secretos: tokens sin scope, secrets mal referenciados, permisos de workflow insuficientes.
- Dependencias: versiones que cambiaron, lockfiles desactualizados, instalaciones que fallan en el runner.
- Timeouts: jobs que se cuelgan, steps que superan el límite, esperas que nunca resuelven.
- Sintaxis YAML: indentación rota, claves mal escritas, expresiones que no evalúan.
- Red: endpoints caídos, rate limits, descargas que no llegan.
- Runners: imágenes que cambiaron, herramientas que ya no vienen preinstaladas, diferencias entre local y CI.
- Versiones de actions: una action que pasó de v3 a v4 y te rompió el pipeline sin avisar.
- Matrix builds: combinaciones que fallan solo en una variante del matrix.
¿Por qué importa tanto la categoría? Porque permite que la IA filtre antes de leer, que descubras patrones (capaz el 30% de tus fallos son de un solo grupo) y que el nuevo del equipo entienda el mapa sin tener que vivir cada error en carne propia.
¿Cuáles son las herramientas para consultar y mantener la base?
El proyecto expone la misma data por tres interfaces, según el artículo. Cada una apunta a un usuario distinto.
| Interfaz | Para quién | Caso de uso |
|---|---|---|
| MCP tools | Agentes de IA | El agente consulta la base como herramienta nativa, sin salir a internet |
| Skills de Copilot CLI | Devs en terminal | Consulta directa desde la línea de comandos mientras debuggeás |
| Paquete npm | Sistemas CI/CD | Acceso programático desde scripts, alertas o el propio pipeline |
La gracia es que no tenés que elegir una sola. La data vive en un lugar y cada interfaz la lee. Si mañana querés sumar un cuarto consumidor, no reescribís nada: agregás otra capa de acceso sobre la misma estructura.
Cómo un agente de IA usa la base para resolver fallos solo
Acá está el punto que más me cierra del problema. Cuando un agente de codeo se topa con un fallo de CI y no tiene la data a mano, hace lo peor: sale a buscar contexto en internet, quema tokens leyendo blogs, respuestas viejas y resultados irrelevantes. La relación señal-ruido es pésima, como dice el propio autor. Cubrimos ese tema en detalle en con los últimos modelos de lenguaje.
Con la base local el flujo es otro. El agente lee el error, consulta la base estructurada filtrando por categoría o por mensaje, encuentra la causa raíz con el fix verificado y lo aplica. Sin tokens gastados en ruido, sin contexto desactualizado, todo local y preciso.
La diferencia es directa: en vez de un agente que adivina entre veinte resultados de un buscador, tenés uno que consulta una fuente curada de 254 casos reales. ¿Cuál te genera más confianza? Exacto.
Pasos prácticos para armar tu propia base en 5 fases
No necesitás 254 entradas para empezar. Con un mínimo viable ya bajás el tiempo de debugging. El camino, en cinco fases:
- Juntá tus últimos 50 errores reales: revisá los logs de GitHub Actions de los últimos meses y copiá los fallos que de verdad pasaron en tu equipo, no casos teóricos.
- Categorizá con causa raíz: a cada error asignale una de las ocho categorías y escribí por qué pasó, no solo qué decía el mensaje.
- Documentá el fix verificado: anotá la solución que funcionó de verdad, probada, no la que “debería andar”.
- Estructurá la data: arrancá con un JSON o un SQLite. Si crece, migrás a PostgreSQL. Lo importante es que cada entrada tenga categoría, mensaje, causa y fix.
- Exponé el acceso: una API REST o un CLI mínimo para consultar. Después le sumás MCP para que tus agentes la lean.
Si tu pipeline corre sobre infraestructura propia o un VPS, tener esta base cerca del entorno de deploy te ahorra ida y vuelta. Para hosting y servidores en Argentina, donweb.com es una opción para alojar tanto el runner como el repo de la base.
Qué cambia para equipos en Latinoamérica
El valor concreto se mide en MTTR (mean time to resolution), el tiempo promedio que tardás en resolver un fallo. El caso del artículo apunta a bajar el debugging de 45 minutos a unos pocos, porque la respuesta ya está escrita y categorizada. Esto se conecta con lo que analizamos en entre las herramientas de IA actuales.
Para un equipo chico argentino o de la región, el beneficio más grande no es ni siquiera la velocidad. Es sacarle la mochila al “experto” de CI. Cuando el conocimiento vive en una base y no en la cabeza de una persona, el onboarding de un dev nuevo se acelera, bajan los pings que interrumpen a medio equipo, y nadie queda bloqueado porque el que sabía está de vacaciones. Habría que ver cada caso, pero la lógica es sólida: documentar una vez, consultar muchas.
Revisá nuestro artículo How I Turned 65+ GitHub Actions Failures into an AI-Queryabl para más detalles.
Esto se conecta con How I Turned 65+ GitHub Actions Failures into an AI-Queryabl, donde profundizamos el tema.
Para ver cómo se estructura todo esto en la práctica, revisá nuestra base de datos consultable.
Errores comunes al armar una base de debugging
- Documentar el síntoma y no la causa: anotar “el job falló” no sirve. Tenés que registrar por qué falló, sino la base no resuelve nada.
- Meter fixes sin verificar: si cargás una solución que no probaste, contaminás la base con ruido. Un fix dudoso es peor que no tener entrada.
- No categorizar desde el inicio: si arrancás con texto libre sin categoría, después no podés filtrar ni dejar que la IA consulte bien. La estructura va desde la entrada uno.
- Dejar que envejezca: una action sube de versión, cambia el runner, y tu fix de hace seis meses ya no aplica. Sin mantenimiento, la base se vuelve otra fuente de contexto stale.
Preguntas Frecuentes
¿Qué es una base de datos queryable de errores de CI/CD?
Es un repositorio estructurado de fallos conocidos donde cada entrada tiene categoría, causa raíz y fix verificado, consultable por máquinas y personas. A diferencia de un blog, devuelve el registro exacto ante una consulta puntual en vez de obligarte a leer texto corrido.
¿Se puede usar IA para debuggear fallos de CI/CD automáticamente?
Sí. Un agente de IA lee el error, consulta la base estructurada vía MCP, encuentra la causa raíz y aplica el fix sin salir a internet. Eso evita que el agente queme tokens leyendo resultados irrelevantes de buscadores y reduce el contexto desactualizado a cero.
¿Cuántos errores y categorías tiene el proyecto original?
254 entradas estructuradas repartidas en ocho categorías, según el artículo publicado en dev.to en junio de 2026. Nació de una guía previa que documentaba más de 65 escenarios de error de GitHub Actions con causa raíz y solución.
¿Cómo evito que un solo dev sea el experto de GitHub Actions?
Documentando el conocimiento en una base consultable en vez de dejarlo en la cabeza de una persona. Cuando los fallos y sus fixes viven en data estructurada, cualquier dev (o agente) los consulta directo, y el onboarding del equipo deja de depender de una sola persona.
¿Con qué herramienta empiezo a armar la mía?
Con un JSON o un SQLite cargando tus últimos 50 errores reales, cada uno con categoría, causa y fix verificado. Después exponés el acceso por API o CLI, y más adelante le sumás MCP para que tus agentes de IA la consulten como herramienta nativa.
Conclusión
Lo que cambia acá no es la tecnología, es dónde vive el conocimiento. Pasar de 65+ escenarios sueltos en un blog a 254 errores estructurados y consultables resuelve el problema real: no la falta de docs, sino encontrarlas cuando el deploy se rompe un viernes a las 4.
Si tu equipo tiene un silo humano de conocimiento de CI, el camino es claro. Empezá chico: juntá tus últimos errores reales, categorizalos con causa raíz y fix verificado, metelos en un SQLite y exponé una consulta. Después escalás a MCP para que tus agentes la lean solos. La base no se arma de una; se llena cada vez que algo se rompe y vos lo documentás bien. Esa es la parte que ningún blog te resuelve.