Percona Operator PostgreSQL 3.0.0: que cambia con el hard
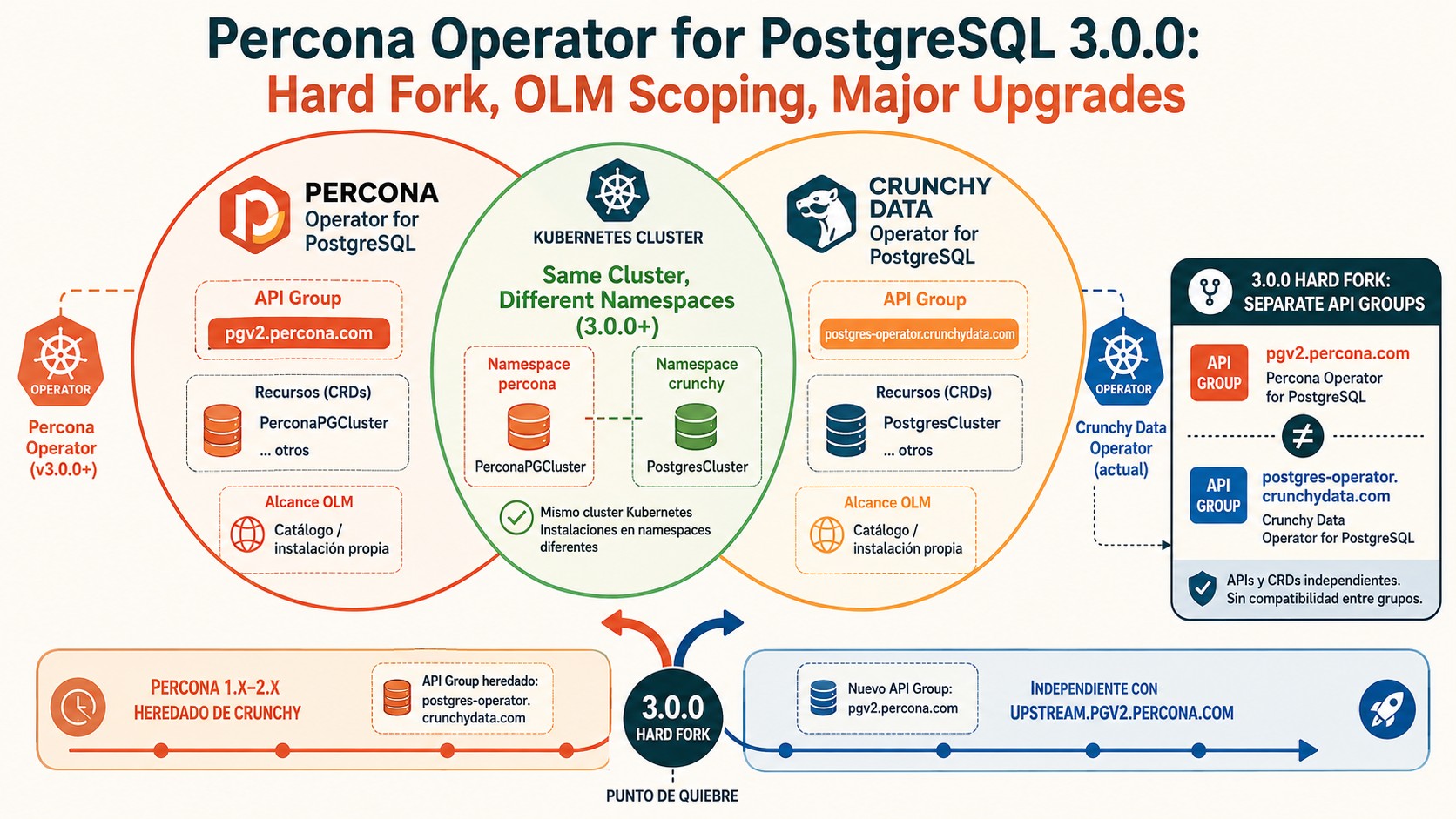
Percona lanzó Percona Operator for PostgreSQL 3.0.0 en mayo de 2026, la versión que completa el hard fork del operador heredado de Crunchy Data. Trae los CRDs renombrados bajo un grupo de API propio, permite que el operador de Crunchy y el de Percona convivan en el mismo clúster de Kubernetes, y arregla el scoping de namespaces para OpenShift.
Percona Operator for PostgreSQL es un operador de Kubernetes, mantenido por Percona, que automatiza el despliegue, el backup, el escalado y las actualizaciones de clústeres de PostgreSQL dentro de Kubernetes. La versión 3.0.0 es la primera totalmente independiente del Crunchy Data PostgreSQL Operator: usa el grupo de API propio upstream.pgv2.percona.com y deja atrás la herencia que arrastraban las ramas 1.x y 2.x.
En 30 segundos
- Hard fork completo: los CRDs ahora viven bajo
upstream.pgv2.percona.com, con renombrado automático al actualizar desde 2.x. - Coexistencia: el operador de Crunchy y el de Percona pueden correr en el mismo clúster, en namespaces distintos.
- OpenShift: el scoping de namespaces de OLM (single-namespace y all-namespaces) ahora funciona como corresponde.
- Upgrades de versión mayor: usan la imagen oficial de Percona Distribution for PostgreSQL, así las políticas de firma y escaneo de CVE aplican parejo.
¿Por qué 3.0.0 es un punto de quiebre y no una actualización más?
Hasta acá, el operador de Percona venía con una mochila. Las ramas 1.x y 2.x heredaban buena parte del Crunchy Data PostgreSQL Operator, incluyendo los CRDs y el grupo de API. Eso funcionaba, pero te ataba a decisiones que no controlabas del todo.
Un operador, por si recién entrás al tema, es el componente que mete la lógica de un DBA dentro de Kubernetes: vos declarás “quiero un clúster PostgreSQL con tres réplicas, backups a S3 y alta disponibilidad”, y el operador se encarga de crearlo, vigilarlo y repararlo. La versión 3.0.0 corta el cordón con Crunchy. Según el anuncio oficial de Percona, esta release “completa el hard fork” hacia un proyecto independiente con su propio upstream.
¿Qué cambia en la práctica? Tres cosas concretas, y ninguna es cosmética.
¿Qué es un hard fork y en qué se diferencia de un fork común?
Un fork normal es copiar el código de otro proyecto y seguir adelante por tu cuenta, pero manteniendo la compatibilidad y, muchas veces, sincronizando cambios del original. Un hard fork va más lejos: rompe la dependencia técnica de raíz. Renombrás las APIs, te quedás con tu propio espacio de nombres y dejás de compartir identidad con el proyecto padre. Esto se conecta con lo que analizamos en integración de APIs en aplicaciones.
Eso es lo que hizo Percona con Percona Operator PostgreSQL 3.0.0. El motivo de fondo es la libertad sobre las imágenes de contenedor. Al ser un proyecto propio, Percona puede definir qué binarios corren en tu clúster sin atarse al pipeline de otro. La contracara: si venías de 2.x, hay una migración de por medio. No es transparente del todo, aunque el operador automatiza la parte más delicada.
¿Cómo funciona el renombrado de CRDs bajo upstream.pgv2.percona.com?
Los CRDs (Custom Resource Definitions) son las extensiones que le enseñan a Kubernetes recursos nuevos, como un PerconaPGCluster. El problema histórico era que esos CRDs vivían en un grupo de API compartido con Crunchy. Si instalabas los dos operadores, chocaban. No había forma limpia de tenerlos juntos.
Con 3.0.0, los CRDs heredados pasan al grupo upstream.pgv2.percona.com, que es territorio Percona. Y acá viene lo bueno: para las instalaciones 2.x existentes, el renombrado se aplica solo durante la actualización. No tenés que reescribir tus manifiestos a mano (que era el escenario de pesadilla que todos imaginábamos).
El beneficio directo es la coexistencia. Antes, instalar ambos operadores era pedir un conflicto de CRDs. Ahora se puede, con una condición clara. Cubrimos ese tema en detalle en pipelines de CI/CD modernos.
¿Puedo usar Percona Operator y Crunchy operator en el mismo clúster?
Sí, desde 3.0.0. La única restricción es que cada uno tiene que vivir en su propio namespace. Ponele que estás migrando de Crunchy a Percona y no querés hacerlo de un día para el otro: ahora podés correr los dos en paralelo, ir moviendo clústeres de a poco y validar antes de apagar el viejo.
| Escenario | Antes de 3.0.0 | Desde 3.0.0 |
|---|---|---|
| Crunchy + Percona en el mismo clúster | No (conflicto de CRDs) | Sí, en namespaces distintos |
| Grupo de API de los CRDs | Heredado de Crunchy | upstream.pgv2.percona.com |
| Migración gradual entre operadores | Compleja | Posible, clúster por clúster |
| Imagen para upgrades de versión mayor | Distinta al runtime | Percona Distribution (misma familia) |
Esto le sirve a cualquiera que tenga multitenancy o que esté evaluando dejar Crunchy sin un corte abrupto. Migrar bases de datos productivas siempre da nervios. Tener un período de convivencia baja bastante esa presión.
¿Qué mejora el nuevo scoping de namespaces en OpenShift?
OLM (Operator Lifecycle Manager) es el sistema de OpenShift que instala y actualiza operadores. Tenía un comportamiento medio caprichoso con el scoping: los modos all-namespaces y single-namespace no siempre respetaban lo que vos configurabas. Un dolor de cabeza para administradores que querían acotar permisos.
La 3.0.0 arregla eso: ambos modos ahora honran el scoping correctamente. Ojo con un detalle operativo. Según la documentación de Percona, quienes usan el certified bundle en el canal viejo tienen que cambiarse al canal nuevo para recibir esta actualización. Si no lo hacés, te quedás esperando un upgrade que nunca llega. Relacionado: alternativas cloud para PostgreSQL.
¿Por qué las actualizaciones mayores ahora usan la imagen de Percona Distribution?
Antes había una rareza: la imagen que corría tu PostgreSQL en runtime no era la misma que se usaba para actualizar de una versión mayor a otra. Dos binarios distintos, dos cadenas de confianza distintas. Si tu política de seguridad exigía firma de imágenes y escaneo de CVE, tenías un hueco justo en el momento más sensible.
Con 3.0.0, los upgrades de versión mayor usan la familia percona-distribution-postgresql, la misma que ya corre en tus clústeres. Resultado: las políticas de firma y de escaneo de vulnerabilidades aplican parejo en runtime y en actualización. Para equipos que viven bajo auditorías de seguridad, esto no es un detalle menor.
¿Cómo encaro la migración de 2.x a 3.0.0?
El renombrado de CRDs es automático en el upgrade, así que la parte más temida está cubierta por el operador. Dicho esto, una migración de versión mayor de un operador de base de datos no se hace a las apuradas un viernes a la tarde.
Antes de tocar producción, revisá los requisitos y el path de actualización en la documentación oficial, porque las versiones de origen soportadas, el manejo de certificados y los objetos dependientes (Secrets, finalizers) pueden cambiar entre releases menores. Probalo primero en un entorno de staging que replique tu setup. Si corrés tus clústeres on-premise o sobre un servidor cloud en donweb.com, validá ahí el flujo completo antes de mover las bases reales.
Mirá, si querés saber más, acá está nuestro artículo sobre Percona Operator for PostgreSQL 3.0.0: Hard Fork, OLM Scopin.
Mirá nuestro artículo sobre Percona Operator for PostgreSQL 3.0.0: Hard Fork, OLM Scopin para profundizar en el tema.
Errores comunes al actualizar a Percona Operator 3.0.0
- Quedarse en el canal viejo de OLM. Si usás el certified bundle en OpenShift y no cambiás al canal nuevo, el upgrade a 3.0.0 directamente no aparece. No es un bug, es el canal.
- Asumir que el renombrado de CRDs hay que hacerlo a mano. El operador lo aplica solo en la actualización desde 2.x. Editar los CRDs por tu cuenta antes de tiempo es la mejor forma de romper algo que ya estaba resuelto.
- Instalar Percona y Crunchy en el mismo namespace. La coexistencia funciona, pero cada operador necesita su propio namespace. Meterlos juntos te devuelve al conflicto que 3.0.0 vino a solucionar.
- Saltarse el staging. Es una versión mayor. Probar el upgrade directo en producción, sin un ensayo previo, es jugar con fuego en algo que guarda tus datos.
Preguntas Frecuentes
¿Qué cambios principales trae Percona Operator for PostgreSQL 3.0.0?
Tres cambios de peso: el renombrado de los CRDs bajo el grupo de API upstream.pgv2.percona.com, el scoping correcto de namespaces en OLM para OpenShift, y el uso de la imagen oficial de Percona Distribution para las actualizaciones de versión mayor de PostgreSQL. Todos apuntan a cerrar el hard fork respecto de Crunchy Data. Complementá con herramientas de orquestación de deployments.
¿Puedo tener Percona y Crunchy operator en el mismo clúster?
Sí, desde la versión 3.0.0, siempre que cada operador esté en un namespace distinto. Antes era imposible por el conflicto de CRDs. El renombrado al grupo upstream.pgv2.percona.com es lo que habilita esta convivencia.
¿Qué significa que sea un hard fork?
Significa que Percona Operator dejó de depender técnicamente del Crunchy Data PostgreSQL Operator. Renombró sus APIs, se quedó con su propio upstream y ya no comparte grupo de API con el proyecto original. Es una separación de raíz, no un simple fork que sigue sincronizado.
¿El renombrado de CRDs lo tengo que hacer a mano?
No. Para las instalaciones 2.x existentes, el renombrado de CRDs se aplica de forma automática durante la actualización a 3.0.0. No necesitás reescribir tus manifiestos manualmente.
¿Por qué los upgrades ahora usan la imagen de Percona Distribution?
Para que las políticas de seguridad apliquen igual en runtime y en actualización. Antes la imagen de upgrade era distinta a la de runtime, lo que dejaba un hueco en firma de imágenes y escaneo de CVE. Con la familia percona-distribution-postgresql, el mismo binario corre y actualiza.
Conclusión
La 3.0.0 no es relleno de changelog. Es la versión donde Percona Operator for PostgreSQL deja de ser un derivado de Crunchy y pasa a ser un proyecto con identidad propia. El renombrado de CRDs habilita algo que mucha gente venía pidiendo (correr ambos operadores en paralelo), el scoping de OLM destraba a los equipos de OpenShift, y la unificación de imágenes cierra un agujero de seguridad real en los upgrades.
¿Qué hacer ahora? Si estás en 2.x, leé el path de actualización en la doc oficial y ensayalo en staging antes de tocar producción. Si usás el certified bundle, cambiate al canal nuevo o el upgrade no te va a llegar. Y si venías evaluando dejar Crunchy, la convivencia de 3.0.0 te da la salida gradual que antes no existía.